







一、算法笔记提炼
· 数学相关
1. 最大公约数+最小公倍数(只需要记住 定理即可)
gcd(a,b) = gcd(b,a%b); 意思是:a与b的最大公约数 即 b与a%b的最大公约数 而 0 与数a的最大公约数为数a,自然递归边界很容易得知
int gcd(int a,int b) {
if (b==0) {
return a;
}
return gcd(b,a%b);
}最小公倍数就较为简单,是基于最大公约数
int lcm(int a,int b){
int m=gcd(a,b);
if(m==0) return 0;
return a*b/m;
}2.素数的判断(素数表的构建,用筛选法能够很大程度降低时间复杂度)
不能整除1和自身之外的其他数的自然数,自然数1除外,而sqrt(n)就是n的中介数,如果一个数x>sqrt(n),x!=n且能被n整除,那么商一定是小于sqrt(n),因此只需要遍历2-sqrt(n)即可
bool is_prime(int n){
if(n==0||n==1) return false;
int s=(int)sqrt(1.0*n);
for(int i=2;i<=s;i++){
if(n%i==0) return false;
}
return true;
}配合上述判断素数的方法O(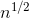
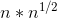
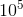
const int maxn = 100;
int prime[maxn], pNum = 0; //prime存储素数, pNum是指素数个数
bool p[maxn] = {0}; //p[i]代表i是否为素数
void Find_Prime() {
for (int i = 0; i <= maxn;i++) {
if (is_prime(i)) {
p[i] = true;
prime[pNum++] = i;
}
}
}更为快速的构建素数表的方法,名为素数筛选法,主要步骤就是筛,因为非素数均等于小于其的某两个数的积,算法从小到大枚举每一个数,对于每一个素数,筛去其所有倍数,没有被前面步骤所筛去的数即为素数.
const int maxn = 100;
int prime[maxn], pNum = 0; //prime存储素数, pNum是指素数个数
bool p[maxn] = {0}; //p[i]代表i是否为素数
void Find_Prime() {
for (int i = 2; i <= maxn;i++) {
if (p[i]==false) {
prime[pNum++] = i; //代表i没有被筛去
for (int j = i + i; j <= maxn;j+=i) {//把后面i的倍数全部筛去
p[j] = true;
}
}
}
}这样此算法就用不到判断n是否为素数的函数了,时间复杂度为:O(
3.质因子分解(顾名思义:将一个正整数写成一个或多个质数的乘积。如:180=2*2*3*3*5) 另言 也就是说,大于2的任何正整数都是某个素数的倍数,若为1倍,则其为素数,再回顾上述的素数筛选法,是否更有所启发呢.
还是回到sqrt(n)这个关键数,定理:一个数的质因子要么全部小于sqrt(n),要么只有一个大于sqrt(n),定理很好理解,因为不可能出现两个大于sqrt(n)的质因子
①算法思想,枚举1~sqrt(n)的所有质数p,判断其是否为n的因子.如果是n/=p;
如果枚举完后n>1,则n为最后一个质因子,且n一定大于sqrt(n)
上代码:
#include<iostream>
using namespace std;
//此处需要用到上述的素数表
struct factor {
int x, cnt;
}fac[10];
int main() {
Find_Prime();
int n;
cin >> n;
int sqr = (int)sqrt(1.0*n);
int num = 0;//记录不同因子个数
for (int i = 0; i<pNum&&prime[i] <= sqr; i++) {
if (n%prime[i] == 0) {
fac[num].x = prime[i];
fac[num].cnt = 0;
while (n%prime[i] == 0) {//计算出prime[i]这个质因子的个数
fac[num].cnt++;
n /= prime[i];
}
num++;
}
if (n == 1) break; //及早结束循环
}
if (n != 1) {
fac[num].x = n;
fac[num++].cnt = 1;
}
return 0;
}
.大数相关(即计算机无法表示的数,如:容易溢出的大数的加减,分数的加减乘除以及化简)
1.大数的存储
struct bign{
int d[1000]; //越低位存储的下标越小,如235 则d[0]=5,d[1]=3,d[2]=2
int len;
bign(){memset(d,0,sizeof(d));len=0;}
};一般在输入大整数时是字符串的形式,所以需要将字符串转为bign结构体
bign change(char str[]){
bign b;
b.len=strlen(str);
for(int i =0;i<b.len;i++){
b.d[i]=str[b.len-i-1]-'0';
}
return b;
}2.大数比较大小
int compare(bign b1,bign b2){
if(b1.len>b2.len)return 1;
else if(b1.len<b2.len) return -1;
for(int i=b1.len-1;i>=0;i--){
if(b1.d[i]>b2.d[i]) return 1;
else if(b1.d[i]<b2.d[i]) return -1;
}
return 0;
}3.大数的加法
bign add(bign a,bign b){
bign c;
int carry=0;
//从低位开始加 因为分配好了足够大小的空间,两者未对齐部分有一方已经默认为0
for(int i=0;i<a.len||i<b.len;i++){
int sum=a.d[i]+b.d[i]+carry;
c.d[c.len++]=sum%10;
carry=sum/10;
}
if(carry!=0) c.d[c.len++]=carry;
return c;
}
4.大数的减法
bign sub(bign a,bign b){ //默认要求a>=b
bign c;
for(int i=0;i<a.len||i<b.len;i++){
if(a.d[i]<b.d[i]){//不够减
a.d[i+1]--;
a.d[i]+=10;
}
c.d[c.len++]=a.d[i]-b.d[i];
}
//减法很容易出现 高位为0的情况,所以减完后需要去除多余的0,修正长度
while(c.len>=2&&c.d[c.len-1]==0){
c.len--;
}
return c;
}5.大数与int变量的乘法
算法思想:始终将int变量看作一个整体,与大数每一位相乘,结果的个位作为该位结果,其余当作进位
bign multi(bign a,int b){
bign c;
int carry=0;
for(int i=0;i<a.len;i++){
int sum=a.d[i]*b+carry;
c.d[c.len++]=sum%10;
carry=sum/10;
}
while(carry!=0){
c.d[c.len++]=carry%10;
carry/=10;
}
return c;
}那么大数与大数 A*B的算法思想即为将B的数组d每一位当作b传入函数multi之后再求和即可 。
6.大数与int变量的除法
算法思想:1234/7 ->1/7商0余数1 ,12/7商1余5,53/7商7余4,44/7商6余2
bign divide(bign a,int b,int &r){
bign c;
c.len=a.len;
//从高位开始除
for(int i=a.len-1;i>=0;i--){
r=a.d[i]+r*10;
c.d[i]=r/b;
r=r%b;
}
while(c.len>=2 && c.d[c.len-1]==0){
c.len--;
}
return c;
}.快速幂(俗称二分幂)减少递归次数,防止栈溢出
①如果b是奇数,
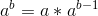
②如果b是偶数,
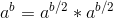
所以在log(b)次后就可以将b变为0,任何数的0次方为1
tyepdef long long LL;
//求a^b % m
LL binaryPow(LL a,LL b,LL m){
if(b==0) return 1;
if(b%2==0){
LL temp=binaryPow(a,b/2,m);
return temp*temp%m;
}else{
return a*binaryPow(a,b-1,m);
}
}.动态规划
贪心与分治均不属于动态规划,动态规划十分容易理解,就是不断的做最优小决策,简单来将就是将问题分解为多个重叠的小问题,求解小问题的最优解.何为重叠呢,即两个问题求解过程中,有公共解部分,但公共解不一定是最优解
1.数塔问题

求从顶层走到底层的路径上的数字和的最大值,上图只画了一部分,强调的是5-8-7,5-3-7可能是会走重路,因为会重复去计算从7出发再去底层时候的最优解。所以就会想到dp[i][j]代表第i层第j个数到达底层的最大数字和.显然dp[1][1]为最终要求解的值
dp[1][1]=max(dp[2][1],dp[2][2])+f[1][1] //其中f[i][j]代表第i层第j个数的数值
就有了,推导式:dp[i][j]=max(dp[i+1][j],dp[i+1][j+1])+f[i][j];
边界就很容易知道,最底层的dp[n][j]=f[n][j]
#include<cstdio>
#include<algorithm>
using namespace std;
const int maxn = 1000;
int f[maxn][maxn], dp[maxn][maxn];
int main() {
int n;
scanf("%d",&n);
for (int i = 1; i <= n;i++) {
for (int j = 1; j <=i;j++) {
scanf("%d",&f[i][j]);
}
}
//边界
for (int i = 1; i <= n; i++) { dp[n][i] = f[n][i]; }
//从下往上,从n-1层开始
for (int i = n - 1; i >= 1;i--) {
for (int j = 1; j <= i;j++) {
dp[i][j] = max(dp[i+1][j],dp[i+1][j+1])+f[i][j];
}
}
printf("%d",dp[1][1]);
return 0;
}
2.最长不下降子序列(可以不连续)LIS
A={1,2,3,-1,-2,7,9} 它的最长不下降子序列是:{1,2,3,7,9}
dp[i]代表以A[i]结尾的最长不下降子序列
所以循环到A[i]时,就要以此与j>=1 && j<i的数进行比较,若可以排在其后则更新dp[i]=dp[j]+1,若不能排在其后,则dp[i]=1
所以有推导式:dp[i]=max(1,dp[j]+1); j=1,2,3....i-1 && A[j]<=A[i]
边界:dp[i]=1;//每个元素自成一个序列
#include<cstdio>
#include<algorithm>
#include<vector>
using namespace std;
const int maxn = 1000;
int dp[maxn];
int A[maxn];
int main() {
int n;
scanf("%d",&n);
for (int i = 1; i <= n;i++) {
scanf("%d",&A[i]);
dp[i] = 1;//边界
}
int ans=0;
for (int i = 1; i <= n;i++) {
for (int j = 1; j < i;j++) {
if (A[j]<=A[i] && dp[j]+1>dp[i]) {
dp[i] = dp[j]+1;
}
}
ans = max(ans,dp[i]);
}
printf("%d",ans);
//知道以谁结尾式最长非下降子序列后,只需要根据其下标往前找小于等于它的数即可
return 0;
}
3.最大连续子序列和
给定一个数字序列 A1,A2,。。。An求 1<=i<=j<=n 使得Ai+.....+Aj最大
同理认为dp[i]代表以A[i]结尾的最大和,那么每次遍历时候,dp[i]=max(A[i],dp[i-1]+A[i]);
而dp[i]得深层含义就是,A[p]+A[p+1]+...A[i]和最大,仔细斟酌就会很容易理解哦。
#include<cstdio>
#include<algorithm>
#include<vector>
using namespace std;
const int maxn = 10010;
int dp[maxn];
int A[maxn];
int main() {
int n;
scanf("%d",&n);
for (int i = 0; i <n;i++) {
scanf("%d",&A[i]);
}
//边界
dp[0] = A[0];
int ans = 0;
int index = 0;
for (int i = 0; i < n;i++) {
dp[i] = max(dp[i-1]+A[i],A[i]);
if (dp[i] > ans) {
index = i;
ans = dp[i];
}
}
printf("%d\n",ans);
//下述式寻找最大得连续子序列,从后往前输出
int sum = 0;
for (int j = index; j >=0;j--) {
sum += A[j];
if (sum == ans) { //这个一定要在前,一旦等于即退出循环
printf("%d", A[j]);
break;
}
else if (sum < ans) {
printf("%d ",A[j]);
}
}
return 0;
}
4.最长回文串
给定一个字符串S,求S的最长回文子串的长度
dp[i][j]表示S[i]至S[j]是否为回文子串,dp[i][j]=0不是,dp[i][j]=1是回文子串
两种情况:
①S[i]==S[j],则只要S[i+1]至S[j-1]是回文子串则其是回文子串,否则不是
②S[i]!=S[j]则不是回文子串
dp[i][j]=dp[i+1][j-1],S[i]==S[j] or = 0 ,S[i]!=S[j]
边界:dp[i][i]=1,dp[i][i+1]=(S[i]==S[j]?1:0)
算法思想,从回文子串的长度出发考虑,即先枚举子串的长度L,再枚举左端点i,那么右端点i+L-1就自然确定了。
#include<cstdio>
#include<algorithm>
#include<cstring>
using namespace std;
const int maxn = 1010;
char S[maxn];
int dp[maxn][maxn];
int main(){
gets_s(S);
int len = strlen(S), ans = 1;
memset(dp,0,sizeof(dp));
for (int i = 0; i < len; i++) { //边界
dp[i][i] = 1;
if (i < len - 1 && S[i]==S[i+1]) {
dp[i][i + 1] = 1;
ans = 2;
}
}
for (int L = 3; L <= len; L++) {
for (int i = 0; i + L - 1 < len;i++) {
int j = i + L - 1;
if (S[i]==S[j] && dp[i+1][j-1]==1) {
dp[i][j] = 1;
ans = L;
}
}
}
printf("%d\n",ans);
return 0;
}
5.最长公共子序列 LCS
给定两个字符串(或者数字序列) A和B,求一个字符串,使得这个字符串是A和B的最大公共部分 子序列可以不连续

令dp[i][j]表示字符串A的i号位和字符串B的j号位之前的LCS长度(下标从1开始),dp[4][5]表示sads和admin的LCS长度
可以根据A[i]和B[j]的情况。分为两种决策:
①若A[i]==B[j],则字符串A与字符串B的LCS增加了1位,即有dp[i][j]=dp[i-1][j-1]+1;
②若A[i]!=B[j],则dp[i][j]=max(dp[i-1][j],dp[i][j-1]);
边界:dp[i][0]=dp[0][j]=0;
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
const int maxn = 1000;
char A[maxn], B[maxn];
int dp[maxn][maxn];
int main() {
A[0] = ' '; B[0] = ' ';
scanf("%s", A + 1);
scanf("%s", B + 1);
int len_A = strlen(A);
int len_B = strlen(B);
for (int i = 0; i < len_A; i++) {
dp[i][0] = 0;
}
for (int i = 0; i < len_B; i++) {
dp[0][i] = 0;
}
int LCS = 0, k = 0;
char res[maxn];
for (int i = 1; i < len_A; i++) {
for (int j = 1; j < len_B; j++) {
if (A[i] == B[j]) {
dp[i][j] = dp[i - 1][j - 1] + 1;
}
else dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
}
printf("%d", dp[len_A - 1][len_B - 1]);
return 0;
}
如果想获取到这个最长公共字符串,就需要在上面的基础上做一些特殊处理。
算法思想为:首先记录A与B相等字符在A中的下标index_A和B中的下标index_B,并且统计出相等字符的总数。同时用结构体数组存储上述这些信息,之后遍历结构体数组,得出index_B从小到大且没有相等的最大子数组就是最终答案。
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
const int maxn = 1000;
char A[maxn],B[maxn];
int dp[maxn][maxn];
struct Node
{
int index_A; //A与B相同的字符在A中的下标
int index_B; //A与B相同的字符在B中的下标
}nodes[maxn];
int main() {
A[0] = ' '; B[0] = ' ';
scanf("%s", A + 1);
scanf("%s",B+1);
int len_A = strlen(A);
int len_B = strlen(B);
for (int i = 0; i <= len_A; i++) {
dp[i][0] = 0;
}
for (int i = 0; i <= len_B; i++) {
dp[0][i] = 0;
}
int eq_num = 0,k=0;
char res[maxn];
for (int i = 1; i < len_A; i++) {
for (int j = 1; j < len_B; j++) {
if (A[i] == B[j]) {
eq_num++;
dp[i][j] = dp[i - 1][j - 1] + 1;
Node node;
node.index_A = i;
node.index_B = j;
nodes[k++] = node;
}
else dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
}
if (eq_num == 0) {
printf("0");
return 0;
}
int LCS = 0;
Node pre_node=nodes[0];
for (int i = 1; i < eq_num;i++) {
if (nodes[i].index_B<pre_node.index_B) {
LCS = 0; //重新记录最长公共序列的长度
res[LCS++] = A[nodes[i].index_A];
pre_node = nodes[i];
}
else if(nodes[i].index_B>pre_node.index_B &&
nodes[i].index_A!=pre_node.index_A) {
res[LCS++] = A[nodes[i].index_A];
pre_node = nodes[i];
}
if (LCS == dp[len_A-1][len_B-1]) break;
}
res[LCS] = '\0';
printf("%s", res);
return 0;
}
.背包问题 (个人觉得背包问题是一个动态规划问题,用贪心策略虽然有时候有效,但贪心策略很难证明,因此很难认定用贪心策略得出的结果是全局最优。但是我还是会分别展示贪心策略和动态规划解法,因为贪心策略也是一种很常用的基本算法,我还是很有良心的。)
1. 01背包问题
有n件物品,每件物品的重量为w[i],价值为c[i]。现有一个容量为V的背包,问如何选取物品放入背包,使得背包内物品的总价值最大。其中每件物品只有一件。
样例:
5 8 //n=5,V=8
3 5 1 2 2 //w[i]
4 5 2 1 3 //c[i]
<1>动态规划解法
令dp[i][v]表示第i件物品巧好装入背包中获得的最大价值
对物品i的选择策略有两种:
①不放物品i,那么就是指前i-1件物品恰好放入容量为v的背包中获得的最大价值 为dp[i-1][v]
②放物品i,那么就是指前i-1件物品恰好放入容量为v-w[i]的背包中所能获取的最大价值dp[i-1][v-w[i]]
dp[i][v]=max(dp[i-1][v],dp[i-1][v-w[i]+c[i]]);
可以看出dp[i][v]只与dp[i-1][]相关,那么可以枚举i从1到n,v从0到V
边界:dp[0][v]=0
#include<cstdio>
#include<algorithm>
using namespace std;
const int maxn=100;
const int maxv=1000;
int w[maxn],c[maxn],dp[maxn][maxv];
int main(){
int n,V;
scanf("%d %d",&n,&V);
for(int i=1;i<=n;i++){
scanf("%d",&w[i]);
}
for(int i=1;i<=n;i++){
scanf("%d",&c[i]);
}
//边界
for(int v=0;v<=V;v++){
dp[0][v]=0;
}
for(int i=1;i<=n;i++){
for(int v=w[i];v<=V;v++){
dp[i][v]=max(dp[i-1][v],dp[i-1][v-w[i]]+c[i]);
}
}
int max=0;
for(int i=1;i<=n;i++){
if(dp[i][V]>max) max=dp[i][V];
}
printf("%d\n",max);
return 0;
}
<2>贪心策略解法
因为跟体积有关,所以每次选择单位体积下价值最高的物品入背包是当下最优的选择。代码如下:
#include<cstdio>
#include<algorithm>
using namespace std;
struct Product
{
int w,c;
double unit;
};
const int maxn = 100; //物件上限
Product p[maxn];
bool cmp(Product p1,Product p2) {
if (p1.unit > p2.unit) return true;
return false;
}
int main(){
int n, V;
scanf("%d %d",&n,&V);
for (int i = 1; i <= n; i++) {
scanf("%d", &p[i].w);
}
for (int i = 1; i <= n;i++) {
scanf("%d",&p[i].c);
p[i].unit = (p[i].c*1.0) / p[i].w;
}
//排序
sort(p+1,p+n+1,cmp);
int i = 1, max = 0, remain_V = V;
while (i<=n) {
if (p[i].w <= remain_V) { //可以放入
remain_V -= p[i].w;
max += p[i].c;
}
i++;
}
printf("%d",max);
return 0;
}
2.完全背包问题
有n种物品,每种物品的重量为w[i],价值为c[i]。现有一个容量为V的背包,问如何选取物品放入背包,使得背包内物品的总价值最大。其中每种物品都有无穷件。
01背包问题中每种物品的个数为一件,而完全背包问题中每种物品的件数是无限的
同样令dp[i][v] 代表第i种物品恰好放入背包所获取的最大收益
同样对于第i种物品有两种策略:
①第i种物品不放入 最大收益即为 dp[i-1][v]
②第i种物品放入,此时就和01背包问题不一样了,因为第i种物品不止一件,所以第i种物品可以放到v-w[i]<0为止。
状态转移方程为:dp[i][v]=max(dp[i-1][v],dp[i][v-w[i]]+c[i])
边界:dp[0][v]=0
#include<cstdio>
#include<algorithm>
using namespace std;
const int maxn=100;
const int maxv=1000;
int w[maxn],c[maxn],dp[maxn][maxv];
int main(){
int n,V;
scanf("%d %d",&n,&V);
for(int i=1;i<=n;i++){
scanf("%d",&w[i]);
}
for(int i=1;i<=n;i++){
scanf("%d",&c[i]);
}
//边界
for(int v=0;v<=V;v++){
dp[0][v]=0;
}
for(int i=1;i<=n;i++){
for(int v=w[i];v<=V;v++){
dp[i][v]=max(dp[i-1][v],dp[i][v-w[i]]+c[i]);
}
}
int max=0;
for(int i=1;i<=n;i++){
if(dp[i][V]>max) max=dp[i][V];
}
printf("%d\n",max);
return 0;
}
.字符串部分 KMP算法(这里就只是奉上 获取next数组的代码,因为KMP算法思想讲解比较繁琐,如果有想要完整代码的可以留言,暂时就写这么多)
给定两个字符串text 和Pattern,判断pattern是否时text的子串
const int maxn=1000;
int next[maxn];
void getNext(char s[],int len){
int j=-1;
next[0]=-1;
for(int i=1;i<len;i++){ //求解next[1]~next[len-1]
while(j!=-1 && s[i]!=s[j+1]){
j=next[j];
}
if(s[i]==s[j+1]){
j++;
}
next[i]=j;
}
}















 3358
3358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









