







1 引言
建立搜索引擎的主要步骤是找到一种搜集文档的方法,比如对网页的抓取;收集完文档之后,需要为这些文档建立索引,比如一张很大的表,表中包含文档及所有不同单词的位置信息;接下来则是通过查询返回一个经过排序的文档列表。一旦建立了索引,根据给定单词或词组来选择文档就变得非常简单了。这里奥妙就在于结果的排列方式,可以选择不同的度量方法,通过适当调整来改变网页的排名次序。
2 实现
文中通过两个类来实现整个过程:一个用于检索网页和创建数据库;另一个则通过查询数据库进行全文搜索。
2.1 索引
2.1.1 流程图如下

2.1.2 代码实现
---创建数据库表
createindextables(self)
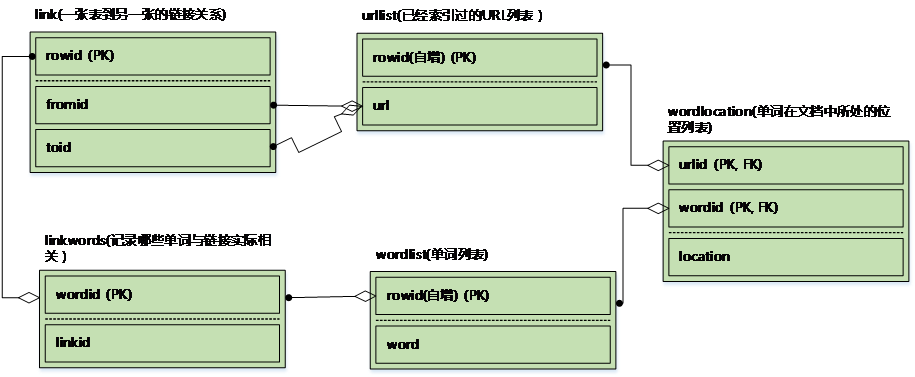
---从一小组网页开始进行广度优先搜索,直至某一给定深度,期间为网页建立索引
crawl(self,pages,depth=2)
------为每个网页建立索引
addtoindex(self,url,soup)
---------如果url已经建过索引,则返回true 判断网页是否已经存入数据库,如果存在,则判断是否有任何单词与之关联
isindexed(self,url)
---------从一个HTML网页中提取不带标签的文字
gettextonly(self,soup)
---------将字符串拆分成一组独立的单词,以便将其加入到索引之中
separatewords(self,text)
---------获取条目id,如果条目不存在,则加入数据库
getentryid(self,table,field,value,createnew=True)
------添加一个关联两个网页的链接,这里没有实现
addlinkref(self,urlFrom,urlTo,linkText)
---计算pagerank值
calculatepagerank(self,iterations=20)
2.2 搜索
2.2.1 流程图如下
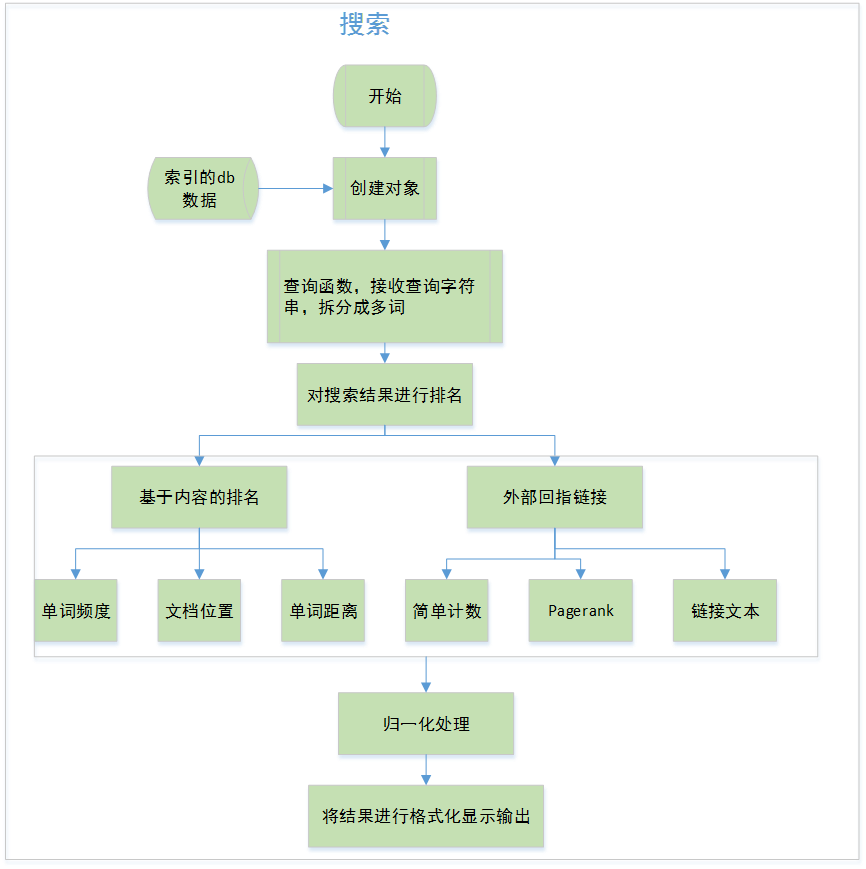
2.2.2 实现
getmatchrows(self,q):查询函数,接收查询字符串,拆分成多词
query(self,q):检索
---基于内容的排名
frequencyscore(self,rows):单词频次计算,统计单词出现次数,并对评论值归一处理
locationscore(self,rows):文档位置计算,通过计算所有单词的位置之和
distancescore(self,rows):单词距离计算
---外部回指链接
inboundlinkscore(self,rows):计算每个网页上链接的数目
pagerankscore(self,rows):pagerank算法评分计算
linktextscore(self,rows,wordids):计算链接文本的得分
---归一化函数接受一个包含ID与评价值的字典,并返回一个带有相同ID。而评价值则介于0和1之间的新字典
normalizescores(self,scores,smallIsBetter=0)
---根据id获取url名称
geturlname(self,id)
---获取得分情况
getscoredlist(self,rows,wordids)
基于内容的排名
根据网页的内容,利用某些可行的度量方式来对查询结果进行判断。
可行的度量方法有以下三种:
1. 单词频度:所查询的单词在文档中出现的次数可以帮助判断文档的相关性
2. 文档位置:文档的主题很有可能出现在靠近文档的开始处
3. 单词距离:如果查询中有多个单词,则在文档中出现的位置应该离得很近
利用外部回指链接
上述的评价度量都是基于网页内容的,同样也可以通过考察外界就该网页提供的信息,尤其是那些链向了该网页,以及对该网页的评价来改善搜索结果
1. 简单计数:统计每个网页链接的数目,将链接总数作为针对网页的度量
2. PageRank算法:为每个网页赋予一个指示网页重要程度的评价值。
网页的重要性是依据指向该网页的所有其他网页的重要性,已经这些网页中所包含
的链接数求得的
3.链接文本:根据指向某一网页的链接文本来决定网页的相关程度。相比于被链接的网页自身所提供的信息而言,从指向该网页的链接中所得信息会更有价值
2.3 源码
建立索引:
<span style="font-family:Microsoft YaHei;font-size:12px;">class crawler:
#初始化crawler类并传入数据库名称
def __init__(self,dbname):
self.con=sqlite.connect(dbname)
def __del__(self):
self.con.close()
def dbcommit(self):
self.con.commit()
#辅助函数,用于获取条目的id,并且如果条目不存在,就将其加入数据库中
'''
该函数的作用是返回某一条目的ID.如果条目不存在,则程序会在数据库中新建一条记录,并将ID返回
传入参数:类变量,表名,限定字段,限定字段的值,''
'''
def getentryid(self,table,field,value,createnew=True):
#执行sql语句
cur=self.con.execute(
"select rowid from %s where %s='%s'" % (table,field,value))
#返回一条查询结果行
res=cur.fetchone()
#如果查询结果为空
if res==None:
#则将该数据插入到表中
cur=self.con.execute(
"insert into %s (%s) values ('%s')" % (table,field,value))
return cur.lastrowid
else:
return res[0]
#为每个网页建立索引
def addtoindex(self,url,soup):
#如果当前网页已经索引,则直接返回
if self.isindexed(url):return
print 'Indexing '+url
#获取每个单词
text=self.gettextonly(soup)
words=self.separatewords(text)
#得到URL的id
urlid=self.getentryid('urllist','url',url)
#将每个单词与该url关联
for i in range(len(words)):
word=words[i]
if word in ignorewords:continue
wordid=self.getentryid('wordlist','word',word)
self.con.execute(
"insert into wordlocation(urlid,wordid,location) values(%d,%d,%d)" % (urlid,wordid,i))
#从一个HTML网页中提取文字(不带标签的)
'''
该函数返回一个长字符串,其中包含了网页中的所有文字,
它以递归向下的方式对HTML文档对象模型进行遍历,并找出其中的文本节点。
'''
def gettextonly(self,soup):
v=soup.string
if v==None:
c=soup.contents
resulttext=''
for t in c:
subtext=self.gettextonly(t)
resulttext+=subtext+'\n'
return resulttext
else:
return v.strip()
#根据任何非空白字符进行分词处理
'''
该函数将字符串拆分成一组独立的单词,以便将其加入到索引之中
'''
def separatewords(self,text):
#非_ 数字和字母作为分隔符,对于C++这种词汇处理是有问题的
splitter=re.compile('\\W*')
return [s.lower() for s in splitter.split(text) if s!='']
#如果url已经建过索引,则返回true 判断网页是否已经存入数据库,如果存在,则判断是否有任何单词与之关联
def isindexed(self,url):
u=self.con.execute \
("select rowid from urllist where url='%s'" % url).fetchone()
if u!=None:
#检查它是否已经被检索过了
v=self.con.execute(
'select * from wordlocation where urlid=%d' %u[0]).fetchone()
if v!=None:return True
return False
#添加一个关联两个网页的链接
def addlinkref(self,urlFrom,urlTo,linkText):
pass
#从一小组网页开始进行广度优先搜索,直至某一给定深度,
#期间为网页建立索引
'''
该函数也可以采用递归的形式进行定义,如果是这样,每个链接就都会出发函数的再次调用。
但是,广度优先的搜索方式可以是代码的后续修改更为容易,我们可以一直持续进行检索,
也可以将未经索引的网页列表保存起来,以备后续再行检索之用。同时,这样也避免了栈溢出的风险
传入参数:网页,深度
'''
def crawl(self,pages,depth=2):
#循环遍历网页列表
for i in range(depth):
newpages=set()
for page in pages:
try:
#打开网页
c=urllib2.urlopen(page)
except:
print "Could not open %s" %page
continue
#利用Beautiful Soup取网页中的所有链接
soup=BeautifulSoup(c.read())
#为网页建立索引
self.addtoindex(page,soup)
links=soup('a')
for link in links:
if('href' in dict(link.attrs)):
url=urljoin(page,link['href'])
if url.find("'")!=-1:continue
url=url.split('#')[0] #去掉位置部分
if url[0:4]=='http' and not self.isindexed(url):
#将没有索引的链接将加入到newpages的集合中
newpages.add(url)
linkText=self.gettextonly(link)
self.addlinkref(page,url,linkText)
self.dbcommit()
#将newpages赋给pages,然后再次进行循环
pages=newpages
#创建数据库表
def createindextables(self):
self.con.execute('create table urllist(url)')
self.con.execute('create table wordlist(word)')
self.con.execute('create table wordlocation(urlid,wordid,location)')
self.con.execute('create table link(fromid integer,toid integer)')
self.con.execute('create index wordidx on wordlist(word)')
self.con.execute('create index urlidx on urllist(url)')
self.con.execute('create index wordurlidx on wordlocation(wordid)')
self.con.execute('create index urltoidx on link(toid)')
self.con.execute('create index urlfromidx on link(fromid)')
self.dbcommit()
def calculatepagerank(self,iterations=20):
#清除当前的PageRank表
self.con.execute('drop table if exists pagerank')
self.con.execute('create table pagerank(urlid primary key,score)')
#初始化每个url,令其PageRank值为1
self.con.execute('insert into pagerank select rowid,1.0 from urllist')
self.dbcommit()
for i in range(iterations):
print "Iteration %d" % (i)
for(urlid,) in self.con.execute('select rowid from urllist'):
pr=0.15
#循环遍历指向当前网页的所有其他网页
for(linker,) in self.con.execute('select distinct fromid from link where toid=%d' % urlid):
#得到连接源对应网页的PageRank值
likingpr=self.con.execute(
'select score from pagerank where urlid=%d' %linker).fetchone()[0]
#根据链接源,求得总的链接数
linkingcount=self.con.execute(
'select count(*) from link where fromid=%d' % linker).fetchone()[0]
pr+=0.85*(linkingpr/linkingcount)
self.con.execute(
'update pagerank set score=%f where urlid=%d' % (pr,urlid))
self.dbcommit()</span><span style="font-family:Microsoft YaHei;">class searcher:
def __init__(self,dbname):
self.con=sqlite.connect(dbname)
def __del__(self):
self.con.close()
def getmatchrows(self,q):
fieldlist='w0.urlid'
tablelist=''
clauselist=''
wordids=[]
#根据空格拆分单词
words=q.split(' ')
tablenumber=0
for word in words:
#获取单词的ID
wordrow=self.con.execute(
"select rowid from wordlist where word='%s'" % word).fetchone()
if wordrow!=None:
wordid=wordrow[0]
wordids.append(wordid)
if tablenumber>0:
tablelist+=','
clauselist+=' and '
clauselist+='w%d.urlid=w%d.urlid and '% (tablenumber-1,tablenumber)
fieldlist+=',w%d.location' % tablenumber
tablelist+='wordlocation w%d' % tablenumber
clauselist+='w%d.wordid=%d' %(tablenumber,wordid)
tablenumber+=1
#根据各个组分,建立查询
#print "fieldlist=%s,tablelist=%s,clauselist=%s" %(fieldlist,tablelist,clauselist)
fullquery='select %s from %s where %s' % (fieldlist,tablelist,clauselist)
cur=self.con.execute(fullquery)
rows=[row for row in cur]
return rows,wordids
def getscoredlist(self,rows,wordids):
totalscores=dict([(row[0],0) for row in rows])
#此处是稍后放置评价函数的地方
weights=[(1.0,self.locationscore(rows)),
(1.0,self.frequencyscore(rows)),
(1.0,self.pagerankscore(rows))]
for (weight,scores) in weights:
for url in totalscores:
totalscores[url]+=weight*scores[url]
return totalscores
def geturlname(self,id):
return self.con.execute(
"select url from urllist where rowid=%d" %id).fetchone()[0]
def query(self,q):
rows,wordids=self.getmatchrows(q)
scores=self.getscoredlist(rows,wordids)
rankedscores=sorted([(score,url) for (url,score) in scores.items()],reverse=1)
for (score,urlid) in rankedscores[0:10]:
print '%f\t%s' % (score,self.geturlname(urlid))
'''
归一化函数接受一个包含ID与评价值的字典,并返回一个带有相同ID
而评价值则介于0和1之间的新字典。指明数值是越小越好,还是越大越好
'''
def normalizescores(self,scores,smallIsBetter=0):
vsmall=0.00001 #避免被零整除
if smallIsBetter:
#取出最小的评分
minscore=min(scores.values())
return dict([(u,float(minscore)/max(vsmall,l)) for (u,l) \
in scores.items()])
else:
maxscore=max(scores.values())
if maxscore==0:maxscore=vsmall
return dict([(u,float(c)/maxscore) for (u,c) in scores.items()])
'''
该函数建立一个字典,其中包含了行为集中每个唯一的URL ID所建的条目
函数对每个单次出现的次数进行统计,随后又对评论值做了归一化处理
'''
def frequencyscore(self,rows):
counts=dict([(row[0],0) for row in rows])
for row in rows:counts[row[0]]+=1
return self.normalizescores(counts)
'''
行集中每一行的第一项是URL ID,后面是所有待查单词的位置信息。
每个ID可以出现多次,每次对应的是不同的位置组合。针对每一行,该方法
将会计算所有单词的位置之和
'''
def locationscore(self,rows):
locations=dict([(row[0],1000000) for row in rows])
for row in rows:
loc=sum(row[1:])
if loc<locations[row[0]]:locations[row[0]]=loc
return self.normalizescores(locations,smallIsBetter=1)
def distancescore(self,rows):
#如果仅有一个单词,则得分都一样
if len(rows[0])<=2:return dict([(row[0],1.0) for row in rows])
#初始化字典,并填入一个很大的数
mindistance=dict([(row[0],1000000) for row in rows])
for row in rows:
dist=sum([abs(row[i]-row[i-1]) for i in range(2,len(row))])
if dist<mindistance[row[0]]:mindistance[row[0]]=dist
return self.normalizescores(mindistance,smallIsBetter=1)
'''
对于每一个链接,links表中记录了与其源和目的相对应的URL ID,
而且linkwords表还记录了单词与链接的关联。
处理外部回指链接的方法:在每个网页上统计链接的数目,并将链接总数作为
针对网页的度量。
通过对查询link表所得行集中的每个唯一的URL ID进行计数,建立起一个字典
'''
def inboundlinkscore(self,rows):
#存储传入的urlID
uniqueurls=set([row[0] for row in rows])
#计算urlID的引用链接数目
inboundcount=dict([(u,self.con.execute( \
'select count(*) from link where toid=%d' % u).fetchone()[0]) \
for u in uniqueurls])
return self.normalizescores(inboundcount)
def pagerankscore(self,rows):
pageranks=dict([(row[0].self.con.execute('select score from pagerank \
where urlid=%d' % row[0]).fetchone()[0]) for row in rows])
maxrank=max(pageranks.values())
normalizedscores=dict([(u,float(l)/maxrank) for (u,l) in pageranks.items()])
return normalizedscores
def linktextscore(self,rows,wordids):
linkscore=dict([(row[0],0) for row in rows])
for wordid in wordids:
cur=self.con.execute('select link.fromid,link.toid from linkwords,link where \
wordid=%d and linkwords.linkid=link.rowid' % wordid)
for (fromid,toid) in cur:
if toid in linkscores:
pr=self.co.execute('select score from pagerank where urlid=%d'
% fromid).fetchone()[0]
linkscores[toid]+=pr
maxscore=max(linkscores.values())
normalizedscores=dict([(u,float(l)/maxscore) for (u,l) in linkscores.items()])
return normalizedscores</span>














 844
844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









