






1. 什么是分区表
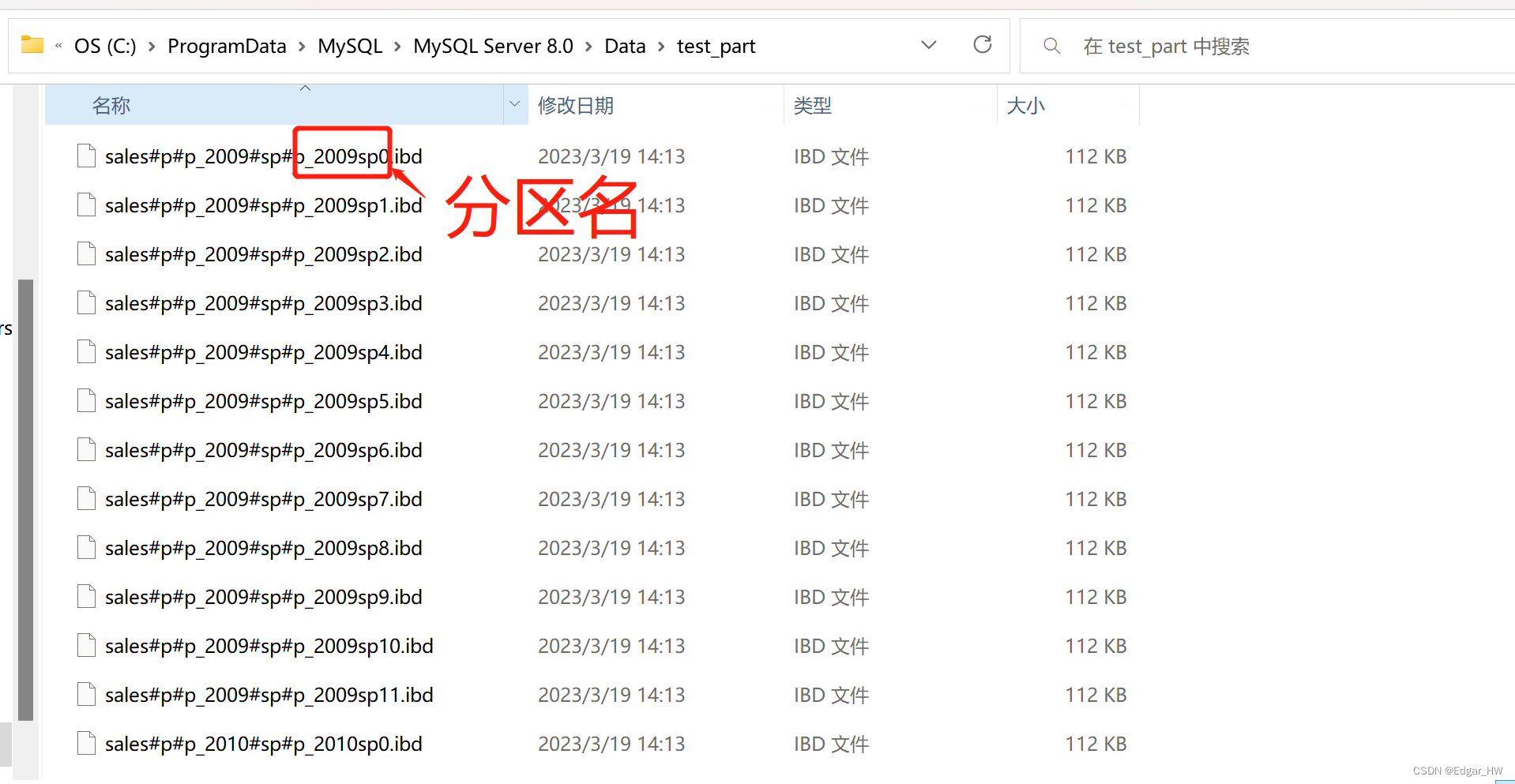
首先分区表是一个独立的逻辑表,但是底层由很多物理子表组成,从底层的文件系统来看,每个分区表都有一个使用#分割命名的表文件。
例如下面的逻辑表sales;
create table sales(order_date datetime not null)
engine=InnoDB partition by range(year(order_date)) (
partition p_2009 values less than (2010),
partition p_2010 values less than (2011),
partition p_catcall values less than maxvalue
);
insert into sales values
('2009/01/01 00:00'),
('2010/01/01 00:00'),
('2011/01/01 00:00'),
('2012/01/01 00:00')
;
- 查看表存储位置和文件系统结构:
show global variables like "%datadir%";-
查看分区信息
select * from sales partition (p_2010);用户在执行查询的时候,优化器会根据分区定义过滤那些没有我们需要数据的分区,这样查询就不需要扫描所有分区了,只需要查询包含需要数据的分区即可。
explain select * from sales where order_date ='2010/01/01 00:00';
2. 分区表常见使用场景
- 表非常大以至于无法全部放在内存中,或者只有最后部分有热点数据,其他均为历史数据。
- Innodb单个索引的互斥访问十分严重的时候,可以利用分区表避免这个性能瓶颈
- 数据量十分庞大的情况下,数据的备份和恢复(因为单个分区表可以单独备份和恢复,这样对于大量数据只需要备份当天或者当月的数据即可,数据恢复也可以只恢复某个分区的数据)
3. 在分区表上执行增删改查会发生什么?
- SELECT查询
分区层先打开并锁住所有底层表,优化器会先判断是否可以过滤部分分区,然后再调用存储引擎接口访问各个分区的数据。
- INSERT/UPDATE/DELETE
也是在分区曾先打开并锁住所有底层表,确定要处理的数据在哪个分区,然后做相应的处理操作
上述操作都会在分区层先打开并锁住底层表,但这并不是说分区表在处理过程中是锁住全表的,如果存储引擎能够自己实现行级表,则会在分区层释放掉对应表锁。
4. 分区表的类型
- Range分区
- LIST分区
列值匹配一个离散集合来进行分区。示例如下:
#cid代表商品类别ID
create table test(id int, cid int) partition by list(cid)
(
partition p_01 values in (1,3),
partition p_02 values in (2,4),
);- HASH分区
利用数据库自带的hash算法自动帮忙分区。
create table test(id int, cid int) partition by hash(cid) partitions 4;- 多列分区
columns关键字允许多个字符串和日期作为分区定义列,同时还允许使用多个列定义一个分区
create table test(a int, b int, c int) partition by range columns(a,b)
(
partition p_01 values less than (10,10),
partition p_02 values less than (10,20),
);4. 子分区
比较重要的分区还有子分区,子分区可以将某一个分区再进行细分,达到进一步有意义的减少分区数据的目的,所以其特别适用大表。
create table sales(order_date datetime not null)
engine=InnoDB partition by range(year(order_date))
subpartition by hash(month(order_date))
subpartitions 12
(
partition p_2009 values less than (2010),
partition p_2010 values less than (2011),
partition p_catcall values less than maxvalue
);
insert into sales values
('2009/01/01 00:00'),
('2010/01/01 00:00'),
('2011/01/01 00:00'),
('2012/01/01 00:00')
;
4. 分区表的使用
- 全表扫描数据,无需索引
可以使用简单的分区方式存放表,不要任何索引,根据分区的规则大致定位出需要的数据的位置,只要能够使用WHERE条件,将数据限制在少数分区中,则效率还是很高的。
- 索引数据,并分离热点
可以将热点数据放在单独的分区中,让这个分区的数据可以缓存到内存中,这样查询就可以只访问一个很小的分区表,且能够使用索引。
5.分区表的陷进
分区表想要很好的使用,其都是基于两个假设:①查询可以过滤掉很多额外的分区;②分区本身不会带来额外的开销。
- NULL值可能会导致分区过滤无效
如果列值为null则会导致数据被放到第一个分区,无形中会增加第一个分区数据的大小。解决方案:可以自己建一个永远不会有数据的分区来存放null,比如 p_nulls values less than (0)
- 分区列和索引列不匹配
- 选择分区的成本可能很高
分区越多,筛选的效率越低。实际开发时,一般都需要限制分区的数量,一般来说100个左右的分区是没有问题的。
- 打开并锁住所有底层表的成本可能很高
打开并锁住底层表是在分区过滤之前发生的,所以其可能会影响到其他正常查询。
- 维护分区的成本可能很高
重组分区或者修改表分区这类操作都会涉及到数据的复制,可能会很慢,他们都是先创建一个临时分区,然后将数据复制过去,然后再删除原分区。
下一次分享MySQL 分区和分库分表的对比。















 4562
4562











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









