







这一章展示了二叉搜索树,它是个
Map接口的高效实现。如果我们想让元素有序,它非常实用。
1.哈希的不足
HashMap被广泛使用,但并不是唯一的Map实现。有几个原因可能需要另一个实现:
- 哈希可能很慢,所以即使
HashMap操作是常数时间,“常数”可能很大。 如果哈希函数将键均匀分配给子映射,效果很好。但设计良好的散列函数并不容易,如果太多的键在相同的子映射上,那么HashMap的性能可能会很差。 - 哈希表中的键不以任何特定顺序存储;实际上,当表增长并且键被重新排列时,顺序可能会改变。对于某些应用程序,必须或至少保持键的顺序,这很有用。
很难同时解决所有这些问题,但是 Java 提供了一个称为TreeMap的实现:
- 它不使用哈希函数,所以它避免了哈希的开销和选择哈希函数的困难。
- 在
TreeMap之中,键被存储在二叉搜索树中,这使我们可以以线性时间顺序遍历键。 - 核心方法的运行时间与
log(n)成正比,并不像常数时间那样好,但仍然非常好。
下一节中,我将解释二进制搜索树如何工作,然后你将使用它来实现Map。
2.二叉搜索树
二叉搜索树(BST)是一个树,其中每个node(节点)包含一个键,并且每个都具有“BST 属性”:
- 如果
node有一个左子树,左子树中的所有键都必须小于node的键。 - 如果
node有一个右子树,右子树中的所有键都必须大于node的键。
二叉搜索树示例:
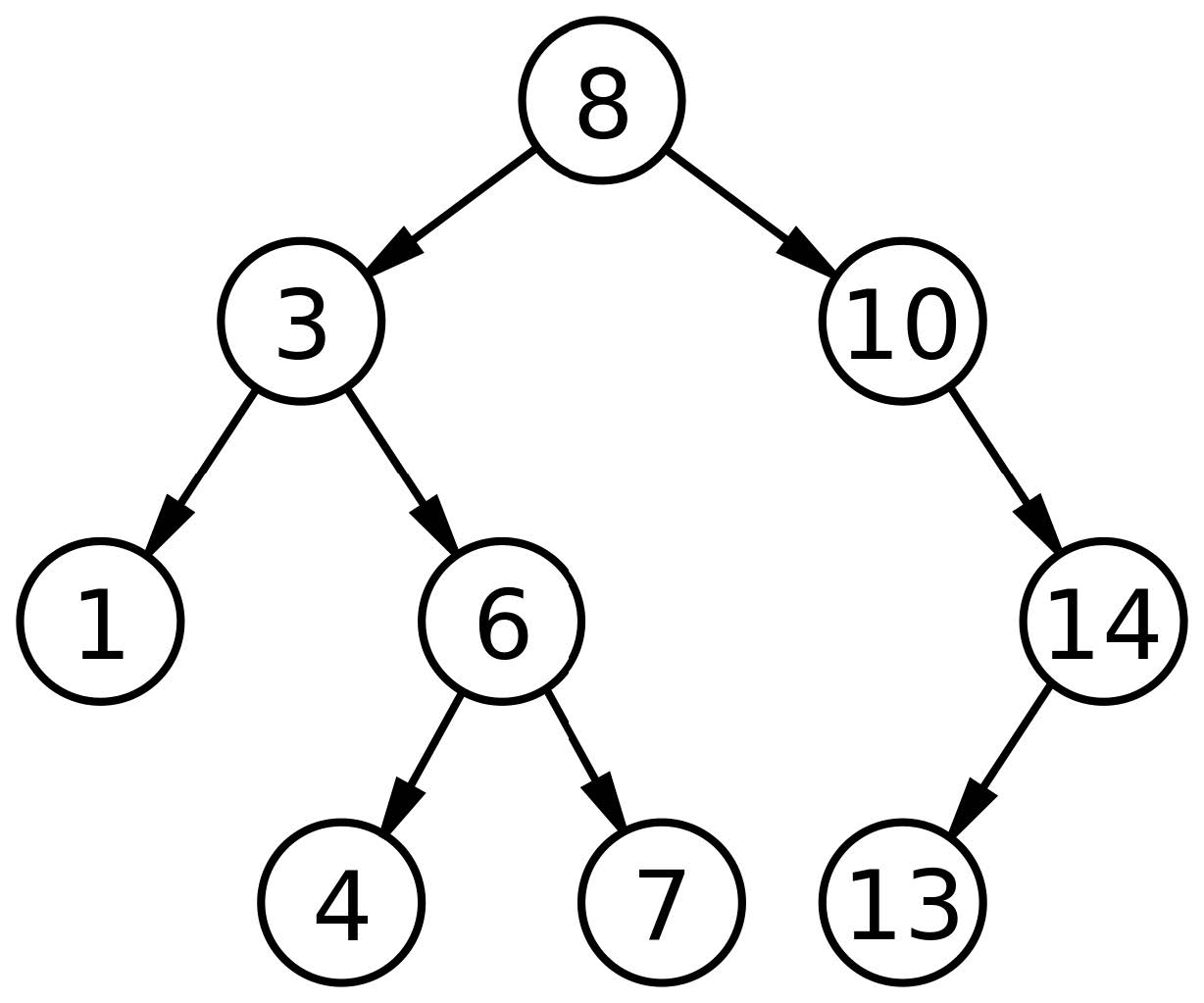
在二叉搜索树中查找一个键是很快的,因为我们不必搜索整个树。从根节点开始,我们可以使用以下算法:
- 将你要查找的键
target,与当前节点的键进行比较。如果他们相等,你就完成了。 - 如果
target小于当前键,搜索左子树。如果没有,target不在树上。 - 如果
target大于当前键,搜索右子树。如果没有,target不在树上。
在树的每一层,你只需要搜索一个子树。例如,如果你在上图中查找target = 4,则从根节点开始,它包含键8。因为target小于8,你走了左边。因为target大于3,你走了右边。因为target小于6,你走了左边。然后你找到你要找的键
现在你可能会看到这个规律。如果我们将树的层数从1数到n,第i层可以拥有多达2^(n-1)个节点。h层的树共有2^h-1个节点。如果我们有:
n = 2^h - 1
我们可以对两边取以2为底的对数:
log2(n) ≈ h
意思是树的高度正比于logn,如果它是满的(每一层包含最大数量的节点),满二叉树。
3.TreeMap结构
这里将要使用二叉搜索树编写Map接口的一个实现,这是开头结构:
public class MyTreeMap<K, V> implements Map<K, V> {
private int size = 0;
private Node root = null;
size追踪键的数量,root为根节点,下面是Node的定义:
protected class Node {
public K key;
public V value;
public Node left = null;
public Node right = null;
public Node(K key, V value) {
this.key = key;
this.value = value;
}
}
这时,我们可以实现一些相对简单的方法:
public int size() {
return size;
}
public void clear() {
size = 0;
root = null;
}















 1949
1949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









