










文章目录
HBase Shell常用操作
HBase Shell删除是按住Ctrl+删除键
启动HBase
hbase shell
创建表
create 'test','info'
查看表
list_namespace
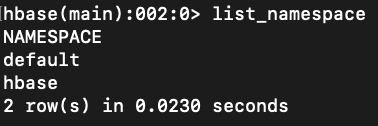

创建命名空间
create_namespace 'ns1'
list_namespace
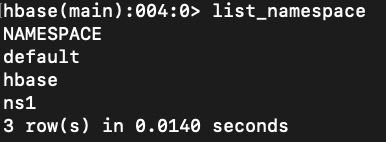
在命名空间(类似数据库的概念)里创建表
create 'ns1:ns1_tb1','cf1'
list
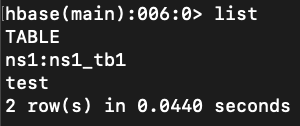
查看HBase系统自带表
list_namespace_tables 'default'
list_namespace_tables 'hbase'

查看表是否存在
exists 'User'
删除表
- 删除表分为两步
## 禁用表
disable 'ns1:ns1_tb1'
drop 'ns1:ns1_tb1'

enable ‘ns1:ns1_tb1’
表示启用表
插入数据
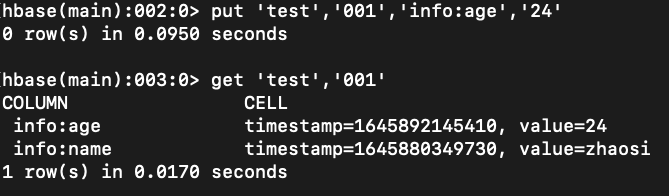
put 'test','000','info:name','zhangsan'
put 'test','001','info:name','zhaosi'
put 'test','002','info:name','wangwu'
put 'test','003','info:name','mazi'
获取数据
get 'test','001'

put 'test','001','info:age','24'
get 'test','001'
查看表结构
desc 'test'

- NAME => ‘info’——列簇名
- BLOOMFILTER => ‘ROW’——过滤器
- VERSIONS => ‘1’——版本
- IN_MEMORY => ‘false’——是否放到内存里面
- KEEP_DELETED_CELLS => ‘FALSE’——是否保持删除的单元格
- DATA_BLOCK_ENCODING => ‘NONE’——编码
- TTL => ‘FOREVER’——存活时间
- COMPRESSION => ‘NONE’——开启压缩
- MIN_VERSIONS => ‘0’——最小版本号
- BLOCKCACHE => ‘true’——块缓存
- BLOCKSIZE => ‘65536’——块大小
- REPLICATION_SCOPE => ‘0’——块大小复制范围

创建列簇(多个)
create 'test1',{NAME=>'info',VERSIONS=>'3'}
- 创建一个表后面有两个列簇
create 'test2','cf1','cf2'

获取数据、获取多版本
- 获取数据
get 'test','000'
- 获取多版本数据
get 'test1','000',{COLUMN=>'info',VERSIONS=>10}

- 配合下面的删除
put 'test','000','info:age',21
put 'test','000','info:age',22
put 'test','000','info:age',23
get 'test','000'
get 'test','000',{COLUMN=>'info',VERSIONS=>3}

- 删除
delete 'test','000','info:age'
get 'test','000'
delete 'test','000','info:age'
get 'test','000'

以上就是我们多版本的问题
并没有真正的删除
删除
- 删除列
delete 'test','000','info:name'
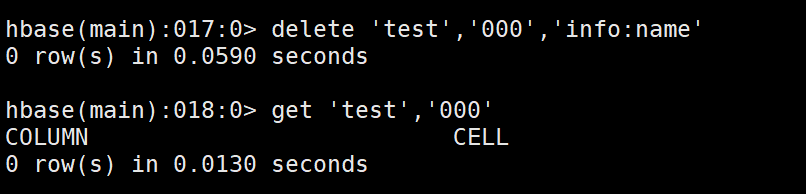
- 指定rowkey删除
deleteall 'test','000'
get 'test','000'
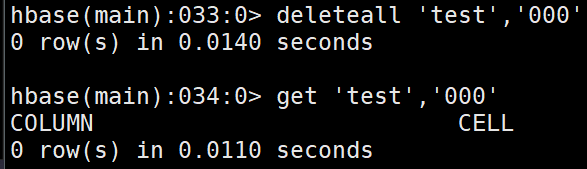
- 删除表中所有数据
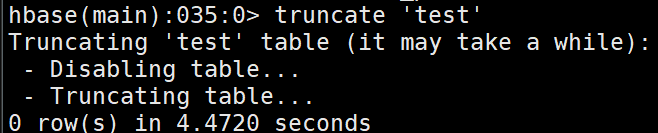
表的预分区被重置成一个分区
truncate 'test'
表修改
删除指定的列簇
alter 'test3','delete'=>'info'
增加新的列簇
alter 'test3',NAME=>'cf1'



全盘扫描
create 'test4','cf'
put 'test4','000','cf:name','zhangsan'
put 'test4','001','cf:name','lisi'
put 'test4','002','cf:name','wanger'
put 'test4','003','cf:name','mazi'
#全盘扫描
scan 'test4'

scan 'test4',{LIMIT=>3}
put 'test4','0','cf:id',0
put 'test4','1','cf:id',1
put 'test4','2','cf:id',2
put 'test4','3','cf:id',3
scan 'test4',{LIMIT=>10}

三维有序
- ROW——按位升序
- COLUMN——ASCII码降序
- timestamp——时间戳降序
put 'test4','10000000000','cf:h',10000000000
put 'test4','10000000000','cf:i',10000000000
put 'test4','10000000000','cf:j',10000000001
put 'test4','10000000000','cf:k',10000000002
scan 'test4'

scan 'test4',{STARTROW=>'000',ENDROW=>'003',LIMIT=>2}

统计表记录数
语法:count
, {INTERVAL => intervalNum, CACHE => cacheNum}
INTERVAL设置多少行显示一次及对应的rowkey,默认1000;CACHE每次去取的缓存区大小,默认是10,调整该参数可提高查询速度。
count 'test4'
count 'test4',{INTERVAL=>1000,CACHE=>10}

到底啦!关注靓仔学习更多的大数据知识!( •̀ ω •́ )✧
















 2675
2675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











