









🌟模型添加噪声,增强鲁棒性

为模型添加噪声主要有两种方式
1️⃣ 为训练集添加噪声,训练时加噪
2️⃣ 为训练好的模型参数添加噪声,训练后加噪
第一种这里不详细说,transforms里提供了一些裁剪和旋转图片的方式,此外可以对图片添加高斯噪声等随机性。
如何实现第二种噪声,特别是对于大型网络,每一层的参数大小可能处在不同的数量级,那么是我们这里重点要谈的部分。
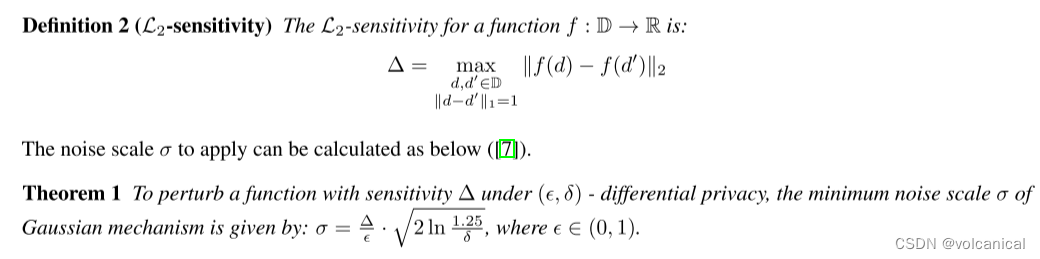
σ
G
≈
Δ
ϵ
2
ln
1.25
δ
\sigma_G \approx \frac{\Delta}{\epsilon} \sqrt{2\ln \frac{1.25}{\delta}}
σG≈ϵΔ2lnδ1.25
根据论文里的想法,就是如果要达到
L
2
L_2
L2级别的敏感度,就要添加如上所示公式的噪声(由果及因)。
但是其实到实验里,最后都是慢慢去试出来,给一个高斯噪声,不断的去测试对 l o s s loss loss的影响,对隐私的保护性,达到一个均衡。
但是当应用在深度神经网络中时,因为每一层的数量级可能不同,因此就没法像在论文中一样添加一样的高斯噪声。
有人给出了对于模型中的参数,计算出标准差,从而得到所需要的最小下界差分隐私量。
或者也可以计算每一层的
l
2
l_2
l2范数,将
l
2
l_2
l2范数作为一个高斯噪声的系数。
那么对应到代码里实现就是:遍历每一层的参数,计算每一层参数的标准差or范数,以这个数值作为敏感度,来计算所需要的噪声量。
这里的
δ
和
ϵ
\delta和\epsilon
δ和ϵ都是超参数,都需要慢慢地去试出来。
lamda = 0.001
for name, param in self.global_model.named_parameters():
if 'bias' in name or 'bn' in name:
# 不对偏置和BatchNorm的参数添加噪声
continue
std = lamda * param.data.std()
noise = torch.normal(0, std, size=param.size()).cuda()
param.data.add_(noise)
也可以偷懒,直接简略成 λ ∗ S t \lambda*S_t λ∗St,通过不同的 λ \lambda λ去尝试这个噪声的量,来实现模型加噪的效果。 λ \lambda λ如果过大,会造成模型不收敛,波动大, λ \lambda λ如果太小,那么噪声就起不到效果,需要不断地去尝试权衡,达到较好的效果。
通常不对偏置和 BatchNorm 参数添加噪声的原因如下:
- 对于偏置来说,它只是单独地加在每个卷积核输出上的一个常量,不涉及卷积核之间的交互。因此,即使偏置没有添加噪声,模型在一定程度上也能保持随机性和泛化性能。
- BatchNorm 层的参数包括平均值和标准差,它们是在每一层的 mini-batch 上计算得到的,因此可以看作是一个统计量。在训练过程中,这些参数被不断更新,使得 BatchNorm 层的输出在 mini-batch 中具有一定的随机性。因此,即使不对 BatchNorm 参数添加噪声,模型仍然能够具有一定的随机性和泛化性能。
- 另外,添加噪声也可能会对 BatchNorm 层的性能造成一定的负面影响,因为它可能会破坏 BatchNorm 层对输入数据的正则化效果。
因此,在实践中,通常不对偏置和 BatchNorm 参数添加噪声。当然,具体是否添加噪声还要根据具体任务和实验结果进行调整。

















 493
493











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











