







08:30到达实验室 24:00左右离开
切片操作中:[]中,逗号,区分的是维度,冒号:区分的是索引,省略号… 用来代替全索引长度
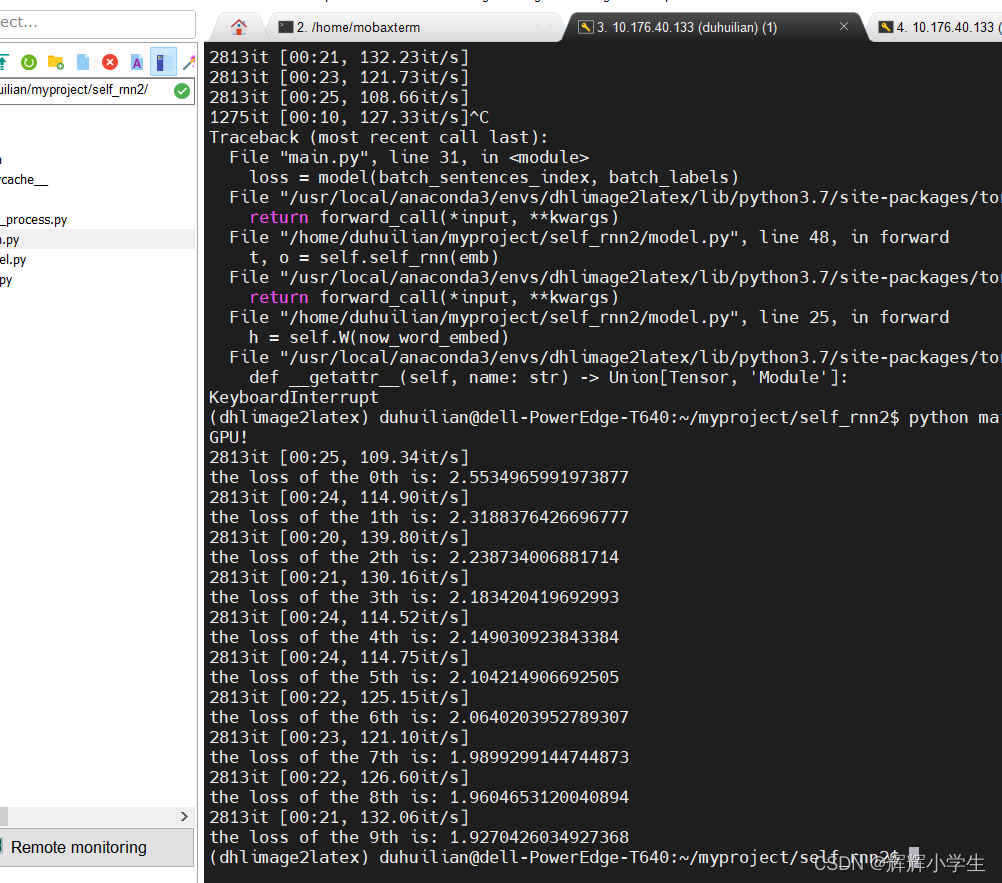
rnn 文本分类终于跑完了
古诗生成:
正则表达式:
#pattern = re.compile(r"[0123456789]") #0到9 #pattern = re.compile(r"[0-9]") #0到9 #pattern = re.compile(r"[a-z]") # a到z #pattern = re.compile(r"[A-Z]") # A到Z #pattern = re.compile(r"[\-]") #匹配横杠 #pattern = re.compile(r"[^0-9]") #匹配非数字 ^代表取反 #pattern = re.compile(r"\d") #所有数字 \D取反 #pattern = re.compile(r"\w") #所有汉字字母数字 下划线 \W取反 #pattern = re.compile(r"\s") #匹配空格 #pattern = re.compile(r"\b\D\b") #匹配有边界的目标词 即两边都是空格
pattern1 = re.compile(r"^python") # 以什么开始
pattern2 = re.compile(r"python$") # 以什么结束
result1 = pattern1.findall("python python")
result2 = pattern1.findall("python python")
pattern1 = re.compile(r".ar$") # .代表除了\n以外的任何字符
result1 = pattern1.findall("python python star")
pattern1 = re.compile(r"honou?r") # ?可选字符 0次或1次
result1 = pattern1.findall("which is right honour or honor? or honouuur")
pattern1 = re.compile(r"\d{9}") # 匹配九个数字
result1 = pattern1.findall("23948093285094328509432850943859")
pattern1 = re.compile(r"\d{8,9}") # 八、九个数字 遇到九个只匹配九个
result1 = pattern1.findall("23948093285094328509432850943859")
pattern1 = re.compile(r"\d{8,9}?") # 八、九个数字 匹配八个 非贪婪模式
result1 = pattern1.findall("23948093285094328509432850943859")
pattern1 = re.compile(r"\d{1,}?") # *等于{0,}0到无穷大 +等于{1,} 1到无穷大
result1 = pattern1.findall("23948093285094328509432850943859")
pattern1 = re.compile(r"^1[34578]\d{9}")
#匹配所有电话号码 第一位1 第二位34578 后面九个0-9
result1 = pattern1.findall("15927433677")
pattern1 = re.compile(r"^http.*/$") # http 开头 /结尾的数据
result1 = pattern1.findall("https://mp.csdn.net/mp_blog/creation/")
进阶:
pattern1 = re.compile(r"\d{4}-\d{7}") # 匹配下面的电话号码
result1 = pattern1.findall("张三:0731-8283333")
pattern1 = re.compile(r"<div>(.*?)</div>") # 用括号将需要的内容提取出来
result1 = pattern1.findall("<div>dhl</div>")
#|是或者
同门教我写的爬虫:
import json
import re
import jsonlines
import requests
from bs4 import BeautifulSoup
if __name__=="__main__":
for i in range(6000):
try:
data=requests.get("https://www.jyznl.cn/"+str(i)+".html").text
soup=BeautifulSoup(data,'html.parser')
title=soup.find('title').text
print(title)
content_list=soup.findAll(name="div",attrs={"class":"entry-content u-clearfix"})
results=soup.select('div[class="entry-content u-clearfix"] p')
print(results)
tem_dict={}
tem_dict['title']=title
tem_content=""
tem_dict['paper_id']=i
for i,tem in enumerate(results):
if(i<len(results)-1):
tem_content+=tem.text
tem_dict['content']=tem_content
with jsonlines.open('test.jsonlines','a') as f:
# json_str=json.dumps(tem_dict,ensure_ascii=False)
# f.write(json_str)
f.write(tem_dict)
f.close()
except:
pass
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









