






题目

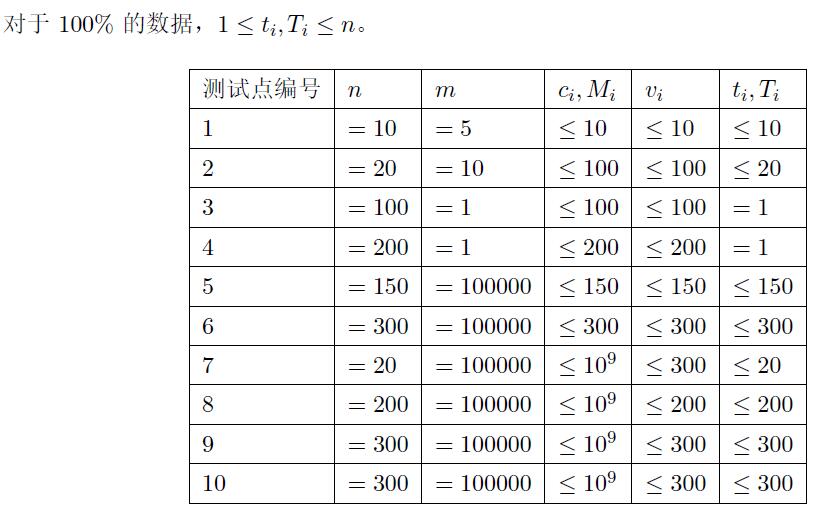
数据范围
题解
我们二分答案,假设答案为mid,设
fi
表示装i价值所需的容量,
gi
表示
min(fi)
,
判断
gmid
是否小于等于
M
<script type="math/tex" id="MathJax-Element-178">M</script>即可。
我们离线做,这样就可以将店铺开张与Byteasar到达商店的时间的问题简化。
代码
#include<iostream>
#include<cstdio>
#include<cstring>
#include<cmath>
#include<algorithm>
#define N 100010
#define LL long long
#define fo(i,a,b) for(i=a;i<=b;i++)
#define fd(i,a,b) for(i=a;i>=b;i--)
using namespace std;
struct note
{
LL c,v,t;
};note a[N];
struct note1
{
LL T,M,w;
};note1 b[N];
LL i,j,k,l,r,mid,n,m,lm,ans[N],_2[22],f[N];
bool v[N];
bool cmp(note x,note y){return x.t<y.t;}
bool cmp1(note1 x,note1 y){return x.T<y.T;}
int main()
{
freopen("market.in","r",stdin);
freopen("market.out","w",stdout);
_2[1]=1;
fo(i,2,20) _2[i]=_2[i-1]*2;
scanf("%lld%lld",&n,&m);
fo(i,1,n)
{
scanf("%lld%lld%lld",&a[i].c,&a[i].v,&a[i].t);
lm=max(a[i].v,lm);
}
lm*=n;
fo(i,1,m)
{
scanf("%lld%lld",&b[i].T,&b[i].M);
b[i].w=i;
}
sort(a+1,a+n+1,cmp);
sort(b+1,b+m+1,cmp1);
memset(f,127,sizeof(f));
f[0]=0;
j=1;
fo(i,1,m)
{
while (j<=n && a[j].t<=b[i].T)
{
fd(k,lm,a[j].v)
f[k]=min(f[k],f[k-a[j].v]+a[j].c);
fd(k,lm-1,1)f[k]=min(f[k+1],f[k]);
j++;
}
LL temp;
l=0;r=lm;
while (l<=r)
{
mid=(l+r)/2;
if (f[mid]<=b[i].M) temp=mid,l=mid+1;
else r=mid-1;
}
ans[b[i].w]=temp;
}
fo(i,1,m) printf("%lld\n",ans[i]);
}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









