




一 程序的目的
/***
*该程序的目的是:
* 将 一个pcm文件 和 一个 yuv文件,合成为一个 0804_out.mp4文件
* pcm文件和yuv文件是从哪里来的呢?是从 sound_in_sync_test.mp4 文件中,使用ffmpeg命令 抽取出来的。
* 这样做的目的是为了对比前后两个mp4(sound_in_sync_test.mp4 和 0804_out.mp4 ) 文件。
*
* 1. 从sound_in_sync_test.mp4 文件 中抽取 pcm命令如下:
* ffmpeg -i sound_in_sync_test.mp4 -vn -ar 44100 -ac 2 -f s16le 44100_2_s16le.pcm
* -vn 表示不处理视频
*
* 2. 从sound_in_sync_test.mp4 文件 中抽取 yuv命令如下:
*
* ffmpeg -i sound_in_sync_test.mp4 -pix_fmt yuv420p 720x576_yuv420p.yuv
*
* 3.播放测试
* 对于 pcm 数据
ffplay -ac 2 -ar 44100 -f s16le 44100_2_s16le.pcm
* 对于 YUV 数据
ffplay -pixel_format yuv420p -video_size 720x576 -framerate 25 720x576_yuv420p.yuv
***/
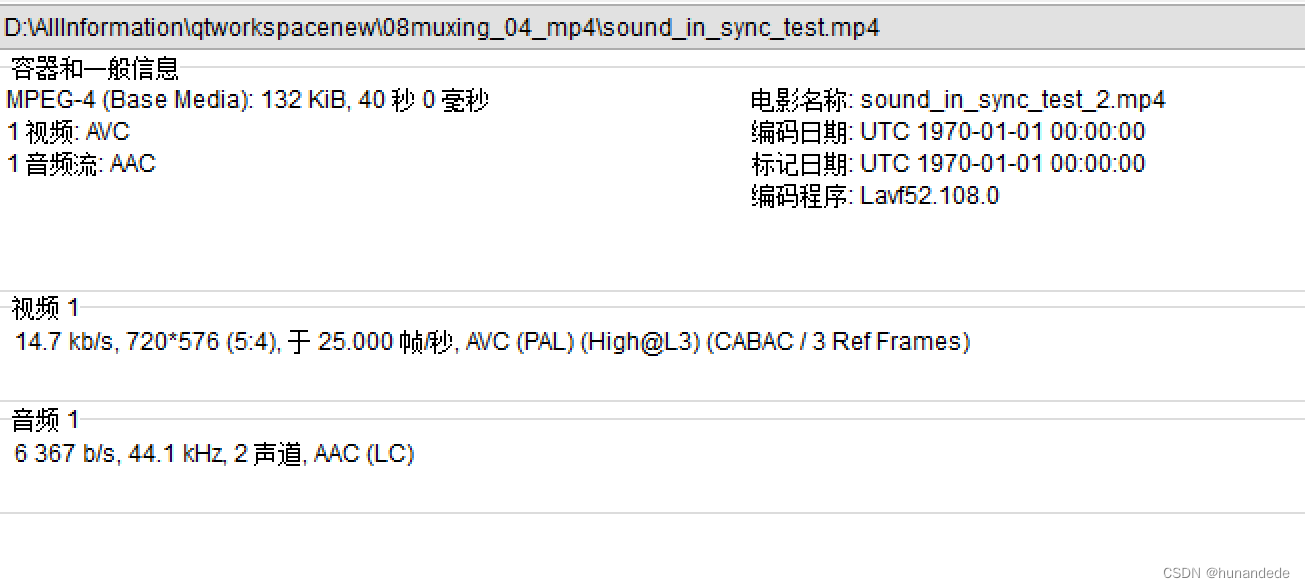
原始 sound_in_sync_test.mp4 的信息
二 流程 以及 思路

整体思路是这样的:
1. 将video 的yuv数据,变成avframe,然后变成avpacket,
2. 然后需要将avpacket 通过 av_write_frame(this->_avformatContext,avpacket); 发送出去,那么这就需要有 avformatContext。顺便要有avstream,
3. 对于video 来pcm数据来说,应该还需要 audioresample
设计思路
1. 视频编码相关类 videoencoder.h
///设计思路:该函数的作用是,将yuv_data数据存储到 avframe中,然后将avframe中的数据发送到 编码器上下文,经过编码后变成 avpacket。
///核心函数1:初始化h264,要初始化h264,核心是找到编码器;初始化编码器上下文;设置编码器上下文参数;而设置编码器参数,如下的5个参数都需要
/// yuv视频的宽 yuvwidth,yuv视频的高 yuvheight, yuv视频格式 AVPixelFormat yuvpix_fmt, yuv视频fps int yuvfps,视频 比特率 video_bit_rate
/// int InitH264(int yuvwidth, int yuvheight, AVPixelFormat yuvpix_fmt, int yuvfps, int video_bit_rate);
/// 在初始化中,我们还可以定义一个类变量avframe,顺便设定avframe的参数,为了后续方便使用 avframe 做准备。
/// 此方法中和 audio 不同的一点是,会设置 avcodecContext的timebase为1000000,这是因为
///核心函数2:将yuv数据变成 avpacket
///第一个参数为 yuv_data,是一张yuv数据的指针,
/// 第二个参数为 第一个参数yuv_data的大小
/// 第三个参数为 avstream中 video_index,这个参数从 avstream中获得,通过muxer内部变量传递过来,作用是 给avpacket设置 video_index。
/// 第四个参数为 yuv数据一帧图片需要花费的时间,当yuv_fps为25时候,那么一帧数据显示的时刻就是 1/25秒,也就是1000000 * (1/25) 微秒,注意时间。
/// 那么第一张yuv图片 pts 就是 40 000 微秒,
/// 第二章yuv图片 pts 就是 80 000 微秒,
/// 第四个参数 pts 是yuv数据的 读取到这时候的时间,参考调用时候 double video_frame_duration = 1.0/yuv_fps * video_time_base;
/// 第五个参数为 yuv数据的时间基,我们设定为 1000000
/// 第四个参数和第五个参数的目的是:使用 yuv的pts 和 yuv 的时间基 转化成 avframe的 pts,这里需要使用到 avcodecContex的timebase,这个avcodecContext 的timebase 是在前面 InitH264 函数中设定的。
/// 注意,video的avcodecContext的timebase 和 audio 的avcodecContext 的timebase 获得方式是不同的,
/// audio 的avcodecContext 的timebase 是 ffmpeg 中在avcodec_open2方法中设定的,video的avcodecContext 的timebase 是程序员自己设定的
/// 然后存储于到 最后一个参数 vector<AVPacket *> 中
/// return 小于0没有packet
/// int videoencoder::Encode(uint8_t *yuv_data, int yuv_size,int stream_index, int64_t pts, int64_t time_base,std::vector<AVPacket *> &packets)
videoencoder.h 代码
#ifndef VIDEOENCODER_H
#define VIDEOENCODER_H
///设计思路:该函数的作用是,将yuv_data数据存储到 avframe中,然后将avframe中的数据发送到 编码器上下文,经过编码后变成 avpacket。
///核心函数1:初始化h264,要初始化h264,核心是找到编码器;初始化编码器上下文;设置编码器上下文参数;而设置编码器参数,如下的5个参数都需要
/// yuv视频的宽 yuvwidth,yuv视频的高 yuvheight, yuv视频格式 AVPixelFormat yuvpix_fmt, yuv视频fps int yuvfps,视频 比特率 video_bit_rate
/// int InitH264(int yuvwidth, int yuvheight, AVPixelFormat yuvpix_fmt, int yuvfps, int video_bit_rate);
/// 在初始化中,我们还可以定义一个类变量avframe,顺便设定avframe的参数,为了后续方便使用 avframe 做准备。
/// 此方法中和 audio 不同的一点是,会设置 avcodecContext的timebase为1000000,这是因为
///核心函数2:将yuv数据变成 avpacket
///第一个参数为 yuv_data,是一张yuv数据的指针,
/// 第二个参数为 第一个参数yuv_data的大小
/// 第三个参数为 avstream中 video_index,这个参数从 avstream中获得,通过muxer内部变量传递过来,作用是 给avpacket设置 video_index。
/// 第四个参数为 yuv数据一帧图片需要花费的时间,当yuv_fps为25时候,那么一帧数据显示的时刻就是 1/25秒,也就是1000000 * (1/25) 微秒,注意时间。
/// 那么第一张yuv图片 pts 就是 40 000 微秒,
/// 第二章yuv图片 pts 就是 80 000 微秒,
/// 第四个参数 pts 是yuv数据的 读取到这时候的时间,参考调用时候 double video_frame_duration = 1.0/yuv_fps * video_time_base;
/// 第五个参数为 yuv数据的时间基,我们设定为 1000000
/// 第四个参数和第五个参数的目的是:使用 yuv的pts 和 yuv 的时间基 转化成 avframe的 pts,这里需要使用到 avcodecContex的timebase,这个avcodecContext 的timebase 是在前面 InitH264 函数中设定的。
/// 注意,video的avcodecContext的timebase 和 audio 的avcodecContext 的timebase 获得方式是不同的,
/// audio 的avcodecContext 的timebase 是 ffmpeg 中在avcodec_open2方法中设定的,video的avcodecContext 的timebase 是程序员自己设定的
/// 然后存储于到 最后一个参数 vector<AVPacket *> 中
/// return 小于0没有packet
/// int videoencoder::Encode(uint8_t *yuv_data, int yuv_size,int stream_index, int64_t pts, int64_t time_base,std::vector<AVPacket *> &packets)
#include "iostream"
using namespace std;
extern "C" {
#include "libavutil/avassert.h" // include 后面<> 表示会从标准库路径中查找指定的文件,""表示从当前当前目录(即包含 #include 指令的文件所在的目录)中查找指定的文件
#include "libavutil/channel_layout.h"
#include "libavutil/opt.h"
#include "libavutil/mathematics.h"
#include "libavutil/timestamp.h"
#include "libswscale/swscale.h"
#include "libswresample/swresample.h"
#include "libavutil/error.h"
#include "libavutil/common.h"
#include "libavcodec/avcodec.h"
#include "libavformat/avformat.h"
#include "libavutil/imgutils.h"
}
#include <vector>
class videoencoder
{
public:
videoencoder();
~videoencoder();
//该函数的作用是 找到h264编码器,通过h264编码器上下文,打开h264编码器上下文,设置h264编码器上下文参数,分配avframe,以及设置avframe参数
int InitH264(int yuvwidth, int yuvheight, AVPixelFormat yuvpix_fmt, int yuvfps, int video_bit_rate);
void DeInit();
///第一个参数为 yuv_data,是yuv数据的指针,
/// 第二个参数为 第一个参数yuv_data的大小
/// 第三个参数为 avstream中 video_index
/// 第四个参数为 yuv数据一帧图片需要花费的时间,当yuv_fps为25时候,那么一帧数据显示的时刻就是 1/25秒,也就是1000000 * (1/25) 微秒,注意时间。
/// 那么第一张yuv图片 pts 就是 40 000 微秒,
/// 第二章yuv图片 pts 就是 80 000 微秒,
/// 第四个参数 参考调用时候 double video_frame_duration = 1.0/yuv_fps * video_time_base;
/// 第五个参数为 时间基 1000000
/// 该函数的作用是,将yuv_data数据存储到 avframe中,然后将avframe中的数据发送到 编码器上下文,经过编码后变成 avpacket。返回该avpacket
AVPacket *Encode(uint8_t *yuv_data, int yuv_size,
int stream_index, int64_t pts, int64_t time_base);
///第一个参数为 yuv_data,是yuv数据的指针,
/// 第二个参数为 第一个参数yuv_data的大小
/// 第三个参数为 avstream中 video_index
/// 第四个参数为 yuv数据一帧图片需要花费的时间,当yuv_fps为25时候,那么一帧数据显示的时刻就是 1/25秒,也就是1000000 * (1/25) 微秒,注意时间。
/// 那么第一张yuv图片 pts 就是 40 000 微秒,
/// 第二章yuv图片 pts 就是 80 000 微秒,
/// 第四个参数 参考调用时候 double video_frame_duration = 1.0/yuv_fps * video_time_base;
/// 第五个参数为 时间基 1000000
/// 该函数的作用是,将yuv_data数据存储到 avframe中,然后将avframe中的数据发送到 编码器上下文,经过编码后变成 avpacket。
/// 然后存储于到 最后一个参数 vector<AVPacket *> 中
/// 小于0没有packet
int Encode(uint8_t *yuv_data, int yuv_size, int stream_index, int64_t pts, int64_t time_base,
std::vector<AVPacket *> &packets);
AVCodecContext *GetCodecContext();
private:
int _width = 0;
int _height = 0;
AVPixelFormat _pix_fmt = AV_PIX_FMT_NONE;
int _fps = 25; // 这个默认值,也不会用到,所有的参数都会在构造方法中传递真正的参数
int _bit_rate = 500*1024; // 这个默认值,也不会用到,所有的参数都会在构造方法中传递真正的参数
int64_t _pts = 0;
AVCodecContext * _avcodecContext = NULL;
AVFrame *_avframe = NULL;
AVDictionary *_avdictionary = NULL;
};
#endif // VIDEOENCODER_H
videoencoder.cpp
#include "videoencoder.h"
videoencoder::videoencoder()
{
}
videoencoder::~videoencoder()
{
if(this->_avcodecContext) {
DeInit();
}
}
int videoencoder::InitH264(int yuvwidth, int yuvheight, AVPixelFormat yuvpix_fmt, int yuvfps, int video_bit_rate)
{
int ret =0;
cout <<" videoencoder.InitH264 call yuvwidth = " << yuvwidth
<<" yuvheight = "<< yuvheight
<<" yuvpix_fmt = " << yuvpix_fmt
<<" yuvfps = " <<yuvfps
<<" video_bit_rate = " << video_bit_rate
<< endl;
//1.使用VideoEncoder内部的变量记住 传递进来的值
this->_width = yuvwidth;
this->_height = yuvheight;
this->_pix_fmt = yuvpix_fmt;
this->_fps = yuvfps;
this->_bit_rate = video_bit_rate;
//2.找到视频编码器
const AVCodec * avcodec = avcodec_find_encoder(AV_CODEC_ID_H264);
if(avcodec == nullptr){
ret = -1;
cout<<" func InitAAC error because avcodec_find_encoder(AV_CODEC_ID_H264) error "<<endl;
return ret;
}
//3.通过视频编码器找到视频编码器上下文
this->_avcodecContext = avcodec_alloc_context3(avcodec);
if(_avcodecContext == nullptr){
ret = -1;
cout<<" func InitAAC error because avcodec_alloc_context3(avcodec) error "<<endl;
return ret;
}
//3.1 设定 视频编码器上下文 的参数,这里除了要设定 三要素之外,需要设置 flag 的值为 AV_CODEC_FLAG_GLOBAL_HEADER
_avcodecContext->width = yuvwidth;
_avcodecContext->height = yuvheight;
_avcodecContext->pix_fmt = yuvpix_fmt;
_avcodecContext->framerate = {yuvfps, 1};
///AV_CODEC_FLAG_GLOBAL_HEADER参数相关--中文翻译:将全局标头放置在extradata中,而不是每个关键帧中。
///这里要明白为什么加这个参数,需要知道如下的两个知识点:
/// 1. mp4文件中的 aac 是不带 adst header的,因此我们在将 aac 合成为mp4的时候,不能给每个aac帧的前面加 adst header
/// 2. AV_CODEC_FLAG_GLOBAL_HEADER 参数的含义就是:将全局标头放置在extradata中,而不是每个关键帧中。,对于aac来说,在每一帧的前面不加 adst header
/// 这里扩展一下h264,对于h264,有Annexb 和 AVCC 两种存储模式,MP4中的存储的是h264是AVCC格式的,AVCC格式是只有一个头文件在最前面,后面的都是h264纯数据,因此,h264编码成mp4的时候,应该也需要添加 AV_CODEC_FLAG_GLOBAL_HEADER这个标志flag
_avcodecContext->flags |= AV_CODEC_FLAG_GLOBAL_HEADER;
// 视频的 如果不主动设置:The encoder timebase is not set
_avcodecContext->time_base = {1, 1000000}; // 单位为微妙
///设置比特率
_avcodecContext->bit_rate = video_bit_rate;
///设置 gop 的大小 和 fps一致。gop size 可以是fps的整数倍
_avcodecContext->gop_size = yuvfps;
//设置所有的 图像没有b帧
_avcodecContext->max_b_frames = 0;
//设置 aac 额外的参数,通过 _avdictionary设置
// av_dict_set(&_avdictionary, "tune", "zerolatency", 0);
//4.打开编码器上下文
ret = avcodec_open2(_avcodecContext, NULL, &_avdictionary);
if(ret != 0) {
char errbuf[1024] = {0};
av_strerror(ret, errbuf, sizeof(errbuf) - 1);
printf("avcodec_open2 failed:%s\n", errbuf);
return -1;
}
//5.分配 avframe内存,为什么要在这里分配呢?
this->_avframe = av_frame_alloc();
if(!_avframe) {
printf("av_frame_alloc failed\n");
return -1;
}
_avframe->width = _width;
_avframe->height = _height;
_avframe->format = _avcodecContext->pix_fmt;
printf("Inith264 success\n");
return ret;
}
void videoencoder::DeInit()
{
if(this->_avcodecContext) {
avcodec_free_context(&_avcodecContext);
}
if(this->_avframe) {
av_frame_free(&_avframe);
}
if(this->_avdictionary) {
av_dict_free(&_avdictionary);
}
}
///第一个参数为 yuv_data,是yuv数据的指针,
/// 第二个参数为 第一个参数yuv_data的大小
/// 第三个参数为 avstream中 video_index
/// 第四个参数为 yuv数据一帧图片需要花费的时间,当yuv_fps为25时候,那么一帧数据显示的时刻就是 1/25秒,也就是1000000 * (1/25) 微秒,注意时间。
/// 那么第一张yuv图片 pts 就是 40 000 微秒,
/// 第二章yuv图片 pts 就是 80 000 微秒,
/// 第四个参数 参考调用时候 double video_frame_duration = 1.0/yuv_fps * video_time_base;
/// 第五个参数为 时间基 1000000
/// 该函数的作用是,将yuv_data数据存储到 avframe中,然后将avframe中的数据发送到 编码器上下文,经过编码后变成 avpacket。
AVPacket *videoencoder::Encode(uint8_t *yuv_data,
int yuv_size,
int stream_index,
int64_t pts,
int64_t time_base)
{
if(!this->_avcodecContext) {
printf("codec_ctx_ null\n");
return NULL;
}
int ret = 0;
/// 时间基 转换, 当第一帧的时候: pts = 40000;
/// 视频编码器上下文的 time_base是user自己设定的,音频编码器上下文中的timebase是 ffmpeg在 avcodec_open2 方法中实现的。
/// 但是视频编码器上下文的time_base并没有在 ffmpeg源码中实现,需要user自己设置,我们在前面的代码中已经设置了
/// 前面设置的timebase为1,1000000 : _avcodecContext->time_base = {1, 1000000}
/// 计算值:第一帧时候重新计算的pts的值为: (40000 *(1/1000000)) / (1/1000000) = 40000
/// 那为什么还要计算呢?
pts = av_rescale_q(pts, AVRational{1, (int)time_base}, _avcodecContext->time_base);
this->_avframe->pts = pts;
//将yuv_data数据填充到avframe中,调用的时候有两种方式,一种是yuv_data真的有数据,一种是yuv_data的值为nullptr,目的是刷新编码器上下文
if(yuv_data){
int ret_size = av_image_fill_arrays(this->_avframe->data, this->_avframe->linesize,
yuv_data, (AVPixelFormat)this->_avframe->format,
this->_avframe->width, this->_avframe->height, 1);
if(ret_size != yuv_size) {
printf("ret_size:%d != yuv_size:%d -> failed\n", ret_size, yuv_size);
return NULL;
}
ret = avcodec_send_frame(this->_avcodecContext, this->_avframe);
} else {
ret = avcodec_send_frame(this->_avcodecContext, NULL);
}
if(ret != 0) {
char errbuf[1024] = {0};
av_strerror(ret, errbuf, sizeof(errbuf) - 1);
printf("avcodec_send_frame failed:%s\n", errbuf);
return NULL;
}
AVPacket *packet = av_packet_alloc();
ret = avcodec_receive_packet(this->_avcodecContext, packet);
if(ret != 0) {
char errbuf[1024] = {0};
av_strerror(ret, errbuf, sizeof(errbuf) - 1);
printf("h264 avcodec_receive_packet failed:%s\n", errbuf);
av_packet_free(&packet);
return NULL;
}
packet->stream_index = stream_index;
return packet;
}
int videoencoder::Encode(uint8_t *yuv_data, int yuv_size,
int stream_index, int64_t pts, int64_t time_base,
std::vector<AVPacket *> &packets)
{
if(!this->_avcodecContext) {
printf("codec_ctx_ null\n");
return -1;
}
int ret = 0;
pts = av_rescale_q(pts, AVRational{1, (int)time_base}, this->_avcodecContext->time_base);
this->_avframe->pts = pts;
if(yuv_data) {
int ret_size = av_image_fill_arrays(_avframe->data, _avframe->linesize,
yuv_data, (AVPixelFormat)_avframe->format,
_avframe->width, _avframe->height, 1);
if(ret_size != yuv_size) {
printf("ret_size:%d != yuv_size:%d -> failed\n", ret_size, yuv_size);
return -1;
}
ret = avcodec_send_frame(this->_avcodecContext, this->_avframe);
} else {
ret = avcodec_send_frame(this->_avcodecContext, NULL);
}
if(ret != 0) {
char errbuf[1024] = {0};
av_strerror(ret, errbuf, sizeof(errbuf) - 1);
printf("avcodec_send_frame failed:%s\n", errbuf);
return -1;
}
while(1)
{
AVPacket *packet = av_packet_alloc();
ret = avcodec_receive_packet(this->_avcodecContext, packet);
packet->stream_index = stream_index;
if (ret == AVERROR(EAGAIN) || ret == AVERROR_EOF) {
ret = 0;
av_packet_free(&packet);
break;
} else if (ret < 0) {
char errbuf[1024] = {0};
av_strerror(ret, errbuf, sizeof(errbuf) - 1);
printf("h264 avcodec_receive_packet failed:%s\n", errbuf);
av_packet_free(&packet);
ret = -1;
}
printf("h264 pts:%lld\n", packet->pts);
packets.push_back(packet);
}
return ret;
}
AVCodecContext *videoencoder::GetCodecContext()
{
if(this->_avcodecContext){
return this->_avcodecContext;
}
return nullptr;
}
2.重采样编码相关类 audioresample.h
audioresample
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1233
1233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









