









The thief has found himself a new place for his thievery again. There is only one entrance to this area, called the "root." Besides the root, each house has one and only one parent house. After a tour, the smart thief realized that "all houses in this place forms a binary tree". It will automatically contact the police if two directly-linked houses were broken into on the same night.
Determine the maximum amount of money the thief can rob tonight without alerting the police.
Example 1:
3 / \ 2 3 \ \ 3 1Maximum amount of money the thief can rob = 3 + 3 + 1 = 7 .
Example 2:
3
/ \
4 5
/ \ \
1 3 1
Maximum amount of money the thief can rob =
4
+
5
=
9
.
这一题还需要看几个例子。
例子三:

结果是4+3,所以rob不一定是隔一层相加,还有可能隔n层。
例子四:
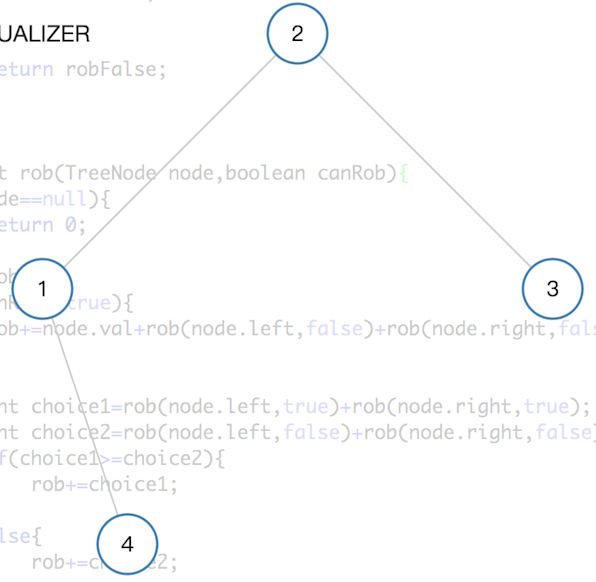
结果是3+4,说明root不用,不一定root的子结点都要用。
因此写出递归解答。如果当前结点被使用了,那么递归时它的子结点一定不能用。如果当前结点没被使用,那么递归时它的子结点可以用,可以不用,看哪种偷得最多 就选哪种。
如果只是单纯的这样递归,会TLE。因此想到,在递归时会出现很多重复的情形。
比如在例子4中:
max(2)=max(use(2),noUse(2))
use(2)= noUse(1)+noUse(3)
noUse(2)= max(use(1),noUse(1))+ max(use(3),noUse(3)。
这里已经能看出noUse(1)和noUse(3)都要被重复计算了。
因此使用mapTrue数组来记录use(node),即储存在当前node要用的情况下的最大偷盗值,使用mapFalse数组来记录noUse(node),即储存在当前node不用的情况下的最大偷盗值。
package leetcode;
import java.util.HashMap;
public class House_Robber_III_337 {
public int rob(TreeNode root) {
HashMap<TreeNode,Integer> mapT=new HashMap<TreeNode,Integer>();
HashMap<TreeNode,Integer> mapF=new HashMap<TreeNode,Integer>();
int robTrue=rob(root,true,mapT,mapF);
int robFalse=rob(root, false,mapT,mapF);
if(robTrue>=robFalse){
return robTrue;
}
else{
return robFalse;
}
}
public int rob(TreeNode node,boolean canRob,
HashMap<TreeNode,Integer> mapT,HashMap<TreeNode,Integer> mapF){
if(node==null){
return 0;
}
if(canRob==true){
if(mapT.get(node)!=null){
return mapT.get(node);
}
int rob=node.val+rob(node.left,false,mapT,mapF)+
rob(node.right,false,mapT,mapF);
mapT.put(node, rob);
return rob;
}
else{
if(mapF.get(node)!=null){
return mapF.get(node);
}
int leftMax=Math.max(rob(node.left,true,mapT,mapF),
rob(node.left,false,mapT,mapF));
int rightMax=Math.max(rob(node.right,true,mapT,mapF),
rob(node.right,false,mapT,mapF));
int rob=(leftMax+rightMax);
mapF.put(node, rob);
return rob;
}
}
public static void main(String[] args) {
// TODO Auto-generated method stub
House_Robber_III_337 h=new House_Robber_III_337();
TreeNode root=new TreeNode(2);
root.left=new TreeNode(1);
root.right=new TreeNode(3);
root.left.right=new TreeNode(4);
System.out.println(h.rob(root));
}
}















 409
409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









