






(一)操作系统环境
1、安装vm17(低版本gui界面死机)
2、安装centos 带gui界面
(二)软件环境
1、上传软件
Home下新建文件夹software,将相关软件用ftp软件copy
Home下新建app文件夹,用于安装文件
2、安装jdk1.8
解压:
[admin@localhost software]$ tar -zxvf jdk1.8.0_221.tar.gz -C /home/app/
编辑配置文件:
[admin@localhost jdk1.8.0_221]$ vi ~/.bash_profile
export JAVA_HOME=/home/app/jdk1.8.0_221
export PATH=
J
A
V
A
H
O
M
E
/
b
i
n
:
JAVA_HOME/bin:
JAVAHOME/bin:PATH
按esc,输入 :wq 保存退出
生成文件,查看
[admin@localhost jdk1.8.0_221]$ source ~/.bash_profile
[admin@localhost jdk1.8.0_221]$ echo $JAVA_HOME
/home/app/jdk1.8.0_221
3、安装scala
[admin@localhost software]$ tar -zxvf scala-2.13.11.tgz -C /home/app/
编辑配置文件:
vi ~/.bash_profile
PATH=
P
A
T
H
:
PATH:
PATH:HOME/.local/bin:
H
O
M
E
/
b
i
n
e
x
p
o
r
t
J
A
V
A
H
O
M
E
=
/
h
o
m
e
/
a
p
p
/
j
d
k
1.8.
0
2
21
e
x
p
o
r
t
P
A
T
H
=
HOME/bin export JAVA_HOME=/home/app/jdk1.8.0_221 export PATH=
HOME/binexportJAVAHOME=/home/app/jdk1.8.0221exportPATH=JAVA_HOME/bin:
P
A
T
H
e
x
p
o
r
t
S
C
A
L
A
H
O
M
E
=
/
h
o
m
e
/
a
p
p
/
s
c
a
l
a
−
2.13.11
e
x
p
o
r
t
P
A
T
H
=
PATH export SCALA_HOME=/home/app/scala-2.13.11 export PATH=
PATHexportSCALAHOME=/home/app/scala−2.13.11exportPATH=SCALA_HOME/bin:$PATH
$ source ~/.bash_profile
任意目录下输入:scala,出现输入命令界面
scala>
4、安装hadoop
$ tar -zxvf hadoop-3.2.3.tar.gz -C /home/app/
$ vi ~/.bash_profile
export HADOOP_HOME=/home/app/hadoop-3.2.3
export PATH=
H
A
D
O
O
P
H
O
M
E
/
b
i
n
:
HADOOP_HOME/bin:
HADOOPHOME/bin:PATH
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
$ source ~/.bash_profile
admin@localhost ~]$ cd
H
A
D
O
O
P
H
O
M
E
[
a
d
m
i
n
@
l
o
c
a
l
h
o
s
t
h
a
d
o
o
p
−
3.2.3
]
HADOOP_HOME [admin@localhost hadoop-3.2.3]
HADOOPHOME[admin@localhosthadoop−3.2.3] 可进入hadoop文件目录
[admin@localhost hadoop-3.2.3]$ cd etc/hadoop
编辑 hadoop-env.sh
[admin@localhost hadoop]$ vi hadoop-env.sh
# export JAVA_HOME=
export JAVA_HOME=/home/app/jdk1.8.0_221
编辑 core-site.xml
vi core-site.xml
fs.default.name
hdfs://myhost:8020
编辑 hdfs-site.xml
vi hdfs-site.xml
dfs.namenode.name.dir
/home/app/tmp/dfs/name
dfs.datanode.data.dir
/home/app/tmp/dfs/data
dfs.replication
1
编辑vi mapred-site.xml
vi mapred-site.xml
mapreduce.framework.name
yarn
编辑 vi yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
格式化节点:
[root@myhost hadoop-3.2.3]# cd bin
[root@myhost bin]# ./hadoop namenode -format
启动hadoop
[root@myhost hadoop-3.2.3]# cd sbin
[root@myhost sbin]# ./start-dfs.sh
5、安装maven
tar -zxvf apache-maven-3.6.1-bin.tar.gz -C /home/app/ 解压
配置环境变量
vi ~/.bash_profile
export MAVEN_HOME=/home/app/apache-maven-3.6.1
export PATH=
M
A
V
E
N
H
O
M
E
/
b
i
n
:
MAVEN_HOME/bin:
MAVENHOME/bin:PATH
source ~/.bash_profile
编辑:settings.xml
进入目录:apache-maven-3.6.1/conf/
vi settings.xml
在app文件夹中新建文件夹:maven_repository
/home/app/maven_repository
运行:
[root@myhost conf]# mvn
6、安装python
由于Python-3.7.4.tgz非解压就能用,在linux下需要安装
(1)解压
tar -zxvf Python-3.7.4.tgz -C /home/app/
加压后,home/app/Python-3.7.4 有文件目录
(2)在home/app下新建python3文件夹
源码的安装一般由3个步骤组成:配置(configure)、编译(make)、安装(makeinstall)。
(3)配置安装路径
[root@myhost Python-3.7.4]# ./configure --prefix=/home/app/python3
配置安装的路径,如果不配置该选项,安装后可执行文件默认放在/usr/local/bin
(4)安装
[root@myhost Python-3.7.4]#make && make install
注意:安装过程中会报错
[1]zipimport.ZipImportError: can‘t decompress data; zlib not availabl
解决:在解压后的 Python-3.7.4/Modules/Setup.dist 找到setup文件
将 #zlib zlibmodule.c -I
(
p
r
e
f
i
x
)
/
i
n
c
l
u
d
e
−
L
(prefix)/include -L
(prefix)/include−L(exec_prefix)/lib -lz
前面的#即注释去掉
[2]ModuleNotFoundError: No module named ‘_ctypes’
手动安装Python3.7及以上版本时,在make install步骤中会出现缺少依赖(缺少_ctype)的错误提示
在python3.X中用到了_ctype组件,但他又必须依赖于另外一个叫libffi-devel的组件,所以我们需要先行安装
#执行以下命令
yum install libffi-devel
会有提问,输入y
以上解决完,再次执行:make && make install
(5)配置文件
[root@myhost Python-3.7.4]#vi ~/.bash_profile
export PYTHON_HOME=/home/app/python3
export PATH=
P
Y
T
H
O
N
H
O
M
E
/
b
i
n
:
PYTHON_HOME/bin:
PYTHONHOME/bin:PATH
[root@myhost Python-3.7.4]#source ~/.bash_profile
(6)执行python
[root@myhost Python-3.7.4]#python3 注意版本号已经为最新的
7、spark安装及启动
[root@myhost bin]# tar -zxvf spark-3.2.1-bin-hadoop3.2.tgz -C /home/app/
运行
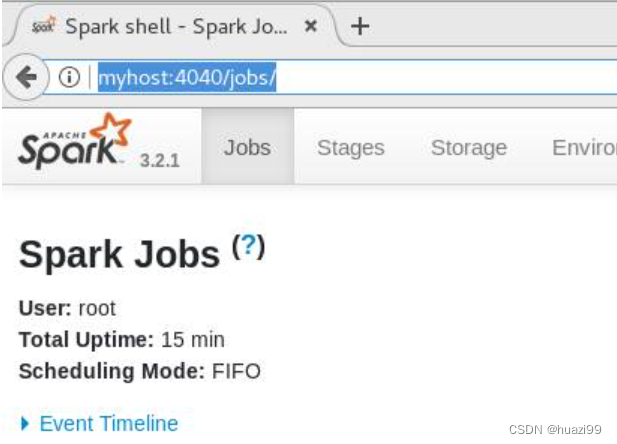
[root@myhost bin]# ./spark-shell
http://myhost:4040/jobs/
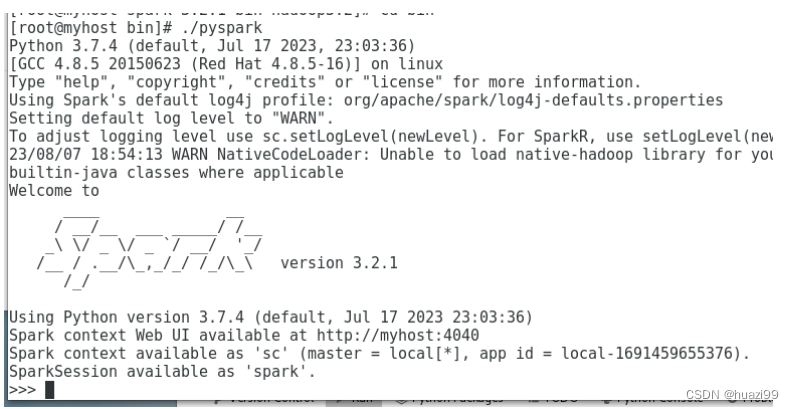
8、 pyspark启动(python3必须能正常运行)
[root@myhost spark-3.2.1-bin-hadoop3.2]# cd bin
[root@myhost bin]# ./pyspark















 1321
1321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









