







1 什么是字典树
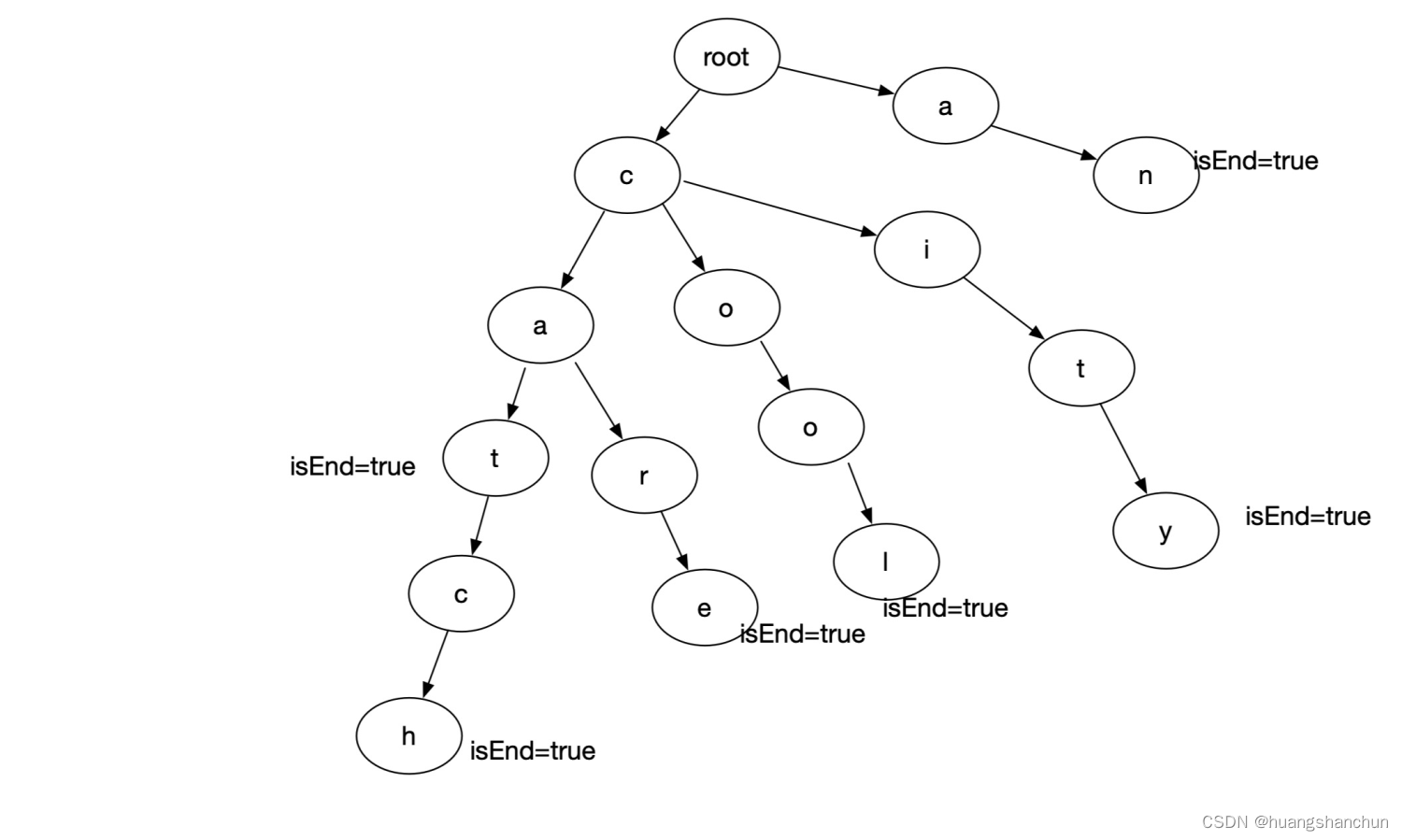
字典树,又称Tire、单词查找树、前缀树,是一种树形结构,也是哈希树的一种变种,主要用于同于统计和排序大量字符串(不限于字符串),所以经常被搜索引擎系统用于文本词频统计。如下图所示,用an、catch、care、cool、city几个词建立的一个字典树。字典树不会把某个单词存放到具体的节点,而是通过路径来表示具体单词,当你输入ca 系统就可以推荐出cat、catch、care相关词(实际中可能比这个可以按照相应频次)。
字典树通过空间换时间,利用字符串公共前缀来减少查询时间,最大限度地减少无谓的字符串,查询效率比哈希树高。
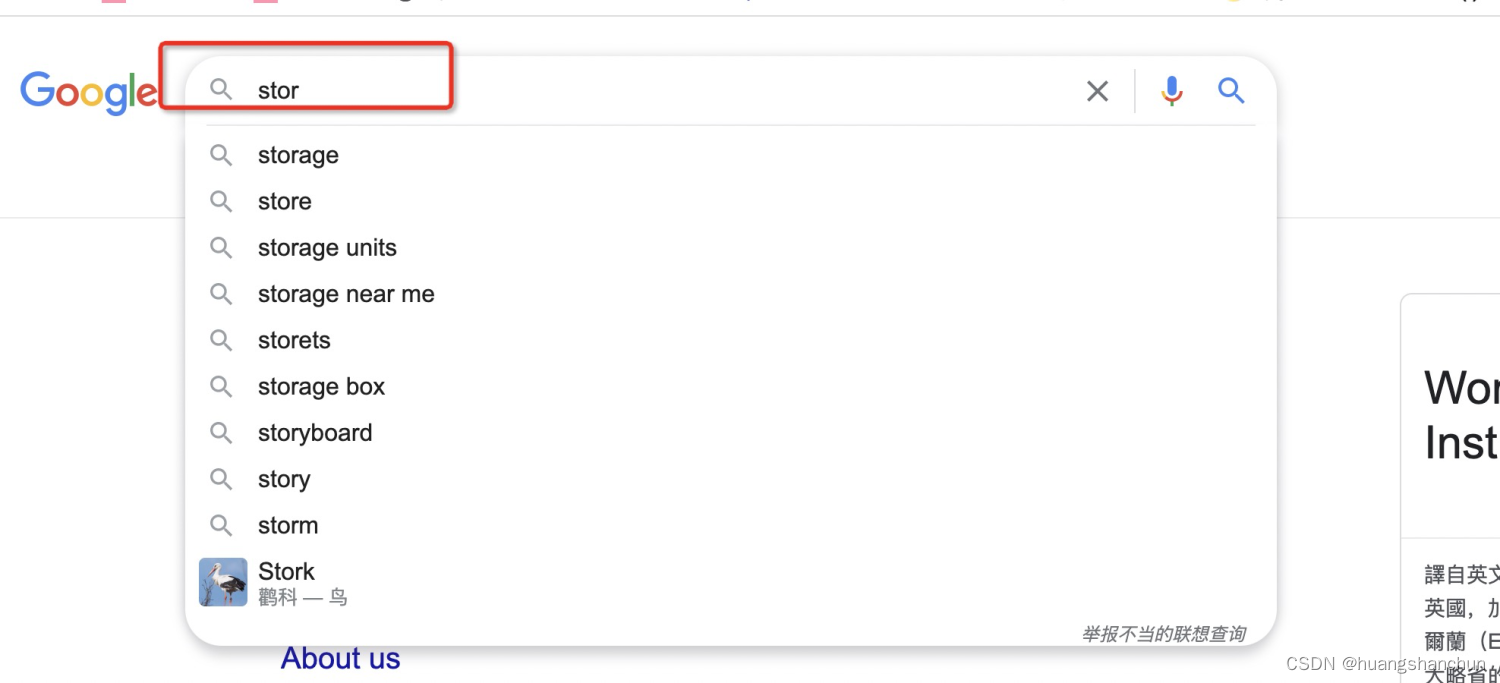
典型的应用场景,当你在google中输入,stor之后,系统会推荐出一个列表。
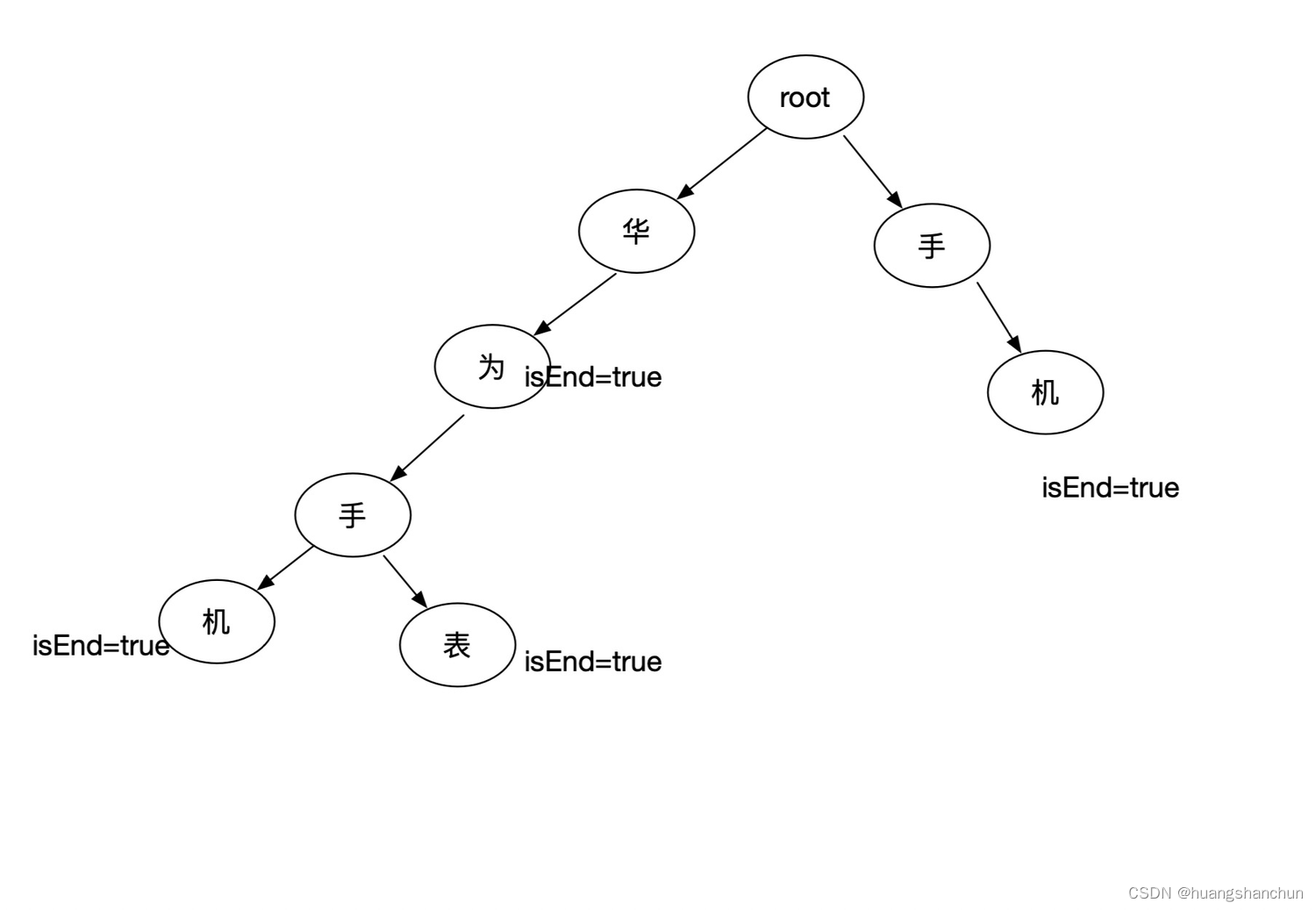
再比如使用华为、华为手机、华为手表、手机几个词建立一个字典树。
字典树基本性质:
● 根节点不包含字符,除根节点外每一个节点都只包含一个字符(要看具体使用语言)。
● 从根节点到某一个节点,路径上经过的字符串连接起来,为该节点的对应的字符串。
● 每个节点所有子节点包含的字符串都不相同。
2 实现一个字典树
https://leetcode.cn/problems/implement-trie-prefix-tree/
思路:题目中都是使用小写字符串,可以定义如下数据结构
public static class TrieNode{
public boolean isEnd;
public Character data;
//使用数组来表示具体字符节点
public TrieNode[] children;
public TrieNode(Character c) {
children=new TrieNode[26];
this.data=c;
}
}
完整的代码
class Trie {
private TrieNode root;
public Trie() {
root=new TrieNode(null);
}
public void insert(String word) {
char[] arr= word.toCharArray();
TrieNode p=root;
for(char c:arr){
int index=c-'a';
if(p.children[index]==null){
p.children[index]=new TrieNode(c);
}
p=p.children[index];
}
p.isEnd=true;
}
public boolean search(String word) {
TrieNode node = searchPrefix(word);
return node!=null && node.isEnd;
}
public boolean startsWith(String prefix) {
TrieNode node = searchPrefix(prefix);
return node!=null;
}
private TrieNode searchPrefix(String prefix) {
char[] arr = prefix.toCharArray();
TrieNode node=root;
for(char c : arr){
int index = c - 'a';
if(node.children[index]==null) {
return null;
}
node = node.children[index];
}
return node;
}
public static class TrieNode{
public boolean isEnd;
public Character data;
public TrieNode[] children;
public TrieNode(Character c) {
children=new TrieNode[26];
this.data=c;
}
}
}
扩展思路:考虑字符个数,是可变的,可以考虑使用一个Map,定义如下数据结构
public static class TrieNode {
public boolean isEnd;
public Character data;
public Map<Character, TrieNode> childrenMap;
public TrieNode(Character c) {
childrenMap = new HashMap<>();
this.data = c;
}
public void putChildNode(Character c, TrieNode node) {
childrenMap.put(c, node);
}
public TrieNode getChildNode(Character c) {
return childrenMap.get(c);
}
}
完整的代码如下:
class Trie {
private TrieNode root;
public Trie() {
root = new TrieNode(null);
}
public void insert(String word) {
char[] arr = word.toCharArray();
TrieNode p = root;
for (char c : arr) {
if (p.getChildNode(c) == null) {
TrieNode childNode = new TrieNode(c);
p.putChildNode(c, childNode);
}
p =p.getChildNode(c);
}
p.isEnd = true;
}
public boolean search(String word) {
TrieNode node = searchPrefix(word);
return node != null && node.isEnd;
}
public boolean startsWith(String prefix) {
TrieNode node = searchPrefix(prefix);
return node != null;
}
private TrieNode searchPrefix(String prefix) {
char[] arr = prefix.toCharArray();
TrieNode node = root;
for (char c : arr) {
if (node.getChildNode(c) == null) {
return null;
}
node = node.getChildNode(c);
}
return node;
}
public static class TrieNode {
public boolean isEnd;
public Character data;
public Map<Character, TrieNode> childrenMap;
public TrieNode(Character c) {
childrenMap = new HashMap<>();
this.data = c;
}
public void putChildNode(Character c, TrieNode node) {
childrenMap.put(c, node);
}
public TrieNode getChildNode(Character c) {
return childrenMap.get(c);
}
}
}
3 实战
单词搜索II
https://leetcode.cn/problems/word-search-ii/
解法一:可以参考单词搜索I的方法,采用dfs。
class Solution {
private char[][] board;
private int row;
private int col;
public List<String> findWords(char[][] board, String[] words) {
this.board = board;
this.row = board.length;
this.col = board[0].length;
List<String> ans = new ArrayList<>();
for (String word : words) {
if (findWord(word)) {
ans.add(word);
}
}
return ans;
}
private boolean findWord(String word) {
boolean[][] visit = new boolean[row][col];
for (int i = 0; i < row; i++){
for (int j = 0; j < col; j++) {
if (dfs(i, j, 0, visit, word)) {
return true;
}
}
}
return false;
}
private boolean dfs(int i, int j, int index, boolean[][] visit, String word) {
if (index >= word.length()) {
return true;
}
if (i < 0 || i >= row || j < 0 || j >= col || visit[i][j] || word.charAt(index) != board[i][j]) {
return false;
}
visit[i][j] = true;
boolean ans = dfs(i + 1, j, index + 1, visit, word) || dfs(i - 1, j, index + 1, visit, word)
|| dfs(i, j + 1, index + 1, visit, word) || dfs(i, j - 1, index + 1, visit, word);
visit[i][j] = false;
return ans;
}
}
不难看出这种做法思路清晰,但是时间复杂度较高,每个单词都需要检查&判断一次。
解法二:采用字典树,一次性判断完。
class Solution {
private char[][] board;
private int row;
private int col;
private Set<String> ans;
public List<String> findWords(char[][] board, String[] words) {
this.board = board;
this.row = board.length;
this.col = board[0].length;
ans = new HashSet<>();
Trie trie = new Trie();
for (String word : words) {
trie.insert(word);
}
boolean[][] visit = new boolean[row][col];
for (int i = 0; i < row; i++) {
for (int j = 0; j < col; j++) {
dfs(i, j, visit, trie.root);
}
}
return new ArrayList(ans);
}
private void dfs(int i, int j, boolean[][] visit, TrieNode node) {
if (node.isEnd) {
ans.add(node.word);
}
if (i >= row || j >= col || i < 0 || j < 0 || visit[i][j]) {
return;
}
if (node.children.get(board[i][j]) == null) {
return;
}
node = node.children.get(board[i][j]);
visit[i][j] = true;
dfs(i + 1, j, visit, node);
dfs(i - 1, j, visit, node);
dfs(i, j + 1, visit, node);
dfs(i, j - 1, visit, node);
visit[i][j] = false;
}
}
class Trie {
public TrieNode root;
public Trie() {
this.root = new TrieNode();
}
public void insert(String word) {
TrieNode cur = root;
for (int i = 0; i < word.length(); ++i) {
char c = word.charAt(i);
if (!cur.children.containsKey(c)) {
cur.children.put(c, new TrieNode());
}
cur = cur.children.get(c);
}
cur.isEnd = true;
cur.word = word;
}
}
public class TrieNode {
public boolean isEnd;
public String word;
public Map<Character, TrieNode> children;
public TrieNode() {
children = new HashMap<>();
}
}
















 275
275











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









