







一 coredns部署
1 coredns.yaml文件获取
coredns.io官网
github上下载二进制GitHub - coredns/coredns: CoreDNS is a DNS server that chains pluginshttps://github.com/kubernetes/kubernetes/tree/master/cluster/addons/dns/coredns #也可以在这个连接执行下载corednsyaml文件
2 coredns.yaml文件配置
2.1 设置要解析的域名
解析的域名必须要和你k8s安装时配置的域名一直,查看方式 /etc/kubeasz/clusters/k8s-cluster01/hosts
2.2 设置dns转发
两种配置方式如图所示:
2.3 资源限制
是否要设置资源限制,根据服务器实际情况来定
limits 表示必须要有这么多资源,pod才可以启动。request表示最高限制这些资源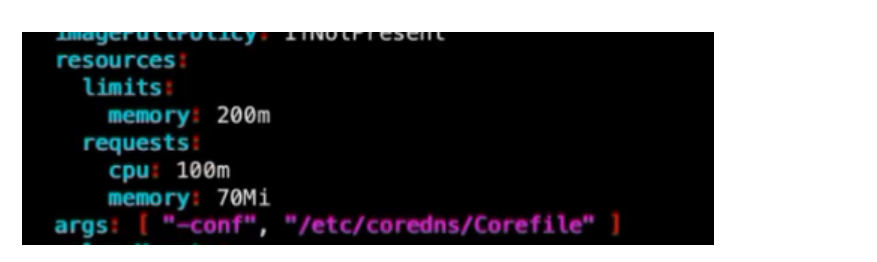
2.4 设置dns地址,cluster_ip
集群里默认.2的地址都是分配给了dns,.1的地址分配给了kubernetes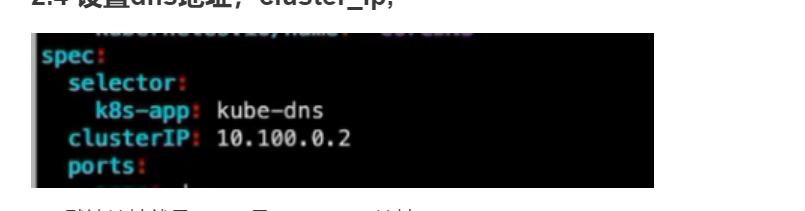
2.5 镜像地址更改
默认是谷歌地址,去hub上去找coredns下载地址
2.6 域名缓存时间设置
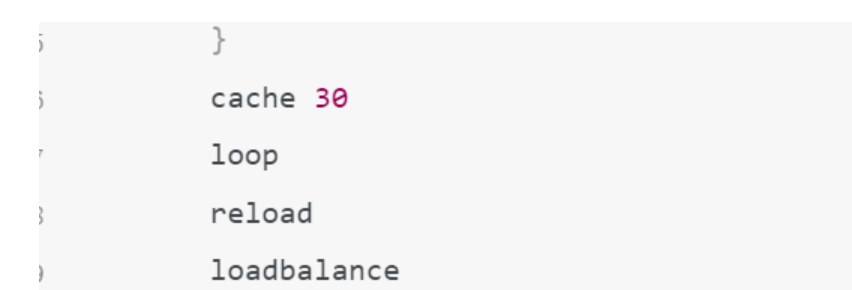
2.7 确定副本数量
默认是1个
2.8 如何让pod的dns地址默认就是coredns的地址
2.8.1在node节点修改/var/lib/kubelet/config.yaml 如下图所示:
2.8.2 重启kubelet
2.8.3 删除pod重新生成
全部更改完毕之后就可以部署了
kubectl apply -f coredns.yaml部署完成之后,去Pod里测试解析域名。如果不能解析去pod的reslov.conf检查你的dns地址
2.9 测试解析域名
kubectl run test1 --image=busybox sleep 30000
进去容器 kubectl exec -it test1 sh
ping kube-dns.kube-system.svc.magedu.local #ping 内网域名
外网域名
3.0 查看coredns日志
kubectl logs coredns-7db6b45f67-qklhh -n kube-system -f二 部署dashboard
1 获取yaml文件
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.5.0/aio/deploy/recommended.yaml2更改yaml文件
默认不支持外部访问,需要设置nodeport
3 创建访问用户
kubectl apply -f admin-user.yaml
[root@k8s-master1 yaml]# cat admin-user.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard4 查看用户的token
kubectl get secret -n kubernetes-dashboard
kubectl describe secret admin-user-token-ckw5q -n kubernetes-dashboard #查看admin的token5 用token登录
三 k8s内部dns解析流程
在 Kubernetes 中,比如服务 a 访问服务 b,对于同一个 Namespace下,可以直接在 pod 中,通过 curl b 来访问(前提必须有自己的services,也就是clusterip)。对于跨 Namespace 的情况,服务名后边对应 Namespace即可。比如 curl b.default
比如:我在default空间下的pod去分别ping kubernetes和kube-dns
第一个可以直接ping,不需要加命名空间,因为在同一个namespace下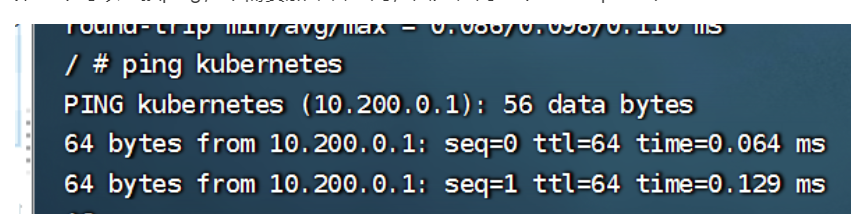
第二个需要加namespace
四 etcd的操作
1查看成员信息
etcdctl member list
后面显示的false就是显示没有在同步数据
2 查看集群监控信息
#!/bin/bash
export node_ips="172.31.7.101"
for ip in ${node_ips};do
/opt/kube/bin/etcdctl --endpoints=https://${ip}:2379 --cacert=/etc/kubernetes/ssl/ca.pem\
--cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem endpoint health
done结果如下:

3以表格方式详细显示节点信息
#!/bin/bash
export node_ips="172.31.7.101"
for ip in ${node_ips};do
/opt/kube/bin/etcdctl --write-out=table endpoint status --endpoints=https://${ip}:2379 --cacert=/etc/kubernetes/ssl/ca.pem\
--cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem endpoint health
done
4 查看etcd数据信息
etcdctl get / --prefix --keys-only #以路径方式显示所有key信息
etcdctl get / --prefix --keys-only |grep pod #显示所有pod信息
etcdctl get / --prefix --keys-only |grep namespaces #显示所有命名空间信息
etcdctl get / --prefix --keys-only |grep deployment #查看deploynent信息
# etcdctl get / --prefix --keys-only |grep calico #显示网络组件5 etcd的增删改查
[root@k8s-etcd01 ~]# etcdctl put /name "zhang" #添加数据
OK
[root@k8s-etcd01 ~]# etcdctl get /name #查询数据
/name
zhang
[root@k8s-etcd01 ~]# etcdctl put /name "bob" #更改数据
OK
[root@k8s-etcd01 ~]# etcdctl get /name
/name
bob
[root@k8s-etcd01 ~]# etcdctl del /name #删除数据
16etcd weach机制
etcdctl watch /data #在一个终端检测然后在另一个终端添加数据
[root@k8s-etcd01 ~]# etcdctl put /data "456"
OK
[root@k8s-etcd01 ~]# etcdctl put /data "123"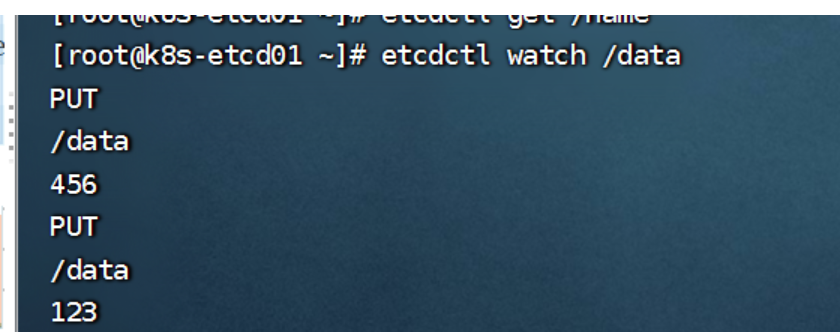
五 etcd的备份和恢复
etcd是只支持全量备份,所以恢复的时候也只能全量恢复,所以在实际环境中通常会采用velero 去针对命名空间去备份。
velero 使用方法见:https://www.cnblogs.com/huningfei/p/16175409.html
1 v3版本的 备份和恢复
备份:
etcdctl snapshot save snapshot.db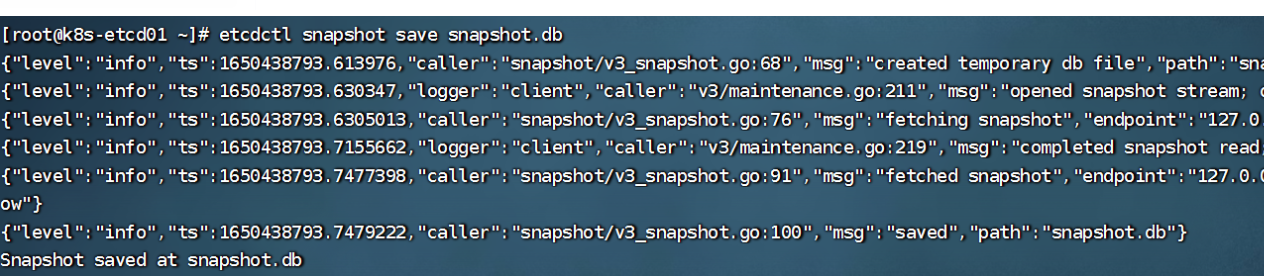
恢复
etcdctl snapshot restore snapshot.db --data-dir=/opt/etcd-test #恢复的目录必须是一个不存在的目录,会自动创建然后把etcd的datedir和workdir目录都改一下,改成/opt/etcd-test,然后重启etcd即可。
2脚本自动备份
需要借助crontab
#!/bin/bash
source /etc/profile
DATE=`date +%Y-%m-%d_%H-%M-%S`
etcdctl snapshot save /data/etcd-backup/etcd-snapshot-${DATE}.db3借助kubeasz 去备份etcd数据
这个是直接备份整个集群的
./ezctl backup k8s-cluster01 # 备份集群
./ezctl restore k8s-cluster01 #恢复集群4 etcd添加和删除节点
./ezctl add-etcd ip
./ezctl del-etcd ip5 etcd数据恢复流程
当etcd集群宕机数量超过总结点数一半以上(如总数为3台,宕机2台),则需要重新恢复数据,流程如下:
1 恢复服务器系统
2 重新部署etcd集群
3 停止kube-apiserver/controller-manager/scheduler/kubelet/kube-proxy
4 停止etcd集群
5 各个etcd节点恢复同一份备份数据
6 启动各节点并验证etcd集群
7启动kube-apiserver/controller-manager/scheduler/kubelet/kube-proxy
8 验证k8s master 状态以及pod数据6 etcd碎片整理
/usr/local/bin/etcdctl defrag --cluster --endpoints=https://172.31.7.106:2379 --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem六 k8s集群的升级
1 先下载新版本的二进制文件
https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG/CHANGELOG-1.23.md#server-binaries
下载如下两个
2升级master
需要先在负载均衡里先剔除出去master 配置在/etc/kube-lb/conf目录,然后重启kube-lb服务
流程如下:
1 先停止服务
systemctl stop kube-apiserver.service kube-controller-manager.service kube-scheduler.service kube-proxy.service kubelet.service
2 拷贝新版本的命令到指定目录
/usr/local/src/kubernetes/server/bin
# 强制替换反斜杠
\cp kube-apiserver kube-controller-manager kube-scheduler kubelet kube-proxy kubectl /opt/kube/bin/
替换完之后,在启动这些服务
systemctl start kube-apiserver.service kube-controller-manager.service kube-scheduler.service kube-proxy.service kubelet.service3 升级node
1 强制驱逐指定节点
# kubectl drain 172.31.7.102 --force --ignore-daemonsets --delete-emptydir-data
2 停止服务 systemctl stop kubelet kube-proxy
3 替换 kubectl kubelet kube-proxy
4 启动 systemctl start kubelet kube-proxy
5 取消驱逐 kubectl uncordon 172.31.7.102升级结果:
七 k8s集群管理-借助kubeasz
支持的功能如下:
add-etcd <cluster> <ip> to add a etcd-node to the etcd cluster
add-master <cluster> <ip> to add a master node to the k8s cluster
add-node <cluster> <ip> to add a work node to the k8s cluster
del-etcd <cluster> <ip> to delete a etcd-node from the etcd cluster
del-master <cluster> <ip> to delete a master node from the k8s cluster
del-node <cluster> <ip> to delete a work node from the k8s cluster举例:
1 添加node节点
./ezctl add-node k8s-cluster01 172.31.7.113 #node节点ip
2 添加master节点
./ezctl add-master k8s-cluster01 172.31.7.110 #master节点ip
3 删除node节点
./ezctl del-node k8s-cluster01 172.31.7.113八 yaml文件字段解释
[root@k8s-master1 yaml]# cat nginx.yaml
kind: Deployment #类型,是deployment控制器
#apiVersion: extensions/v1beta1
apiVersion: apps/v1 # api版本
metadata: #pod元数据
labels: #自定义pod的标签
app: linux66-nginx-deployment-label #标签名称为app,值为linux66-nginx-deployment-label 是deployment的标签
name: linux66-nginx-deployment # pod的名字
namespace: linux66 # pod命名空间
spec: # 定义deployment中容器的详细信息
replicas: 1 # 副本数量,pod的数量
selector: # 定义标签选择器
matchLabels: #定义匹配的标签 ,必须要设置
app: linux66-nginx-selector #匹配的目标标签
template: #模板,必须定义,起到描述要创建pod的作用
metadata: #定义模板元数据
labels: # 定义模板label
app: linux66-nginx-selector #定义pod标签
spec: # 定义pod信息
containers: # 定义pod中容器列表,可以多个或者一个
- name: linux66-nginx-container #容器名称
image: nginx #镜像地址
#command: ["/apps/tomcat/bin/run_tomcat.sh"]
#imagePullPolicy: IfNotPresent #如果本地存在,则不拉取镜像
imagePullPolicy: Always # 镜像拉去策略。总是拉取最新的
ports: #定义容器端口列表
- containerPort: 80
protocol: TCP
name: http
- containerPort: 443
protocol: TCP
name: https
env: #定义pod 环境变量,可以直接在pod引用
- name: "password"
value: "123456"
- name: "age"
value: "18"
# resources:
# limits: #限制pod最多使用多少资源
# cpu: 1 # 2 整数表示核数=200%,1.5浮点数表示1.5核心=150% ,800m=0.8=80% 1核心=1000m(毫核)
# memory: 1Gi
# requests: #最少要满足这些条件,否则无法启动pod
# cpu: 2
# memory: 2Gi
---
kind: Service #类型为service
apiVersion: v1
metadata:
labels: #自定义标签
app: linux66-nginx-service-label #标签内容
name: linux66-nginx-service # service的名字
namespace: linux66 #service的命名空间,必须和pod在同一个命名空间
spec: #定义serverce的详细信息
type: NodePort #service的类型,默认是clusterIP,
ports: # 定义访问端口
- name: http
port: 80 # service的端口
protocol: TCP
targetPort: 80 #目标pod的端口
nodePort: 30006 #node节点暴露的端口
- name: https
port: 443
protocol: TCP
targetPort: 443
nodePort: 30443
selector:
app: linux66-nginx-selector #匹配指定的pod,才可以对外映射端口














 2866
2866











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









