







快速排序是由东尼·霍尔所发展的一种排序算法。在平均状况下,排序 n 个项目要Ο(n log n)次比较。在最坏状况下则需要Ο(n2)次比较,但这种状况并不常见。事实上,快速排序通常明显比其他Ο(n log n) 算法更快,因为它的内部循环(inner loop)可以在大部分的架构上很有效率地被实现出来。
快速排序的优点:
(1)原址排序,空间复杂度较小。
(2)虽然最坏情况下(有序数组)时间复杂度为 (n*n),但是平均性能很好,期望复杂度为( nlg(n) )。
快速排序使用分治法(Divide and conquer)策略来把一个串行(list)分为两个子串行(sub-lists)
步骤为:
(1)从数列中挑出一个元素,称为 "基准"(pivot),
(2)重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的 中间位置。这个称为分区(partition)操作。
(3)递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
快速排序 与 随机快速排序的唯一区别就是:快速排序始终将数组最后一个元素作为基准,而随机快速排序是从数组中随机挑选一个元素和最后一个元素交换位置后,作为基准。随机快速排序基准的选择更能适应大规模随机数据的快速排序。
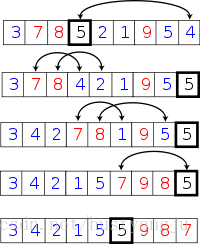
(随机快速排序算法)
快速排序源码:
#include <iostream>
#include <algorithm>
#include <cstdlib>
using namespace std;
class quick_sort_class
{
public:
quick_sort_class(int *a, int n):p_array(a), n_array(n){};
~quick_sort_class();
void quick_sort(int i, int j);
void print();
protected:
int partition(int *a, int p, int r);
private:
int *p_array;
int n_array;
};
quick_sort_class::~quick_sort_class()
{
}
int quick_sort_class::partition(int *a, int p, int r)
{
int x = a[r];
int i = p-1;
for(int j=p;j<r;++j)
{
if(a[j]<=x)
{
++i;
swap(a[i], a[j]);
}
}
swap(a[i+1], a[r]);
return i+1;
}
void quick_sort_class::quick_sort(int i, int j)
{
if(i<j)
{
int q = partition(p_array, i, j);
quick_sort(i, q-1);
quick_sort(q+1, j);
}
}
void quick_sort_class::print()
{
for(int i=0;i<n_array;++i)
cout<<p_array[i]<<" ";
cout<<endl;
}
int main()
{
int array[10] = {8, 4, 7, 15, 10, 84, 23, 19, 3, 11};
quick_sort_class myQuickSort(array, 10);
myQuickSort.print();
myQuickSort.quick_sort(0, 9);
myQuickSort.print();
}测试结果:
















 5371
5371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









