







首先需要修改配置文件spark-env.sh。在这个文件中需要添加两个属性:
Export HADOOP_HOME=/../hadoop..
ExportHADOOP_CONF_DIR=/../hadoop/etc/hadoop
这里,一个是要hadoop的home目录。一个是配置文件目录。
还需要配置一个就是spark-defaults.conf这个文件:

需要修改红色框内的文件。下面看下这个文件里面的内容:
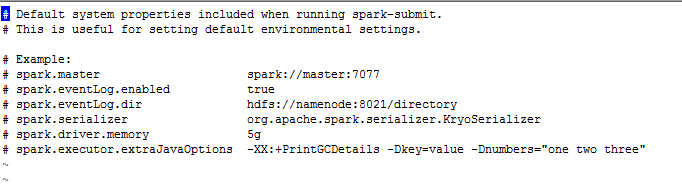
在spark的源文件中给出了一些配置参数的示例。另外它还下面一个可以配置的属性
| 属性名 | 说明 | 默认值 |
| spark.yarn.applicationMaster.waitTries | RM等待Spark AppMaster启动次数,也就是SparkContext初始化次数。超过这个数值,启动失败。 | 10 |
| spark.yarn.submit.file.replication | 应用程序上载到HDFS的文件的复制因子 | 3 |
| spark.yarn.preserve.staging.files | 设置为true,在job结束后,将stage相关的文件保留而不是删除。 | false |
| spark.yarn.scheduler.heartbeat.interval-ms | Spark AppMaster发送心跳信息给YARN RM的时间间隔 | 5000 |
| spark.yarn.max.executor.failures | 导致应用程序宣告失败的最大executor失败数 | 2倍于executor数 |
| spark.yarn.historyServer.address | Spark history server的地址(不要加http://)。这个地址会在应用程序完成后提交给YARN RM,使得将信息从RM UI连接到history server UI上。 | 无 |
还有更多的配置内容参考http://blog.csdn.net/book_mmicky/article/details/29472439。这里不一一列举。
运行流程
下面是Spark On Yarn的流程图:
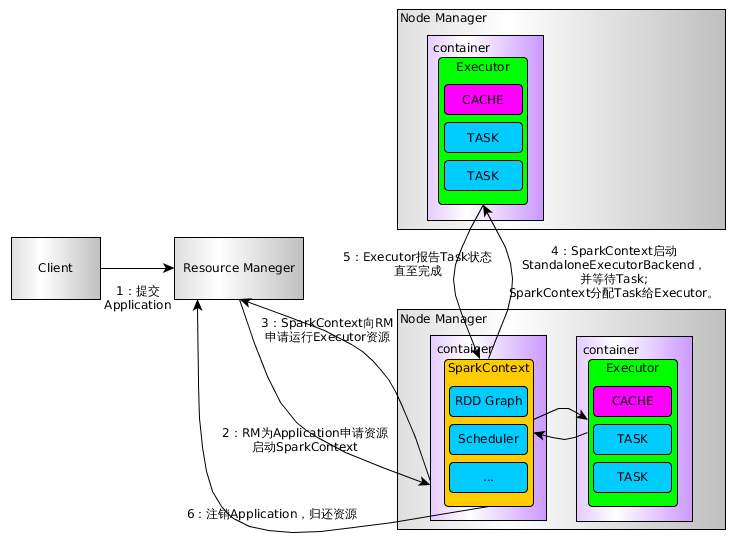
上图比较只管的看到到了流程,下面具体看几个源码
Client
在Client类中的main方法实例话Client:new Client(args, sparkConf).run()。在run方法中,又调用了val appId = runApp()方法。runApp()源码如下:
| def runApp() = { validateArgs()
init(yarnConf) start() logClusterResourceDetails()
val newApp = super.getNewApplication() val appId = newApp.getApplicationId()
verifyClusterResources(newApp) val appContext = createApplicationSubmissionContext(appId) val appStagingDir = getAppStagingDir(appId) val localResources = prepareLocalResources(appStagingDir) val env = setupLaunchEnv(localResources, appStagingDir) val amContainer = createContainerLaunchContext(newApp, localResources, env)
val capability = Records.newRecord(classOf[Resource]).asInstanceOf[Resource] // Memory for the ApplicationMaster. capability.setMemory(args.amMemory + memoryOverhead) amContainer.setResource(capability)
appContext.setQueue(args.amQueue) appContext.setAMContainerSpec(amContainer) appContext.setUser(UserGroupInformation.getCurrentUser().getShortUserName())
submitApp(appContext) appId } |
1)这里首先对一些参数配置的校验,然后初始化、启动Client
2)提交请求到ResouceManager,检查集群的内存情况。
3)设置一些参数,请求队列
4)正式提交APP
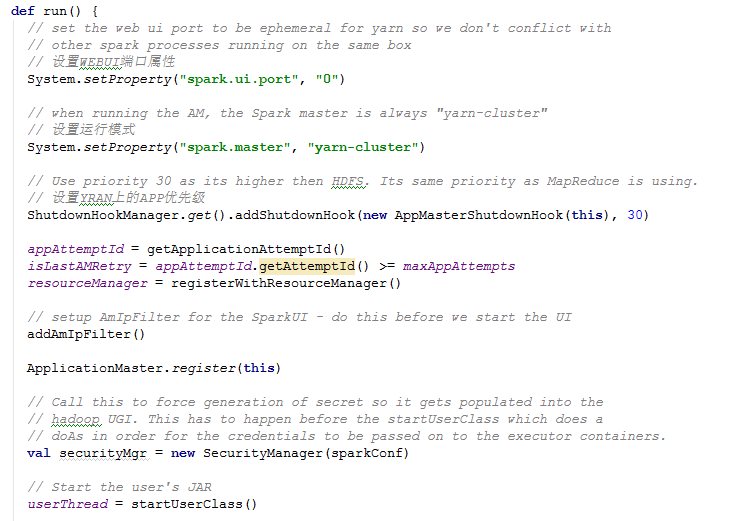
ApplicationManager
AM负责运行Spark Application的Driver程序,并分配执行需要的Executors。里面也有个main方法实例化AM并调用run,源码如下:
















 850
850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









