









接上一篇:
Spark的资源管理以及YARN-Cluster Vs YARN-Client
下面是Spark On Yarn的流程图:
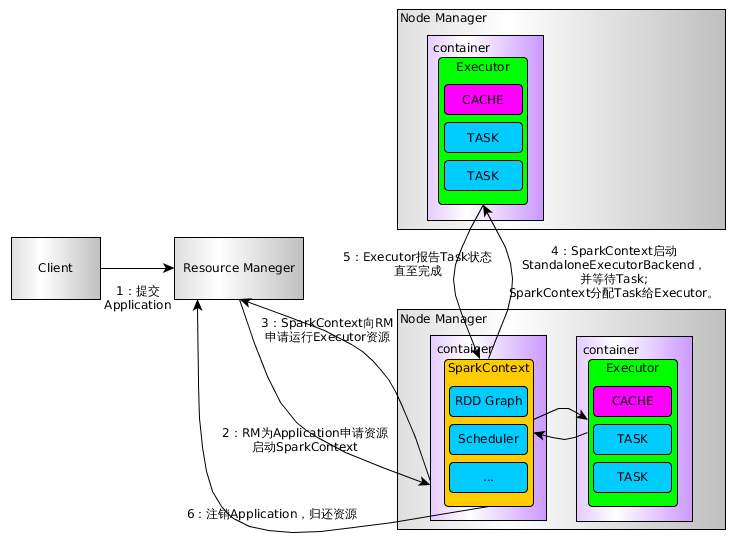
上图比较只管的看到到了流程,下面具体看几个源码
Client
在Client类中的main方法实例话Client:new Client(args, sparkConf).run()。在run方法中,又调用了val appId = runApp()方法。runApp()源码如下:
| def runApp() = { validateArgs()
init(yarnConf) start() logClusterResourceDetails()
val newApp = super.getNewApplication() val appId = newApp.getApplicationId()
verifyClusterResources(newApp) val appContext = createApplicationSubmissionContext(appId) val appStagingDir = getAppStagingDir(appId) val localResources = prepareLocalResources(appStagingDir) val env = setupLaunchEnv(localResources, appStagingDir) val amContainer = createContainerLaunchContext(newApp, localResources, env)
val capability = Records.newRecord(classOf[Resource]).asInstanceOf[Resource] // Memory for the ApplicationMaster. capability.setMemory(args.amMemory + memoryOverhead) amContainer.setResource(capability)
appContext.setQueue(args.amQueue) appContext.setAMContainerSpec(amContainer) appContext.setUser(UserGroupInformation.getCurrentUser().getShortUserName())
submitApp(appContext) appId } |
1)这里首先对一些参数配置的校验,然后初始化、启动Client
2)提交请求到ResouceManager,检查集群的内存情况。
3)设置一些参数,请求队列
4)正式提交APP
ApplicationMaster
AM负责运行Spark Application的Driver程序,并分配执行需要的Executors。里面也有个main方法实例化AM并调用run,源码如下:

run方法里面主要干了5项工作:
1、初始化工作
2、启动driver程序
3、注册ApplicationMaster
4、分配Executors
5、等待程序运行结束
我们重点看分配Executor方法。

1.6版本
final def run(): Int = {
try {
val appAttemptId = client.getAttemptId()
if (isClusterMode) {
// Set the web ui port to be ephemeral for yarn so we don't conflict with
// other spark processes running on the same box
System.setProperty("spark.ui.port", "0")
// Set the master property to match the requested mode.
System.setProperty("spark.master", "yarn-cluster")
// Propagate the application ID so that YarnClusterSchedulerBackend can pick it up.
System.setProperty("spark.yarn.app.id", appAttemptId.getApplicationId().toString())
// Propagate the attempt if, so that in case of event logging,
// different attempt's logs gets created in different directory
System.setProperty("spark.yarn.app.attemptId", appAttemptId.getAttemptId().toString())
}
logInfo("ApplicationAttemptId: " + appAttemptId)
val fs = FileSystem.get(yarnConf)
// This shutdown hook should run *after* the SparkContext is shut down.
val priority = ShutdownHookManager.SPARK_CONTEXT_SHUTDOWN_PRIORITY - 1
ShutdownHookManager.addShutdownHook(priority) { () =>
val maxAppAttempts = client.getMaxRegAttempts(sparkConf, yarnConf)
val isLastAttempt = client.getAttemptId().getAttemptId() >= maxAppAttempts
if (!finished) {
// This happens when the user application calls System.exit(). We have the choice
// of either failing or succeeding at this point. We report success to avoid
// retrying applications that have succeeded (System.exit(0)), which means that
// applications that explicitly exit with a non-zero status will also show up as
// succeeded in the RM UI.
finish(finalStatus,
ApplicationMaster.EXIT_SUCCESS,
"Shutdown hook called before final status was reported.")
}
if (!unregistered) {
// we only want to unregister if we don't want the RM to retry
if (finalStatus == FinalApplicationStatus.SUCCEEDED || isLastAttempt) {
unregister(finalStatus, finalMsg)
cleanupStagingDir(fs)
}
}
}
// Call this to force generation of secret so it gets populated into the
// Hadoop UGI. This has to happen before the startUserApplication which does a
// doAs in order for the credentials to be passed on to the executor containers.
val securityMgr = new SecurityManager(sparkConf)
// If the credentials file config is present, we must periodically renew tokens. So create
// a new AMDelegationTokenRenewer
if (sparkConf.contains("spark.yarn.credentials.file")) {
delegationTokenRenewerOption = Some(new AMDelegationTokenRenewer(sparkConf, yarnConf))
// If a principal and keytab have been set, use that to create new credentials for executors
// periodically
delegationTokenRenewerOption.foreach(_.scheduleLoginFromKeytab())
}
if (isClusterMode) {
runDriver(securityMgr)
} else {
runExecutorLauncher(securityMgr)
}
} catch {
case e: Exception =>
// catch everything else if not specifically handled
logError("Uncaught exception: ", e)
finish(FinalApplicationStatus.FAILED,
ApplicationMaster.EXIT_UNCAUGHT_EXCEPTION,
"Uncaught exception: " + e)
}
exitCode
}
private def runDriver(securityMgr: SecurityManager): Unit = {
addAmIpFilter()
userClassThread = startUserApplication()
// This a bit hacky, but we need to wait until the spark.driver.port property has
// been set by the Thread executing the user class.
val sc = waitForSparkContextInitialized()
// If there is no SparkContext at this point, just fail the app.
if (sc == null) {
finish(FinalApplicationStatus.FAILED,
ApplicationMaster.EXIT_SC_NOT_INITED,
"Timed out waiting for SparkContext.")
} else {
rpcEnv = sc.env.rpcEnv
val driverRef = runAMEndpoint(
sc.getConf.get("spark.driver.host"),
sc.getConf.get("spark.driver.port"),
isClusterMode = true)
registerAM(rpcEnv, driverRef, sc.ui.map(_.appUIAddress).getOrElse(""), securityMgr)
userClassThread.join()
}
}
private def registerAM(
_rpcEnv: RpcEnv,
driverRef: RpcEndpointRef,
uiAddress: String,
securityMgr: SecurityManager) = {
val sc = sparkContextRef.get()
val appId = client.getAttemptId().getApplicationId().toString()
val attemptId = client.getAttemptId().getAttemptId().toString()
val historyAddress =
sparkConf.getOption("spark.yarn.historyServer.address")
.map { text => SparkHadoopUtil.get.substituteHadoopVariables(text, yarnConf) }
.map { address => s"${address}${HistoryServer.UI_PATH_PREFIX}/${appId}/${attemptId}" }
.getOrElse("")
val _sparkConf = if (sc != null) sc.getConf else sparkConf
val driverUrl = _rpcEnv.uriOf(
SparkEnv.driverActorSystemName,
RpcAddress(_sparkConf.get("spark.driver.host"), _sparkConf.get("spark.driver.port").toInt),
CoarseGrainedSchedulerBackend.ENDPOINT_NAME)
allocator = client.register(driverUrl,
driverRef,
yarnConf,
_sparkConf,
uiAddress,
historyAddress,
securityMgr)
allocator.allocateResources()
reporterThread = launchReporterThread()
}
----YarnAllocator->allocateResources
def allocateResources(): Unit = synchronized {
updateResourceRequests()
val progressIndicator = 0.1f
// Poll the ResourceManager. This doubles as a heartbeat if there are no pending container
// requests.
val allocateResponse = amClient.allocate(progressIndicator)
val allocatedContainers = allocateResponse.getAllocatedContainers()
if (allocatedContainers.size > 0) {
logDebug("Allocated containers: %d. Current executor count: %d. Cluster resources: %s."
.format(
allocatedContainers.size,
numExecutorsRunning,
allocateResponse.getAvailableResources))
handleAllocatedContainers(allocatedContainers.asScala)
}
val completedContainers = allocateResponse.getCompletedContainersStatuses()
if (completedContainers.size > 0) {
logDebug("Completed %d containers".format(completedContainers.size))
processCompletedContainers(completedContainers.asScala)
logDebug("Finished processing %d completed containers. Current running executor count: %d."
.format(completedContainers.size, numExecutorsRunning))
}
}
private def allocateExecutors() { try { logInfo("Allocating " + args.numExecutors + " executors.") // 分host、rack、任意机器三种类型向ResourceManager提交ContainerRequest // 请求的Container数量可能大于需要的数量 yarnAllocator.addResourceRequests(args.numExecutors) // Exits the loop if the user thread exits. while (yarnAllocator.getNumExecutorsRunning < args.numExecutors && userThread.isAlive) { if (yarnAllocator.getNumExecutorsFailed >= maxNumExecutorFailures) { finishApplicationMaster(FinalApplicationStatus.FAILED, "max number of executor failures reached") } // 把请求回来的资源进行分配,并释放掉多余的资源 yarnAllocator.allocateResources() ApplicationMaster.incrementAllocatorLoop(1) Thread.sleep(100) } } finally { // In case of exceptions, etc - ensure that count is at least ALLOCATOR_LOOP_WAIT_COUNT, // so that the loop in ApplicationMaster#sparkContextInitialized() breaks. ApplicationMaster.incrementAllocatorLoop(ApplicationMaster.ALLOCATOR_LOOP_WAIT_COUNT) } logInfo("All executors have launched.") // 启动一个线程来状态报告 if (userThread.isAlive) { // Ensure that progress is sent before YarnConfiguration.RM_AM_EXPIRY_INTERVAL_MS elapses. val timeoutInterval = yarnConf.getInt(YarnConfiguration.RM_AM_EXPIRY_INTERVAL_MS, 120000) // we want to be reasonably responsive without causing too many requests to RM. val schedulerInterval = sparkConf.getLong("spark.yarn.scheduler.heartbeat.interval-ms", 5000) // must be <= timeoutInterval / 2. val interval = math.min(timeoutInterval / 2, schedulerInterval) launchReporterThread(interval) } }

这里面我们只需要看addResourceRequests和allocateResources方法即可。
先说addResourceRequests方法,代码就不贴了。
Client向ResourceManager提交Container的请求,分三种类型:优先选择机器、同一个rack的机器、任意机器。
优先选择机器是在RDD里面的getPreferredLocations获得的机器位置,如果没有优先选择机器,也就没有同一个rack之说了,可以是任意机器。
下面我们接着看allocateResources方法。
def allocateResources() { // We have already set the container request. Poll the ResourceManager for a response. // This doubles as a heartbeat if there are no pending container requests. // 之前已经提交过Container请求了,现在只需要获取response即可 val progressIndicator = 0.1f val allocateResponse = amClient.allocate(progressIndicator) val allocatedContainers = allocateResponse.getAllocatedContainers() if (allocatedContainers.size > 0) { var numPendingAllocateNow = numPendingAllocate.addAndGet(-1 * allocatedContainers.size) if (numPendingAllocateNow < 0) { numPendingAllocateNow = numPendingAllocate.addAndGet(-1 * numPendingAllocateNow) } val hostToContainers = new HashMap[String, ArrayBuffer[Container]]() for (container <- allocatedContainers) { // 内存 > Executor所需内存 + 384 if (isResourceConstraintSatisfied(container)) { // 把container收入名册当中,等待发落 val host = container.getNodeId.getHost val containersForHost = hostToContainers.getOrElseUpdate(host, new ArrayBuffer[Container]()) containersForHost += container } else { // 内存不够,释放掉它 releaseContainer(container) } } // 找到合适的container来使用. val dataLocalContainers = new HashMap[String, ArrayBuffer[Container]]() val rackLocalContainers = new HashMap[String, ArrayBuffer[Container]]() val offRackContainers = new HashMap[String, ArrayBuffer[Container]]() // 遍历所有的host for (candidateHost <- hostToContainers.keySet) { val maxExpectedHostCount = preferredHostToCount.getOrElse(candidateHost, 0) val requiredHostCount = maxExpectedHostCount - allocatedContainersOnHost(candidateHost) val remainingContainersOpt = hostToContainers.get(candidateHost) var remainingContainers = remainingContainersOpt.get if (requiredHostCount >= remainingContainers.size) { // 需要的比现有的多,把符合数据本地性的添加到dataLocalContainers映射关系里 dataLocalContainers.put(candidateHost, remainingContainers) // 没有containner剩下的. remainingContainers = null } else if (requiredHostCount > 0) { // 获得的container比所需要的多,把多余的释放掉 val (dataLocal, remaining) = remainingContainers.splitAt(remainingContainers.size - requiredHostCount) dataLocalContainers.put(candidateHost, dataLocal) for (container <- remaining) releaseContainer(container) remainingContainers = null } // 数据所在机器已经分配满任务了,只能在同一个rack里面挑选了 if (remainingContainers != null) { val rack = YarnAllocationHandler.lookupRack(conf, candidateHost) if (rack != null) { val maxExpectedRackCount = preferredRackToCount.getOrElse(rack, 0) val requiredRackCount = maxExpectedRackCount - allocatedContainersOnRack(rack) - rackLocalContainers.getOrElse(rack, List()).size if (requiredRackCount >= remainingContainers.size) { // Add all remaining containers to to `dataLocalContainers`. dataLocalContainers.put(rack, remainingContainers) remainingContainers = null } else if (requiredRackCount > 0) { // Container list has more containers that we need for data locality. val (rackLocal, remaining) = remainingContainers.splitAt(remainingContainers.size - requiredRackCount) val existingRackLocal = rackLocalContainers.getOrElseUpdate(rack, new ArrayBuffer[Container]()) existingRackLocal ++= rackLocal remainingContainers = remaining } } } if (remainingContainers != null) { // 还是不够,只能放到别的rack的机器上运行了 offRackContainers.put(candidateHost, remainingContainers) } } // 按照数据所在机器、同一个rack、任意机器来排序 val allocatedContainersToProcess = new ArrayBuffer[Container](allocatedContainers.size) allocatedContainersToProcess ++= TaskSchedulerImpl.prioritizeContainers(dataLocalContainers) allocatedContainersToProcess ++= TaskSchedulerImpl.prioritizeContainers(rackLocalContainers) allocatedContainersToProcess ++= TaskSchedulerImpl.prioritizeContainers(offRackContainers) // 遍历选择了的Container,为每个Container启动一个ExecutorRunnable线程专门负责给它发送命令 for (container <- allocatedContainersToProcess) { val numExecutorsRunningNow = numExecutorsRunning.incrementAndGet() val executorHostname = container.getNodeId.getHost val containerId = container.getId // 内存需要大于Executor的内存 + 384 val executorMemoryOverhead = (executorMemory + YarnAllocationHandler.MEMORY_OVERHEAD) if (numExecutorsRunningNow > maxExecutors) { // 正在运行的比需要的多了,释放掉多余的Container releaseContainer(container) numExecutorsRunning.decrementAndGet() } else { val executorId = executorIdCounter.incrementAndGet().toString val driverUrl = "akka.tcp://spark@%s:%s/user/%s".format( sparkConf.get("spark.driver.host"), sparkConf.get("spark.driver.port"), CoarseGrainedSchedulerBackend.ACTOR_NAME) // To be safe, remove the container from `pendingReleaseContainers`. pendingReleaseContainers.remove(containerId) // 把container记录到已分配的rack的映射关系当中 val rack = YarnAllocationHandler.lookupRack(conf, executorHostname) allocatedHostToContainersMap.synchronized { val containerSet = allocatedHostToContainersMap.getOrElseUpdate(executorHostname, new HashSet[ContainerId]()) containerSet += containerId allocatedContainerToHostMap.put(containerId, executorHostname) if (rack != null) { allocatedRackCount.put(rack, allocatedRackCount.getOrElse(rack, 0) + 1) } } // 启动一个线程给它进行跟踪服务,给它发送运行Executor的命令 val executorRunnable = new ExecutorRunnable( container, conf, sparkConf, driverUrl, executorId, executorHostname, executorMemory, executorCores) new Thread(executorRunnable).start() } } }
1、把从ResourceManager中获得的Container进行选择,选择顺序是按照前面的介绍的三种类别依次进行,优先选择机器 > 同一个rack的机器 > 任意机器。
2、选择了Container之后,给每一个Container都启动一个ExecutorRunner一对一贴身服务,给它发送运行CoarseGrainedExecutorBackend的命令。
3、ExecutorRunner通过NMClient来向NodeManager发送请求。
总结:
把作业发布到yarn上面去执行这块涉及到的类不多,主要是涉及到Client、ApplicationMaster、YarnAllocationHandler、ExecutorRunner这四个类。
1、Client作为Yarn的客户端,负责向Yarn发送启动ApplicationMaster的命令。
2、ApplicationMaster就像项目经理一样负责整个项目所需要的工作,包括请求资源,分配资源,启动Driver和Executor,Executor启动失败的错误处理。
3、ApplicationMaster的请求、分配资源是通过YarnAllocationHandler来进行的。
4、Container选择的顺序是:优先选择机器 > 同一个rack的机器 > 任意机器。
5、ExecutorRunner只负责向Container发送启动CoarseGrainedExecutorBackend的命令。
6、Executor的错误处理是在ApplicationMaster的launchReporterThread方法里面,它启动的线程除了报告运行状态,还会监控Executor的运行,一旦发现有丢失的Executor就重新请求。















 5792
5792

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









