






循环神经网络的介绍
引言
循环神经网络(RNN)是深度学习中比较流行的模型,特别是在自然语言处理领域(NLP)中有着显著的贡献。而在自然语言处理领域中,一个非常重要的概念就是语言模型(language model)。语言模型的应用主要体现在两个方面:
第一就是我们可以根据语言模型计算出一个句子可能会在真实世界出现的概率,通过这样的方式,我们就可以在给定任意句子的情况下,测量句子的语法和语义的准确性。这样一个应用在机器翻译系统中就可以体现出来了。
而第二个应用就是,语言模型允许我们生成新的文本。例如,如果我们使用Shakespeare的著作来训练一个语言模型的话,我们就能够生成具有Shakespeare著作特点的文本。
语言模型
根据上面的描述,建立循环神经网络的其中一个目标就是要建立一个语言模型。所谓的语言模型其实就是,给定一个有
m
个单词的句子,语言模型通过以下的公式计算出在一个给定数据集的情况下,这个句子出现的概率是多少。
这样一个公式的意思是,一个句子的概率是通过给定每一个单词前面所有单词的情况下,计算句子中每一个单词的条件概率的乘积。这样一个模型可以被当成是一个评分机制(scoring mechanism)。例如,一个机器翻译系统的工作原理通常是对一个输入句子,系统生成多个候选的句子,这个情况下我们就可以使用语言模型来给这些句子进行评分,从而得到在现实世界中最有可能出现的句子,也就是说这个句子最满足语法和语义准确性的。
另一方面,如果我们能够在给定一个句子之前的所有单词的情况下预测下一个单词的概率的话,我们就可以用这样一个机制来生成新的文本,这就是所谓的生成模型。
从语言模型的概率形式我们可以知道,每一个单词概率的计算都需要以其之前所有的单词为条件的,这样一个长期的依赖(long-term dependencies)在实际上是很难满足的,因为要维护这样长的依赖需要大量的计算和存储开销。因此,在实际的实现过程中往往只回顾之前的几个单词,而不是所有单词,尽管RNN从理论上可以捕捉这样一个长期的依赖,但是实现起来也是非常复杂的。
RNN的基本原理
RNN背后的原理其实就是要用到数据中的序列信息(sequential information)。在传统的神经网络中,我们是假定所有的输入(和输出)都是相互独立的,但是在很多的领域应用里面,这样的假定本来就不成立的,例如在NLP中,我们要想预测一个句子中下一个单词是什么,我们最好是要知道这个单词前面有什么单词。循环神经网络之所以叫循环,是因为它对于序列中的每一个元素(例如句子中的每一个单词)都进行相同的处理任务,而且每一个处理任务的输出都是依赖于之前的计算的。
另一方面,我们也可以把RNN看成是一个捕捉它之前所进行的所有计算的“存储模型”。从理论上,RNN可以使用具有任意长度的序列的信息,但是实际上,由于计算复杂度以及存储空间的问题,我们只让RNN捕捉前几个时刻的信息。
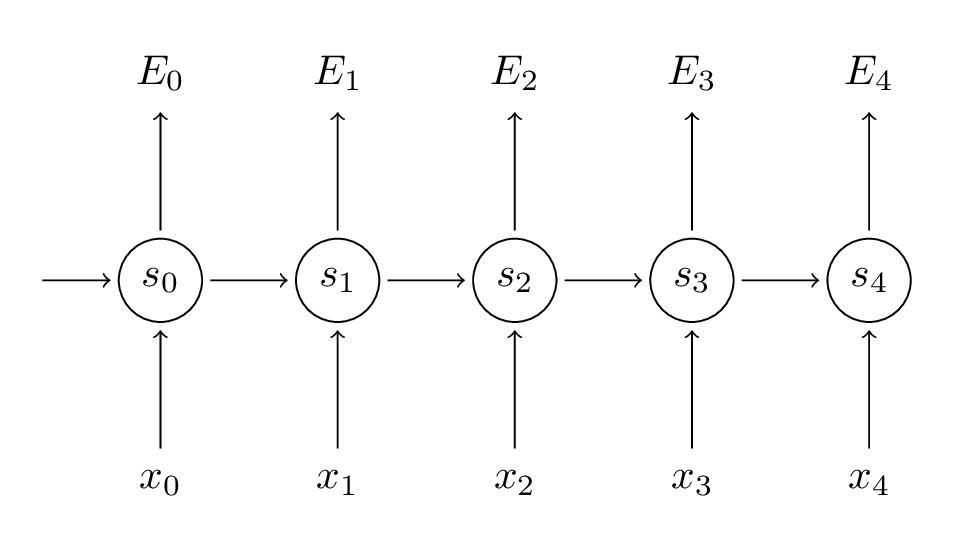
下面的图就是RNN按照每一个时刻展开的网络图。

①
xt
表示的是在
t
时刻的输入。每一个时刻的输入都是序列中一个元素,例如语言模型中,每一个时刻的输入是句子中的一个单词,这个单词是用词向量的形式来表示的,因此输入是仅包含一个单词的词向量。
②
③
ot
表示的是时刻
t
的输出。例如,如果我们想要预测一个句子中某个单词的下一个单词,输出表示的是词汇表中每个单词可能成为下一个单词的概率。具体具体公式为
注意事项
①在传统神经网络中,每一层网络所用的参数都是不同的,但是在RNN中,在每一个时刻都共享相同的参数(
U,V,W
),只是输入有所不同而已,这样就大大地减少了我们学习的参数的数量。
②在每一个隐藏层
st
中是由多个神经元构成的,尽管图中只用了一个圆圈表示。
③事实上,并不需要每一个隐藏层后都进行输出,只需要在我们想要的层后输出即可。
④在语言模型中,每一个输入其实是一个句子中的单词,这个单词用词向量的形式来表示。然后对应时刻的输出也是一个词向量,表示的是词汇表中可能成为当前时刻单词的下一个单词的可能性。
⑤通常我们把一个句子作为一个训练样本,然后把句子中的每一个单词作为每个时刻的输入。
RNN训练的方法:BPTT
首先,从上面对RNN的描述可以得到一下两个关于隐藏状态
st
以及输出
y^t
的公式。
同时,通过一下的公式,把每一个时刻的损失(或者叫误差)定义为交叉熵的形式。
所以,总的误差为所有时刻的误差之和:
对于以上所有的公式, yt 是在时刻 t 时的正确的单词,而
现在,我们必须清楚我们训练RNN的目标是什么,就是要计算误差函数相对于模型参数
计算梯度的方法主要是用到微分中的链式法则。这里用具体的 E3 为例,描述如何计算各个参数的梯度。对于参数V,可以简单地用一下公式表示。
但是对于参数W就没有那么简单了,因为计算参数W的梯度的时候涉及到了隐藏状态,而每一个隐藏状态都与上一个隐藏状态有关,所以参数W的梯度的计算更为复杂。可以使用以下公式表示。
BPTT的梯度消失问题
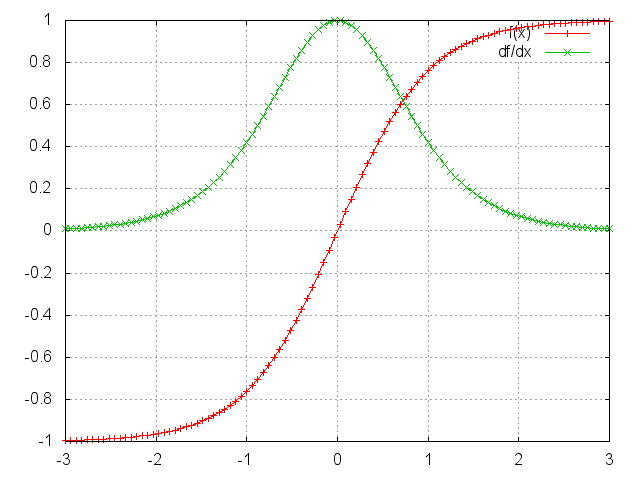
如果激活函数使用的时
tanh
函数或者是
sigmoid
函数的话,这两个函数的特征是在函数曲线的两端的导数是趋于0的,而且这两个函数计算出的值上界为1,这意味着我们在计算梯度时很容易使得梯度为0,特别是对于相隔比较远的两个层之间计算梯度的情况下,这也意味着整个网络并不能保存数据间的长期依赖关系,从而降低了模型的预测效果。因此我们必须想办法解决梯度消失问题。
相反,当激活函数设置不当或者参数初始化较大时,就发生梯度爆炸(gradient boost)的问题。但是我们更加关注的是梯度消失问题,因为两个方面:第一,梯度爆炸问题的发生是很容易观测得到的,因为到梯度很大时会产生NaN值从而使得程序崩溃停止,而梯度消失很难观测得到;第二,我们可以通过预设阈值来有效地解决梯度爆炸问题,而梯度消失很难去解决。
解决梯度消失问题的方法有几种。第一种是适当地初始化参数矩阵来减少梯度消失的影响。第二种是使用正则化方法。还有一种比较受欢迎的方法是使用
ReLU
作为激活函数,而不是
tanh
和
sigmoid
函数,因为
ReLU
函数的导数要不是0,要不是1,所以不太可能发生梯度消失的问题。另一种更加受欢迎的方法是使用LSTM或者GRU架构。















 31万+
31万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









