







本章将介绍一个 Web 搜索引擎,我们将在本书其余部分开发它。我描述了搜索引擎的元素,并介绍了第一个应用程序,一个从维基百科下载和解析页面的 Web 爬行器。本章还介绍了深度优先搜索的递归实现,以及迭代实现,它使用 Java
Deque实现“后入先出”的栈。
1.搜索引擎
网络搜索引擎,像谷歌搜索或 Bing,接受一组“检索项”,并返回一个网页列表,它们和这些项相关。
搜索引擎的基本组成部分是:
- 抓取:我们需要一个程序,可以下载网页,解析它,并提取文本和任何其他页面的链接。
- 索引:我们需要一个数据结构,可以查找一个检索项,并找到包含它的页面。
- **检索:**我们需要一种方法,从索引中收集结果,并识别与检索项最相关的页面。
我们以爬虫开始。爬虫的目标是查找和下载一组网页。对于像 Google 和 Bing 这样的搜索引擎,目标是查找所有网页,但爬虫通常仅限于较小的域。在我们的例子中,我们只会读取维基百科的页面。
作为第一步,我们将构建一个读取维基百科页面的爬虫,找到第一个链接,并跟着链接来到另一个页面,然后重复。我们将使用这个爬虫来测试“到达哲学”的猜想,它是:
点击维基百科文章正文中的第一个小写的链接,然后对后续文章重复这个过程,通常最终会到达“哲学”的文章。
在几个章节之内,我们将处理索引器,然后我们将到达检索器.
2.解析HTML
下载网页时,内容使用HTML编写。
<!DOCTYPE html>
<html>
<head>
<title>This is a title</title>
</head>
<body>
<p>Hello world!</p>
</body>
</html>
当我们的爬虫下载页面时,它需要解析 HTML,以便提取文本并找到链接。为此,我们将使用jsoup,它是一个下载和解析 HTML 的开源 Java 库。
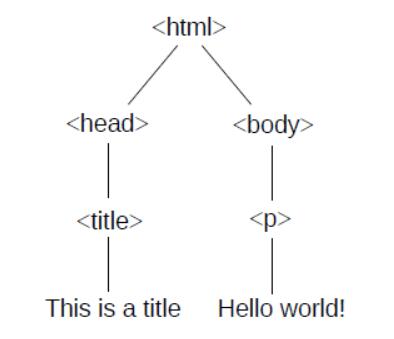
解析 HTML 的结果是文档对象模型(DOM)树,其中包含文档的元素,包括文本和标签。树是由节点组成的链接数据结构;节点表示文本,标签和其他文档元素.
节点之间的关系由文档的结构决定。在上面的例子中,第一个节点称为根,是<html>标签,它包含指向所包含两个节点的链接, <head>和<body>;这些节点是根节点的子节点。
3.使用jsoup
jsoup非常易于下载,和解析 Web 页面,以及访问 DOM 树。这里是一个例子:
public static void main(String[] args) throws Exception{
String url = "https://en.wikipedia.org/wiki/Java_(programming_language)";
//下载并解析元素
Connection connection = Jsoup.connect(url);
Document doc = connection.get();
//选择内容,并解析初其中所有的段落
Element content = doc.getElementById("mw-content-text");
Elements paragraphs = content.select("p");
for (Element xx : paragraphs) {
System.out.println(xx);
}
}
Jsoup.connect接受String形式的url,并连接 Web 服务器。get方法下载 HTML,解析,并返回Document`对象,他表示 DOM。
Document提供了导航树和选择节点的方法,这里主要展示了两种:
getElementById获取某个标签下的所有内容select可对获取的内容进行遍历,选择初想要的元素的集合(支持css选择器)
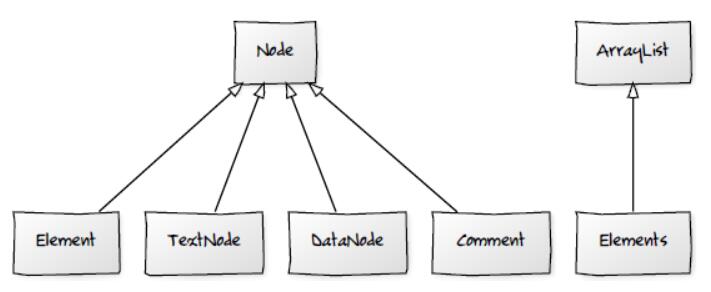
Node表示 DOM 树中的一个节点;有几个扩展Node的子类,其中包括 Element,TextNode,DataNode,和Comment。Elements是Element对象的Collection
4.遍历HTML
为了使你变得更轻松,这里提供了一个WikiNodeIterable类,可以让你遍历 DOM 树中的节点。
Elements paragraphs = content.select("p");
Element firstPara = paragraphs.get(0);
Iterable<Node> iter = new WikiNodeIterable(firstPara);
for (Node node: iter) {
if (node instanceof TextNode) {
System.out.print(node);
}
}
这个例子紧接着上一个例子。它选择paragraphs中的第一个段落,然后创建一个WikiNodeIterable,它实现Iterable<Node>。WikiNodeIterable执行“深度优先搜索”,它按照它们将出现在页面上的顺序产生节点(这个是创造它的目的)。
在这个例子中,仅当Node是TextNode时,我们打印它,并忽略其他类型的Node,特别是代表标签的Element对象。结果是没有任何标记的 HTML 段落的纯文本。
5.深度优先搜索
有几种方式可以合理地遍历一个树,每个都有不同的应用。我们从深度优先搜索(DFS)开始。DFS 从树的根节点开始,并选择第一个子节点。如果子节点有子节点,则再次选择第一个子节点。当它到达没有子节点的节点时,它回溯,沿树向上移动到父节点,在那里它选择下一个子节点,如果有的话;否则它会再次回溯。当它探索了根节点的最后一个子节点,就完成了(跟之前思维导图遍历节点一样)。
有两种常用的方式来实现 DFS,递归和迭代。
递归(代码简洁):
public static void recursiveDFS (Node node) {
if (node instanceof TextNode) {
System.out.println(node);
}
for (Node child : node.childNodes()) {
recursiveDFS(child);
}
}
这个方法对树中的每一个Node调用,从根节点开始。如果Node是一个TextNode,它打印其内容。如果Node有任何子节点,它会按顺序在每一个子节点上调用recursiveDFS(前序遍历)。
通过进行递归调用,recursiveDFS使用调用栈来跟踪子节点并以正确的顺序处理它们。作为替代,我们可以使用栈数据结构自己跟踪节点;如果我们这样做,我们可以避免递归并迭代遍历树(非递归的好处)。
6.Java中的栈
在我解释 DFS 的迭代版本之前,我将解释栈数据结构。我们将从栈的一般概念开始,我将使用小写s指代“栈”。然后我们将讨论两个 Java接口,它们定义了栈的方法:Stack和Deque。
栈是与列表类似的数据结构:它是维护元素顺序的集合。栈和列表之间的主要区别是栈提供的方法较少。在通常的惯例中,它提供:
push:它将一个元素添加到栈顶。pop:它从栈中删除并返回最顶部的元素。peek:它返回最顶部的元素而不修改栈。isEmpty:表示栈是否为空。
因为pop总是返回最顶部的元素,栈也称为 LIFO,代表“后入先出”。栈的替代品是“队列”,它返回的元素顺序和添加顺序相同;即“先入先出(FIFO)。
为什么栈和队列是有用的,可能不是很明显:它们不提供任何列表没有的功能;实际上它们提供的功能更少。那么为什么不使用列表的一切?有两个原因:
- 如果你将自己限制于一小部分方法 - 也就是小型 API - 你的代码将更加易读,更不容易出错。例如,如果使用列表来表示栈,则可能会以错误的顺序删除元素。使用栈 API,这种错误在字面上是不可能的。避免错误的最佳方法是使它们不可能(小型API可以给到很多限制,大型的兼容性强)。
- 如果一个数据结构提供了小型 API,那么它更容易实现。例如,实现栈的简单方法是单链表。当我们压入一个元素时,我们将它添加到列表的开头;当我们弹出一个元素时,我们在开头删除它。对于链表,在开头添加和删除是常数时间的操作,因此这个实现是高效的。相反,大型 API 更难实现高效。
为了在 Java 中实现栈,你有三个选项:
- 继续使用
ArrayList或LinkedList。如果使用ArrayList,请务必从最后添加和删除,这是一个常数时间的操作。并且小心不要在错误的地方添加元素,或以错误的顺序删除它们。 - Java 提供了一个
Stack类,它提供了一组标准的栈方法。但是这个类是 Java 的一个旧部分:它与 Java 集合框架不兼容,后者之后才出现。 - 最好的选择可能是使用
Deque接口的一个实现,如ArrayDeque。
Deque代表“双向队列”;在 Java 中, Deque接口提供push,pop,peek和isEmpty,因此你可以将Deque用作栈。
7.迭代式DFS
这里是 DFS 的迭代版本,它使用ArrayDeque来表示Node对象的栈。
public static void iteratorDFS(Node root) {
Deque<Node> stack = new ArrayDeque<Node>();
stack.push(root);
while (!stack.isEmpty()) {
Node node = stack.pop();
if (node instanceof TextNode) {
System.out.println(node);
}
// 这里必须反转,因为开始压栈时,顺序会反,所有需要反转,确保顺序正确
List<Node> list = new ArrayList<Node>(node.childNodes());
Collections.reverse(list);
for (Node child : list) {
stack.push(child);
}
}
}
参数root是我们想要遍历的树的根节点,所以我们首先创建栈并将根节点压入它。
循环持续到栈为空。每次迭代,它会从栈中弹出Node。如果它得到TextNode,它打印内容。然后它把子节点们压栈。为了以正确的顺序处理子节点,我们必须以相反的顺序将它们压栈; 我们通过将子节点复制成一个ArrayList,原地反转元素,然后遍历反转的ArrayList。
DFS 的迭代版本的一个优点是,更容易实现为 Java Iterator;你会在下一章看到如何实现。
原书链接:https://wizardforcel.gitbooks.io/think-dast/content/6.html
GitHub链接(提供源码):https://github.com/huoji555/Shadow/tree/master/DataStructure














 2944
2944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









