multimodel relation extraction to solve the influence of lack of contexts(visaul contents to supplement the missing semantics)
develop a dual graph alignment method to capture this correlation for better performance
1 INTRODUCTION
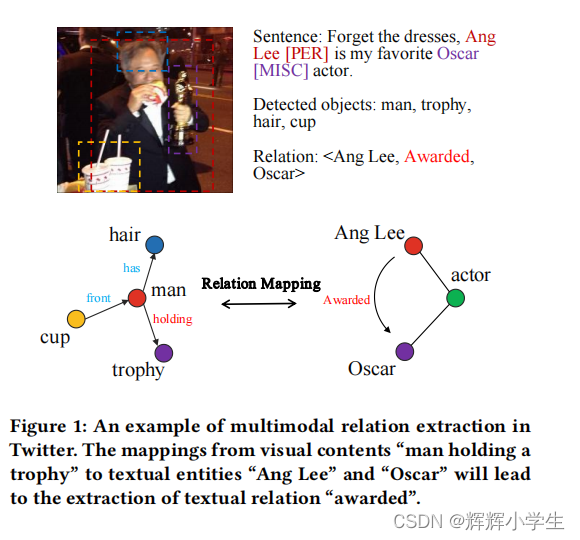
Different from multimodal named entity recognition task, introducing visual information into relation extraction asks models not only to capture the correlations between visual objects and textual entities, but also to focus on the mappings from visual relations between objects in an image to textual relationsbetween entities in a sentence.(很绕,我把例子也摆上来)
contributions:
present the multimodal relation extraction (MRE) task;provide a human-annotated dataset
(MNRE)
propose a multimodal relation extraction neural network with efficient alignment strategy for textual and visual graphs
conduct experiment on the MNRE dataset
2 RELATED WORKS
2.1 Relation Extraction in Social Media
2.2 Multimodal Representation and Alignment
assign the graph similarity computed by both structural similarity and semantic agreement
3 METHODOLOGY
steps to build model:
1.
extract the textual semantic representations with a pretrained BERT encoder
we generate the scene graphs (structural representations) from images which provide rich visual information including visual objects features and visual relations among the objects.
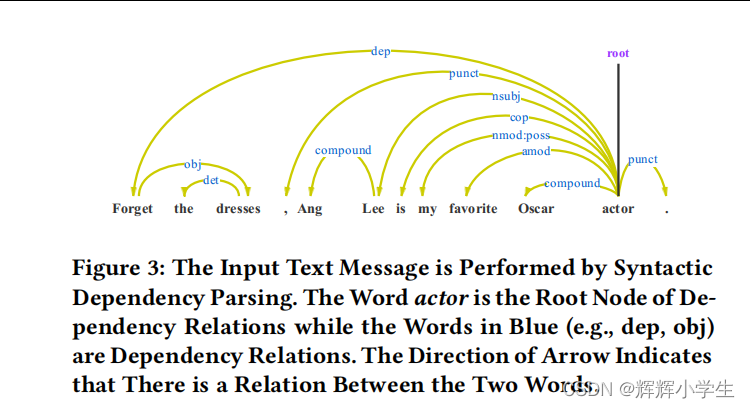
2.to acquire the structural representations, we obtain the syntax dependency tree of the input texts which models the syntax structure of textual information. The visual object relation extracted by scene graph can be constructed as a structural graph representation.3.to make good use of image information for multimodal relation extraction, we respectively align the structural and semantic information of multimodal features to capture the multi-perspective correlation between multimodal information.
4.we concatenate the textual representations which represent the two entities and the alignedvisual representation as the fusion feature of text and image to predict the relations of entities.
3.1 Semantic Feature Representation
3.1.1 Textual Semantic Representation.
The input text message is first tokenized into a token sequence 𝑠1
to fit the BERT encoding procedure, we add the token ’[CLS]’ ‘[SEP]’
we augment the 𝑠1 with four reserved word pieces, [𝐸1𝑠𝑡𝑎𝑟𝑡], [𝐸1𝑒𝑛𝑑 ], [𝐸2𝑠𝑡𝑎𝑟𝑡] and [𝐸2𝑒𝑛𝑑 ]











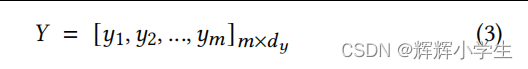
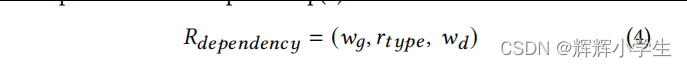
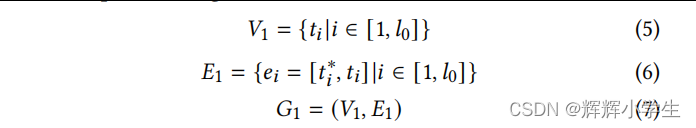

















 3493
3493











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









