






目录
概念列表

redis数据类型
redis底层使用C语言实现,所有的key都是使用string,value提供了各种各样的存储结构,使用 “object encoding type key值”可以查看value对应的数据类型,redis可以存储的key数为2的32次方,换句话来说取决于redis实例所在主机的内存大小。
String

string底层使用char[]实现,相比于C语言数据,进行了以下四点优化。
(1)不用‘\0’作为结束位判断方式,而是使用len记录数组结束位置,但是依然会在末尾追加’\0’,保证了二进制安全(二进制安全:字符串中出现\0字符,造成字符串截断)。
(2)增加len字段表示数组长度,将计算数组时间复杂度由O(n)降到O(1)。
(3)3.2版本及之后根据字符创长度分为5类实现,充分提高了空间利用比。
(4)同时使用了空间预分配和惰性空间释放来节省字符串变换进行空间重分配。
空间预分配:(当空闲空间也不能存储新的字符串长度时,需要对buf数组进行空间重分配)(1)当字符串长度小于1M时,分配空闲空间长度等于字符串长度。(2)当字符串长度大于等于1M是,分配空闲长度等于字符创长度。
惰性空间释放:将buf[0] = “\0”;len=0。单空间不会立刻回收,使用free字段标记起来。
List
第一种双向链表。
第二种压缩列表,底层是用数据实现,压缩体现在元素类型可以根据实际元素大小原则,同时又因为是有序表,又可以实现0(1)访问。

适用场景:可以作为栈和队列,消息列表,朋友圈的点赞数评论数。
set
第一种:整数集合,整型数组实现,当数据较少时使用该方式存储。
第二种:字典,使用数据加链表的方式实现,解决冲突的方法为拉链法。
适用场景:好友、粉丝、感兴趣人的集合,求交集,补集。
zset(有序集合)
第一种实现,压缩列表。
第二种实现,跳表,查询时间复杂度为0(logN),空间比红黑树大,单查效率基本和红黑树一样,实现却别红黑树简单。

适用场景:可以用来存储排行榜,和粉丝列表,粉丝的关注度为value值,可以实现按照粉丝关注度显示粉丝列表。和list排序手动根据储存顺序排序不同的是,zset排序是动态自动完成。
Hash
第一种实现压缩列表。
第二种实现字典。字典的扩容因子默认是1,收缩因子默认是0.1。
适用场景:购物车,存储对象,对象的所有属性作为value。
BitMap
适用场景:可以使用位运算简化计算的场景。
例如统计一个2亿用户连续七天签到数: https://segmentfault.com/a/1190000040177140
BloomFilter(布隆过滤器)
使用一个位图数组+m个hash函数,存储的使用使用m个hash函数得到位图存储位置并设置为1,
查询时判断key值是否存在,同样使用m个hash函数对key值进行hash,并判断每个hash位置中的值是否为有0,有零一定不存在,全部是1可能存在,可能一个另外一个key的m个hash值和当前key的hash值完全相同。优点时可以快速过滤一部key是否存在,缺点是可能进行误检测。
Hyperlog
适用场景:进行超大数进行基数统计。
基数:数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。
redis线程模型为选择单线程模型
redis单线程是相应网络IO和key值读写是单线程,redis本身吞吐量最高可达百万级,实际redis吞吐量和集群数、主机的内存、cpu和网络带宽有关。在数据持久化使用了多线程。
redis采用reactor的单reactor+handler单线程模型。redis是基于内存操作的,不需要进行磁盘IO读取,大多数操作CPU消耗非常低,多线程的频繁的上下文切换,保存线程线程和恢复线程现场消耗时间反而会降低redis吞吐量。
redis是基于内存的操作,不用线程上下文切换,多路复用是redis单线程处理速度快的原因,单线程的另外一个优点是不用考虑线程安全问题。
redis 6.0引入了多线程模型处理网络IO请求,默认io-threads-do-reads no,关闭状态。
集群方案
redis集群方案有主从模式、哨兵模式和cluster模式。
主从模式

缺点:第一,当出现主节点出现问题,不能自动选择新的master进行容灾迁移。第二,较难实现在线扩容。
哨兵模式

1 哨兵节点A发现主节点失效,哨兵节点A判定主节点主观实效(sdown),同时询问其他哨兵节点和主节点通信情况。
2 超过quorun数量的哨兵节点任务主节点主观实效,主节点被认定为客观实效(odown)。
3 选择新的主节点,通过raft算法选举出一个领头哨兵进行新主节点的迁移。
4 主节点迁移完之后,领头节点通过发布订阅的方式通知其它哨兵节点修改新主节点信息。
虽然解决了主节点失效后,动态新节点的选取和迁移,但是扩容时,数据移动量很大。
新的主节点选择原则:
(1)从所有剩余健康的从节点中,选择slave-priority优先级最高的节点,slave-priority默认值为100,设置为0则不会被推荐为主节点。
(2)弱优先级相同,则选择偏移量大的作为主节点,偏移量越大,同步的数据越完整。
(3)便偏移量也相同的情况下,选择runid较小的作为master,选择runid越小作为master。runid是一个40位16进制的字符串,每次redis重启都会重新分配一个,slave第一连接master的时候,master会将自己的runid告诉从节点,用作服务器之间通信的凭证。
clutster集群方式
当数据量大到一个redis实例存储不下时,需要对redis进行分片,将数据均匀分布到不同的节点上,redis的集群部署方式实现了redis数据的分组,每个组之间数据互不相同,组内依然采用了主从方式实现单个redis实例的高可用,当主节点宕机会自动启动从节点,每个实例组内存。

如何保证主从数据一致性
第一种:从节点第一次同步数据。

第二种 : slave断开之后再次连接master数据部分数据同步过程。

(1)当slave重启之后,首先会检查自己手里面master的runid和当前masterderunid是否一致,不一致,说明在slave实效期间,master也重启,此时需要全量同步;一致,则执行(2)。
(2)发送psync命令到master节点,同时还会将自己偏移量发送给
master,master检查slave时候的执行命令是否都在缓冲区中,不在,则执行全量同步;在,则发送“+continue”命令,通知slave节点可以进行部分数据同步。
(3)master发送slave断线后写命令给slave。
(4)slave根据master发送来的命令进行数据同步。
redis数据持久化方式
第一种是:RDB全量方式。定时存取快照信息,为了不影响应用的正常相应,原来用来响应的父进程fork出一个子进程,快照信息以二进制文件方式存储dump.rdb。触发方式有自动和手动两种,自动情况需要配置触发规则例如save m n,在m秒内更新了n个key值。优点是对容灾恢复、方便迁移。缺点是间隔存储,可能导致节点出现故障时不能进行全量的数据恢复。
第二种:AOF增量方式。每执行一条命令,都会向AOF文件换冲区末尾追加一条记录。优点是:集群出现故障宕机是,丢失的数据很少。缺点是相同的记录AOF占用更大的存储空间,当AOF非常大是,需要进行适当的压缩,否则在迁移和恢复较慢。
如何保证数据库和缓存一致性
数据库和缓存不一致时由于多线程环境下竞争条件导致的。无论是更新数据库、再更新缓存,先更新缓存再更新数据库。
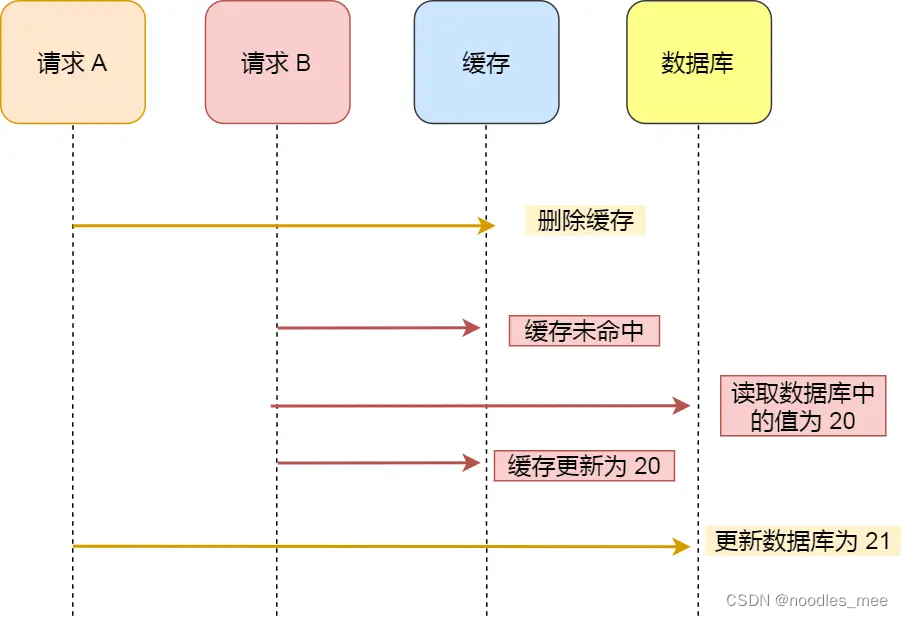
亦或是先删除缓存、再更新数据库,都会导致缓存书数据库不一致。
为了应对竞争条件造成的数据不一致,一种比较重的方式是给更新加锁,同一条记录在更新操作都要先加锁,这个操作结束后序操作才能进行。另外一种方式是,先更新数据库再删除缓存,更新缓存总是采用read-through策略。
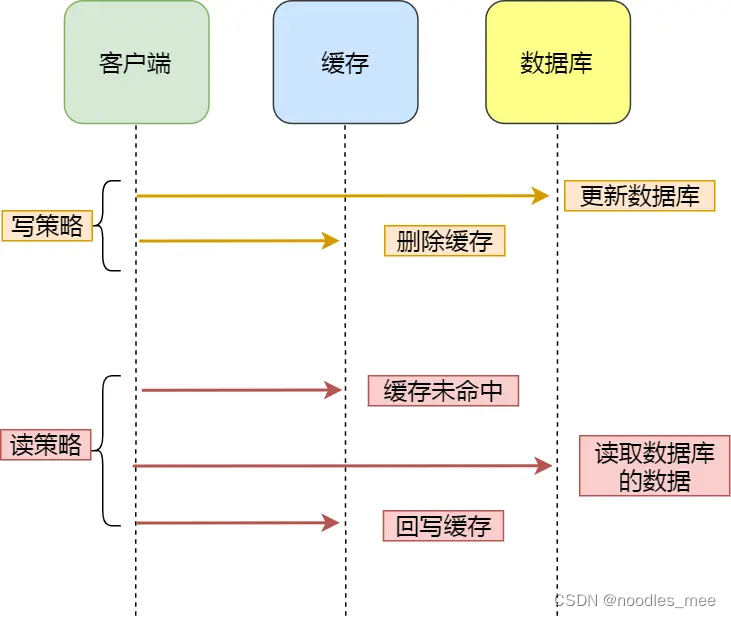
为了防止删除缓存失败,将删除缓存写入到消息队列里面,利用消息的失败重试策略,保证删除缓存操作总是成功的。

redis缓存问题
缓存淘汰时机
redis基于内存操作,大多数据都存储在内存中,当要存储缓存数据内存无法存放时,需要将一部分缓存淘汰掉(删除)。删除时机有三种触发方式:
第一种:定时删除,用一个监控器对key进行监控,key过期时触发,缺点消耗cpu。
第二种:定期删除,默认ha 10次,1秒进行10次淘汰,每次100ms,能删除几个是几个,推荐使用。
第三种:惰性删除,redis中不用配置,隐含就就使用的,当查询该key时,发现过期,会直接删除。
淘汰策略
确定了触发时机,我们希望从众多的数据中删除那些在未来使用不高的key,来提高缓存作用,通过maxmemory-policy设置key淘汰策略:
noeviction:默认,超过分配内存,直接报错。
allkey-lru:,推荐使用,对所有key按照最后一次访问时间从远到近排序,先删除最久未使用的。
volatile-lru:原理也是LRU算法,淘汰数据范围时key设置过期时间key。
allkeys-lfr:按照key的使用频率从少到多排序,优先删除使用频率低的数据。
volatile-lru:原理也是lfu,淘汰key范围时key设置了过期范围的。
allkeys-random和volatile-random:随机淘汰。
volatile-ttl:对设置了过期时间的key按照即将过期时间从早到晚进行排序,最早到期的key优先被删除。
三种缓存失去作用问题
第一种:缓存雪崩,大量的key在在同一时间失效,大量请求涌向数据库,解决办法,增加key实效时间实效的随机性。
第二种:缓存击穿,热点数据实效了。同一个时间大量请求查询热点数据的请求涌向数据库,将热点数据设置为永不过期,或者定时的刷新热点数据的过期时间。
第三种:缓存穿透,恶意查询大量不存在的数据。解决办法1):在业务层使用分布式锁、2):将不存在的数据也写入缓存、3):使用布隆过滤器。
redis事务实现
redis事务开始是MULIT,命令1, 命令2,命令3,命令4 exec【discard|watch|unwatch】,mulit是事务开始标志,命令并不立即执行,而是放在一个队列里面,当输入了exec,所有命令才会依次执行。redis在执行事务的时候,其他请求都要阻塞,所以一般很少使用redis事务。
当执行redis执行过程中即使某条命令发生错误,也不会停止或回滚,而是继续执行后续命令。redis不支持事务回滚官网解释:1)这和redis简单和高效的设计原则不符。2)事务中发生的错误一般是编译器错误,这在开发环境中就可以发现,认为在redis事务发生错误的概率非常低。
WATCH可以一直监控一个或者多个key是否发生改变,如果发生改变,整个事务执行失败,和java中volatile作用类似。
Redis分布式锁实现
加锁实现: 通过SETNX和 expire或者setnx和setex命令组实现加锁,单独执行但是无法保证两条指令的原子性,如果保存完key和value之后,失效时间设置失败,应用异常重启redis实例,则锁永远无法释放。
解决办法1:redis 2.6.12版本之后,可以使用命令set key value [EX seconds][PX milliseconds][NX]可以完成同时设置key和key的过期时间。
解决办法2:使用lua脚本,redis支持Lua脚本,当应用中要一次执行多条指令时,考虑使用Lua脚本。
释放锁: 只有加锁的线程才能删除key,所以加锁时设置的value需要具有全局唯一性,一般发号器uuid作为value值,通过判断释放锁的value和锁的value值判断是否为同一个加锁线程。
失效时间: key失效时间一般大于接口调用的超时时间,当接口超时后,锁的对应key失效,可能会引起线程安全问题。Redission创建锁的时候,默认加锁时间是30秒,同时创建一个定时守护线程,当超过1/3(10秒),发现锁还没有释放,加锁时间会自动延长成30秒,同时为了防止锁一直不释放,在执行加锁的tryLock时设置了具体的释放时间leaseTime,超过这个时间锁自动释放。同时redission还实现了重入锁,实现方式类似于AQS计数器原理。
加锁主从同步失败: 在主从同步部署模式下,主节点在将锁同步到从节点之前出现问题,新选择的主节点没有锁的信息,将出现多线程不安全问题。解决办法是,使用多集群加锁,彼此多个集群之间需要进行数据同步,RedLock实现了向多集群加锁安全。RedLock的思想是,向N个集群节点依次加锁时,超过一定时间则跳过,只要加锁成功数大于集群数N/2+1,则认为加锁成功,否则加锁失败。
| MySQL分布式锁 | redis实现分布式锁 | |
|---|---|---|
| 优点 | 实现简单,需用引入新的组件 | 实现简单,自带枷锁失败锁自动延期功能,响应快,吞吐量高 |
| 缺点 | 1、没有 加锁失败重试机制;2也没有自动释放锁和锁自动延期机制,需要编码实现3、并发性低,当同时有枷锁操作,对DB压力大 | 1 一定程度引入系统复杂度 |
如何实现锁的重入:
redis中实现锁的重入和Java中的Synchronized和ReentrantLock锁的机制是一样的,需要使用一个唯一性Id标志锁的持有者,同时一个计数器标志锁重入的次数,整个锁可以设计为key list(分布式环境中唯一行线程id、重入次数、失效时间),锁解除时,当计数器减为0,释放锁,世纪开发中可以直接使用redis封装好可重入锁redission客户端。
业务使用场景: 并非操作,重复操作对结果有影响,比如商品下单减库存,本来只有一个商品,多售卖是不允许的,运营老师同时修改一个商品价格,即使存在并发问题,重复操作,只有两个老师后面都再刷新了,都可以看到彼此修改的结果,没有很大影响。














 2108
2108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









