







- 环境
准备三台Linux系统(我使用的是CentOS系统)
JDK版本1.7; hadoop2.5
配置vi /etc/hosts 增加三台电脑的IP与本机名的映射
配置NTP服务器(时间同步)
–hadoop-study01.com
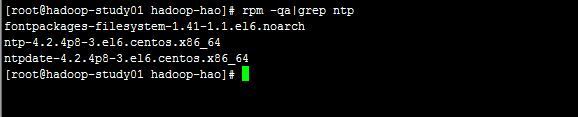
rpm -qa|grep ntp –查看ntp软件
ntpdate asia.poo.ntp.org–同步时间
–hadoop-study02.com,-hadoop-study02.com,
注:三台电脑都要配置相同的环境,保持网络的畅通 - 分布式集群配置文件
配置jdk环境:hadoop-env.sh,yarn-env.sh , mapred-env.sh
core-site.xml ,hdfs-site.xml, yarn-site.xml
3.正式搭建
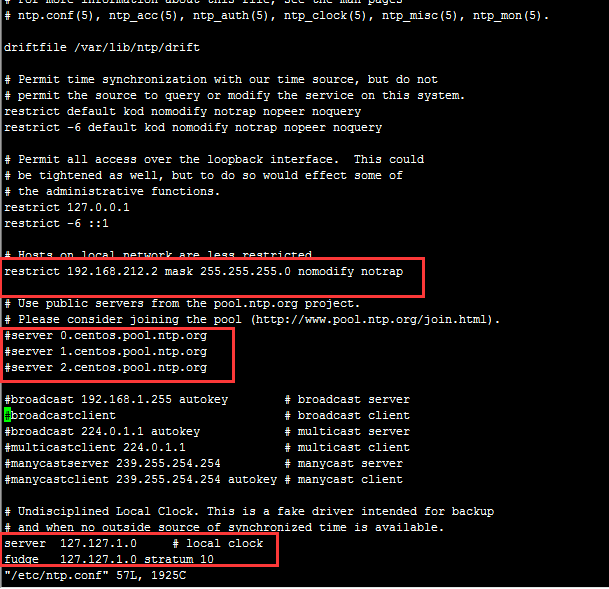
首先同步三台计算机时间第一台机器配置信息,修改 vi /etc/ntp.conf
一、按要求更改三处划线的地方:
(1)取消前面的注释,并修改网段(192.168.17.0)
restrict 192.168.17.0 mask 255.255.255.0 nomodify notrap
(2)把下面三行加#注释
#server 0.centos.pool.ntp.org
#server 1.centos.pool.ntp.org
#server 2.centos.pool.ntp.org
(3)取消下面两行的#号
server 127.127.1.0 # local clock
fudge 127.127.1.0 stratum 10
二、修改 /etc/sysconfig/ntpd 文件
插入:
SYNC_HWCLOCK=yes

配置完成后ntpdate asia.ntp.pool.org同步时间并使用 service ntpd start启动ntp服务, chkconfig ntpd on 设置为开机启动

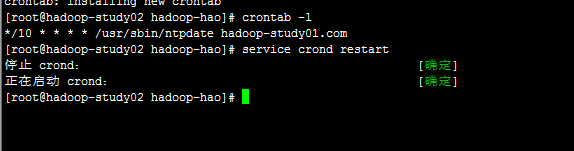
第二,第三机器使用# crontab -e命令增加/10 * * * /usr/sbin/ntpdate bigdata01.ibeifeng.com
之后保存重启同步# service crond restart
如此配置时间同步服务完成,开始修改分布式环境配置文件
分布式搭建步骤::::
第三 >.确定角色分配

namenode配置在01机器,resourmanager配置02机器,secondarynamenode,historyserver配置在03机器,nodemanager,datenode,配置在所有机器上
第四:更改配置文件:
core-sitr.xml
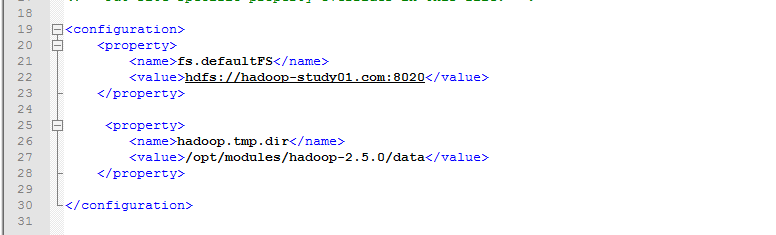
slaves

,mapred-site.xml
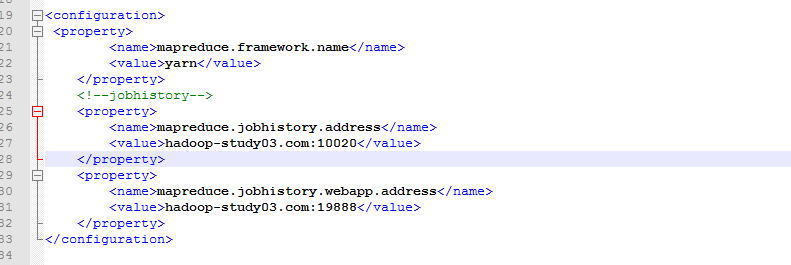
yarn-site.xml
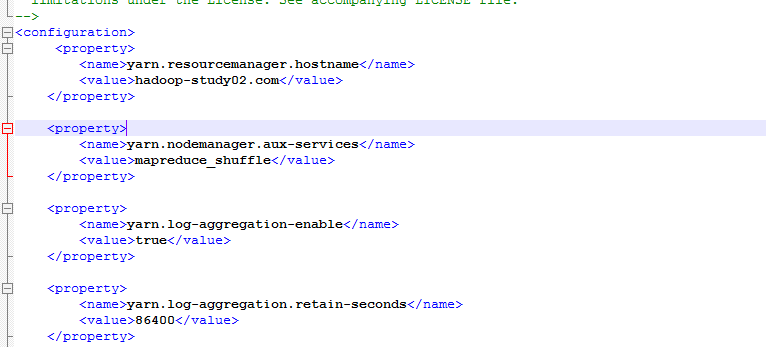
第五:启动服务:
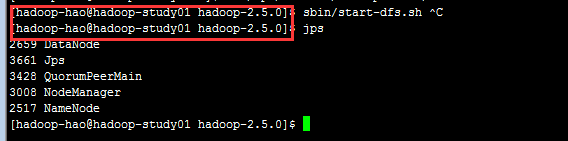
01机器:hdfs
02机器:yarn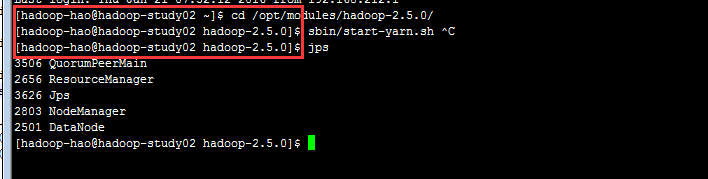
03机器:jobhistory
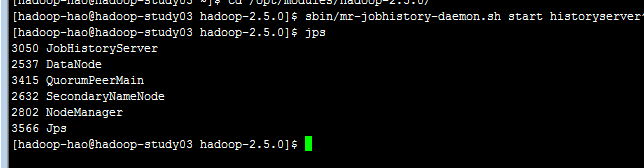
使用jps查看进程。。。















 143
143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









