







 本文探讨了提升计算机性能的两种主要途径:通过增加单位时间内指令执行量(超线程和多核处理)以及利用核亲和性优化内存访问和资源隔离。重点介绍了超线程的原理与局限,以及多核处理中核绑定的重要性,尤其是在非统一内存访问(NUMA)环境中的应用。
本文探讨了提升计算机性能的两种主要途径:通过增加单位时间内指令执行量(超线程和多核处理)以及利用核亲和性优化内存访问和资源隔离。重点介绍了超线程的原理与局限,以及多核处理中核绑定的重要性,尤其是在非统一内存访问(NUMA)环境中的应用。
提升性能总体来说有两种方式:1、提升单位为时间内运行指令的数量,2、提升CPU主频。提升主频简单粗暴,但是放在节能增效的今天就不适合,提升主频会增加功效,所以最佳的方式是提升单位时间内运行指令的条数。根据这个思路有几种方式,首先想到的是讲一个物理线程虚拟成多个线程,也就是所谓的超线程,这样做的好处呢就是使得单个核心能够同时处理多个线程,从而提升并行计算的能力。但是也有缺点:由于他们底层的硬件资源共享,如果执行的线程存在竞争关系,则会影响性能。另一种方式是多核处理,通过扩展核来增加单位时间执行指令的条数。对于多核处理,衍生而来是为了提升性能如何绑定核,怎么绑定核,绑定核的理论依据是什么,解决这些问题就有了核的亲和性原理以及亲和性的必要性。以下是对这些内容的阐述。
1、多核处理的理论依据
多核并行计算的吞吐率随核数增加而线性扩展, 可并行处理部分占整个任务比重越高, 则增长的斜率越大。这句话怎么理解呢,可以这样理解,有一个蓄水池整个容量是一定的,我们的任务呢就是把这个蓄水池的水放到另一个蓄水池,放水的管子越多,则速度越快。但是还有一个含义就是性能最终是由不能并行的任务决定的,如果这个蓄水池需要中间中转一个水池,但是这个水池和另一个水池只有一个水管,即使第一个水池很快的能把中间水池充满,但是决定最后一个水池的快慢还是由中间水池决定的。
2、超线程

在一个物理CPU核心上模拟出两个或更多的逻辑处理器核心。通过在硬件层面增加额外的调度和执行资源,使得单个核心能够同时处理多个线程,从而提升并行计算的能力。
优点:在传统的非超线程CPU中,一个核心在同一时间只能执行一个指令流。而具备超线程技术的CPU,其架构包含有多个寄存器集以及其他必要的组件备份,可以在同一周期内为两个独立的线程提供服务。这意味着操作系统可以将两个不同的线程分配给同一个物理核心上的两个逻辑核心来执行,理论上能显著提高多线程应用的性能。
缺陷:超线程并不能简单地将核心性能翻倍,因为共享的资源(如缓存、内存控制器带宽等)可能会成为瓶颈,而且当两个线程同时需要相同资源时,会导致争用,从而影响性能。尽管如此,在许多工作负载中,尤其是那些具有大量并发任务且并非所有任务都在同一时刻占用全部资源的应用场景下,超线程技术仍然可以带来一定的性能提升。
3、多核处理
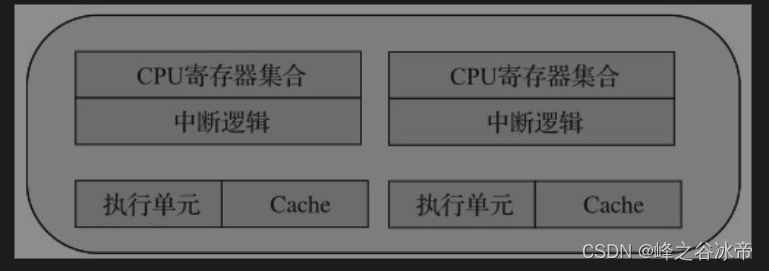
多核就是在一个核内放入多个对等的物理核,每个物理核都能独立的处理线程。多核之间的通信使用芯片内部总线来完成,共享更低一级缓存(LLC,三级缓存)和内存
处理器核数:也就是每个物理CPU中core的个数
sibling:sibling是内核认为的单个物理处理器所有的超线程个数,也就是一个物理封装中的逻辑核的个数,如果逻辑核等于物理核,则没有启动超级线程。
系统物理处理器封装ID:Socket中文翻译成“插槽”,也就是所谓的物理处理器封装个数,即俗称的“物理CPU数”
系统逻辑处理器ID:俗称的逻辑cpu数
4、亲和性
(1)优化性能
如果它能持续在同一个CPU核心上执行,那么这些数据就更有可能保留在该核心的高速缓存中,从而减少内存访问延迟,提高执行效率。反之如果线程不在同一个cpu核上,就会是当前缓存的值没有作用,不但提升不了性能,反而会降低性能。
利用NUMA架构:在非统一内存访问(NUMA)系统中,每个CPU核心有本地内存区域,访问本地内存的速度要快于远程内存。通过设置亲和性,可以确保线程优先使用其绑定的核心的本地内存
(2)资源隔离
线程绑定到单独的核上, 可以避免与系统中的其他任务竞争共享资源。
5、总结
多核并行计算的吞吐率随核数增加而线性扩展,可并行处理部分占整个任务比重越高,则增长的斜率越大。
这个是dpdk优化性能一个理论基础,资源局部化、避免跨核共享、减少临界区碰撞、加快临界区完成速率等,都不同程度地降低了不可并行部分和并发干扰部分的占比。















 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









