







Redis dict使用的哈希算法
前面提到,一个kv键值对,添加到哈希表时,需要用一个映射函数将key散列到一个具体的数组下标。
Redis 目前使用两种不同的哈希算法:
- MurmurHash2
是种32 bit 算法:这种算法的分布率和速度都非常好;Murmur哈希算法最大的特点是碰撞率低,计算速度快。Google的Guava库包含最新的Murmur3。
具体信息请参考 MurmurHash 的主页: http://code.google.com/p/smhasher/ 。 - 基于 djb 算法实现的一个大小写无关散列算法:具体信息请参考 http://www.cse.yorku.ca/~oz/hash.html
关于使用哪种算法取决于具体应用所处理的数据:
- 命令表以及 Lua 脚本缓存都用到了算法 2 。
- 算法 1 的应用则更加广泛:数据库、集群、哈希键、阻塞操作等功能都用到了这个算法。
Redis dict各种操作
以下是用于处理 dict 的各种 API , 它们的作用及相应的算法复杂度:
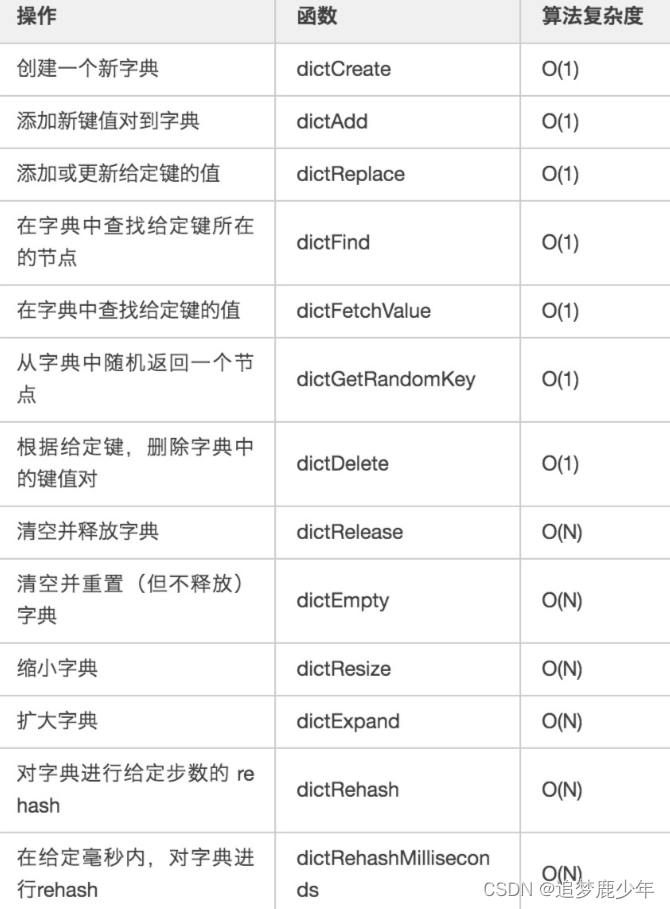
dict的创建(dictCreate)
创建dict
dict *d = dictCreate(&hash_type, NULL);
dict *dictCreate(dictType *type,
void *privDataPtr)
{
dict *d = zmalloc(sizeof(*d));
_dictInit(d,type,privDataPtr);
return d;
}
int _dictInit(dict *d, dictType *type,
void *privDataPtr)
{
_dictReset(&d->ht[0]);
_dictReset(&d->ht[1]);
d->type = type;
d->privdata = privDataPtr;
d->rehashidx = -1;
d->iterators = 0;
return DICT_OK;
}
static void _dictReset(dictht *ht)
{
ht->table = NULL;
ht->size = 0;
ht->sizemask = 0;
ht->used = 0;
}
dictCreate为dict的数据结构分配空间并为各个变量赋初值。其中两个哈希表ht[0]和ht[1]起始都没有分配空间,table指针都赋为NULL。这意味着要等第一个数据插入时才会真正分配空间。
- ht[0]->table 的空间分配将在第一次往字典添加键值对时进行;
- ht[1]->table 的空间分配将在 rehash 开始时进行;
dictAdd函数是调用 dictAddRaw实现的:
/* 将Key插入哈希表 */
dictEntry *dictAddRaw(dict *d, void *key)
{
int index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d); // 如果哈希表在rehashing,则执行单步rehash
/* 调用_dictKeyIndex() 检查键是否存在,如果存在则返回NULL */
if ((index = _dictKeyIndex(d, key)) ==  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











