







Spark的资源调度由自己实现,主要节点分为Master、Worker、Driver。Driver一般运行在Master节点中。Standalone模式一般的分布式一样也是Master-Slavers的模式,那么关于Master的HA也有多种实现方式:
1)文件系统发生故障立即恢复,当Master节点挂掉则立即恢复
2)Zookeeper的实现方式,如配置参数-Dspark.deploy.recovery=ZOOKEEPERd等
运行配置参数
在standalone模式下的启动配置可以在spark-evn.sh文件中配置。如图

对于一些常用参数说明
| 参数名 | 说明 |
| SPARK_MASTER_IP | masterIP |
| SPARK_MASTER_PORT | master端口 |
| SPARK_MASTER_WEBUI_PORT | Master web监控端口 |
| SPARK_MASTER_OPTS | 使用-Dxx.xx.xx=yyy的形式指定MASTER特定的属性 |
| SPARK_LOCAL_DIRS | 数据本地化,一些map的输出如果需要写入磁盘则指定这个目录 |
| SPARK_WORKER_CORES | WORKER cpu数据 |
| SPARK_WORKER_MEMORY | Worker 内存 |
| SPARK_WORKER_PORT | Worker端口 |
| SPARK_WORKER_WEBUI_PORT | Web 端口 |
| SPARK_WORKER_INSTANCES | 指定每个worker节点需要启动的worker进程数量 |
| SPARK_WORKER_DIR | Worker节点的工作目录 |
| SPRRK_WORKER_OPTS | 使用-Dxx.xx.xx=yyy的形式指定Worker特定的属性 |
| SPARK_DAEMON_MEMORY | Master进程和Worker进程启动时的内存大小(默认512M) |
| SPARK_DAEMON_JAVA_OPTS | Master与Worker的公共属性 |
具体看下SPARK_MASTER_OPTS的参数配置
Spark.deploy.retainedApplctions 它指在Master节点中保存的最多Appliction记录默认值为200
spark.deploy.retainedDrivers它指Master节点中 保存最多的Driver记录,默认也是200
spark.deploy.spreadOut它指standalone模式下的节点的选择,为true则会让它自由选择这样 的话更好的数据本地性。为false的时候是要固定尽可能少的节点,这样对于计算密集 型的工作负载比较有效。默认为true
spark.deploy.defaultCores 设置cup核数,如果不设置这个参数,那么它会自己获取计算的核
Spark.worker.timeout 设置Master与Worker节点通讯的超时时间 默认为60秒
现在在看下SPARK_WORKER_OPTS的参数配置
Spark.worker.cleamup.enabled 它是在standalone模式下需要确定是否要哦定期清理Worker 的应用程序工作的目录,在清理的时候不管Application是否在运行状态 默认为false
Spark.worker.clieanuo.interval 清理worker本地过期的应用程序工作目录的时间间隔默认为 1800s
spark.worker.cleanup.appDataTtl 这个是worker保留应用程序工作鲁姆的有效时间。这个时间由磁盘空间、应用程序日志、jar文件以及提交频率来设定。默认值为7天
Standalone模式的原理
在standalone模式下,Driver的运行位置可能会不同。使用spark-shell方式运行的,Driver一般运行在Worker节点下,这里用于做调试比较多。使用spark-submit工具的话,Driver就运行在本地客户端了,比如在使用开发用具上newSparkConext(“spark://master:7077”,”mytest”)。
当driver运行在Worker上的时候,我们来看一下流程图
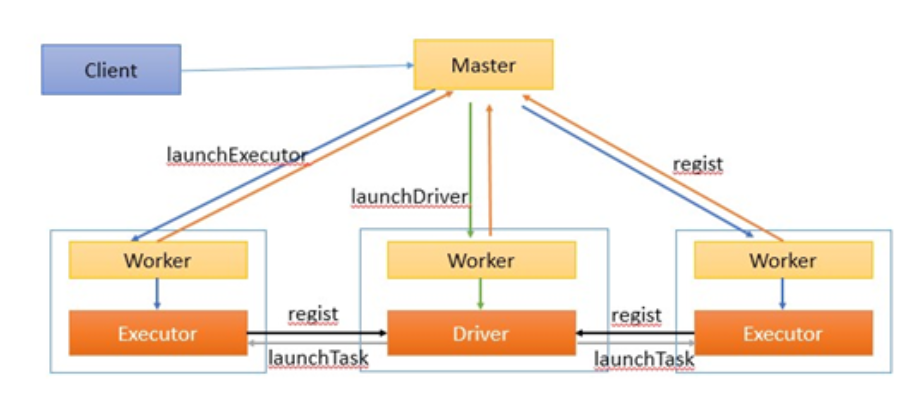
说明:
1)客户端提交一个作业给Master
2)Master接都通知后让Worker启动Driver,也就是SchedulerBackend
3)Worker创建一个DriverRunner线程,DriverRunner启动SchedulerBackend进程
4)Worker创建一个ExecutorRunner线程,它又启动ExecutorBackend进程
5)ExecutorBackend启动后想Driver的SchedulerBackend注册
6)SchedulerBackend进程中包含DAGScheduler,它会根据用户程序,生成执行计划,并调
度执行。对于每个stage的task,都 会被存放到TaskScheduler中,ExecutorBackend向 SchedulerBackend汇报的时候把TaskScheduler中 的task调度到ExecutorBackend执行。 所有stage都完成后作业结束。
当Driver运行在客户端的时候,看下流程图
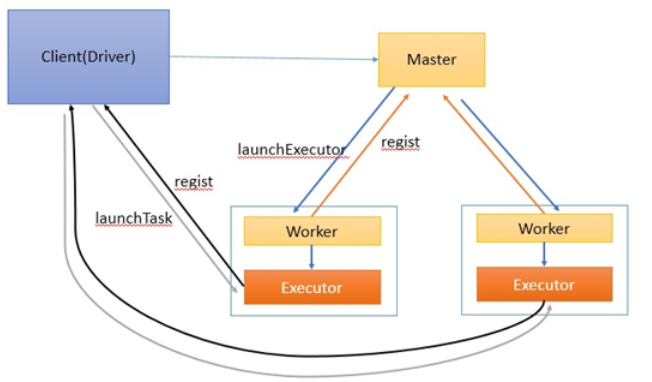
说明:
1)客户端启动后直接运行用户程序,启动Driver相关的工作:DAGScheduler和
BlockManagerMaster等
2)客户端的Driver向Master注册。 Master还会让Worker启动Exeuctor。
3)Worker创建一个ExecutorRunner线程,ExecutorRunner会启动ExecutorBackend进程。
4)ExecutorBackend启动后会向Driver的SchedulerBackend注册。
5)Driver的DAGScheduler解析作业并生成相应的Stage,每个Stage包含的Task通过 TaskScheduler分配给Executor执行。
6)所有stage都完成后作业结束。
Standalone运行流程
首先查看下该模式下的流程图:
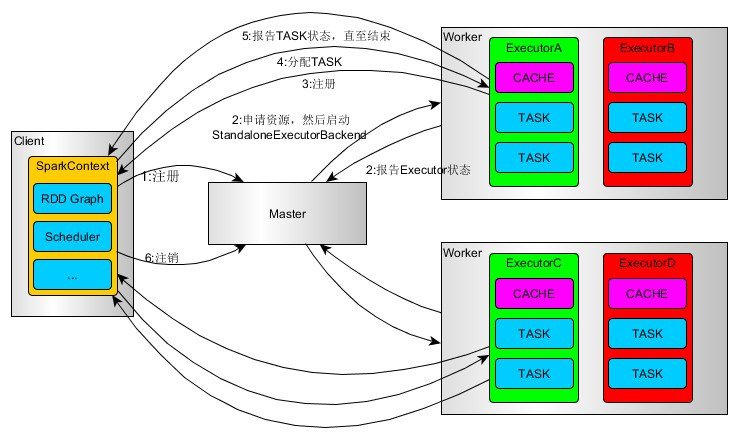
图解:
1)SparkContext连接到Master,向Master注册并申请资源(CPU Core 和Memory)
2)Master根据SparkContext的资源申请要求和worker心跳周期内报告的信息决定在哪个 worker上分配资源,然后在该worker上获取资源,然后启动StandaloneExecutorBackend。
3)StandaloneExecutorBackend向SparkContext注册
4)SparkContext将Applicaiton代码发送给StandaloneExecutorBackend;并且SparkContext 解析Applicaiton代码,构建DAG图,并提交给DAGScheduler分解成Stage(当碰到 Action操作时,就会催生Job;每个Job中含有1个或多个Stage,Stage一般在获取外 部数据和shu f f le之前产生),然后以Stage(或者称为TaskSet)提交给Task Scheduler, TaskScheduler负责将Task分配到相应的worker,最后提交给StandaloneExecutorBackend 执行;
5)StandaloneExecutorBackend会建立executor 线程池,开始执行Task,并向SparkContext 报告,直至Task完成。
6)所有Task完成后,SparkContext向Master注销,释放资源。
Master
Master负责很多信息的注册(Driver、Worker、Application)。它需要负责启动Executor、Worker的心跳通讯等。它是一个可以单独启动的进程。

这个类继承了Actor,他重写了AKKA消息驱动的receiveWithLogging()方法。在这个方法中,需要处理很多事件:ElectedLeader、CompleteRecovery、RevokedLeadership、RegisterWorker、RequestSubmitDriver、RequestKillDriver、RequestDriverStatus、RegisterApplication、ExecutorStateChanged、DriverStateChanged、Heartbeat、MasterChangeAcknowledged、WorkerSchedulerStateResponse、DisassociatedEvent、CheckForWorkerTimeOut。下面是部分代码截图
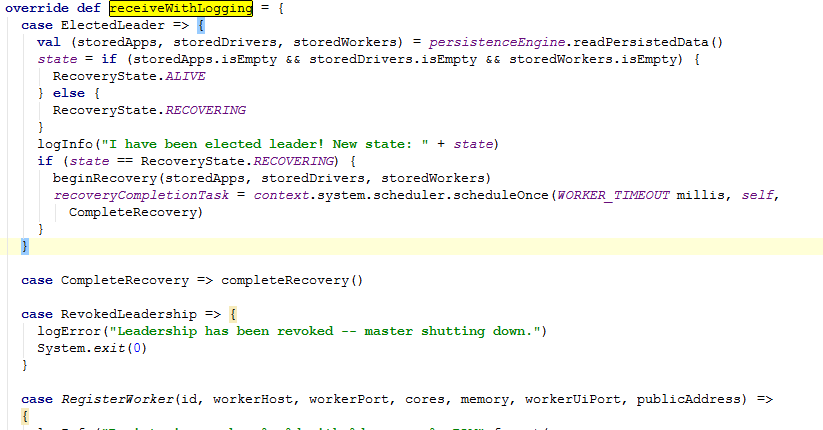
ElectedLeader
先查看它代码的实现
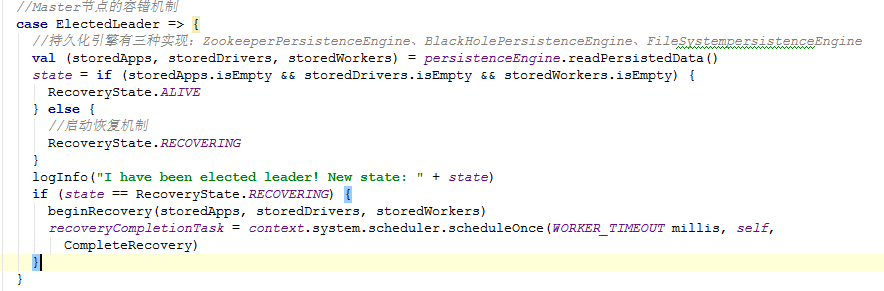
当Master的active与standby进行节点切换时,触发这个事件。他的处理流程如下:
1)通过持久化引擎来读取持久化数据
2)数据都不为空的时候启动恢复机制
3)beginRecovery方法中重新注册Appliction,并且修改它的状态,并向Driver发送新的 master地址。如代码所示:
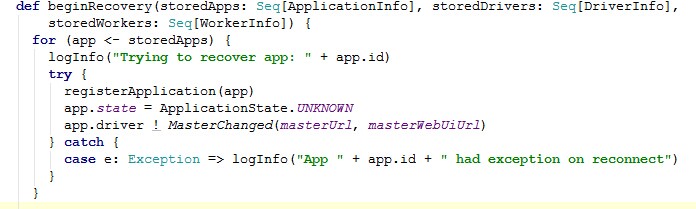
4)重新登记每个Driver的信息到Master的缓存中,构成一个HashSet结构。代码:

5)重新注册每个worker的信息,并等级到缓存中,它也是一个hashSet结构。然后也需要
它的状态,向worker发送Master地址等。
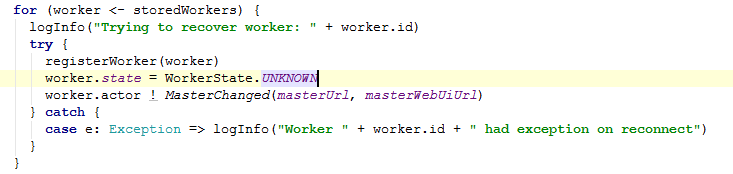
registerWorker方法进去:

6)接下来则是Master的schedule方法,它对当前正处于等待状态的Appliction进行调度
7)结束
RegisterWorker
当Worker节点启动的时候,他需要想Master发送注册信息,而这个注册信息会触发到这个事件。接下来看源码内容:
Worker节点注册信息会附带一些参数:id, workerHost, workerPort, cores, memory, workerUiPort,publicAddress。这些参数在这里被分装成一个WorkerInfo对象。接下来是一个判断的操作,如果worker节点注册了两次(第二次注册),并且第一次的状态是UNKNOWN,那么第二次来的时候则把旧的信息清掉。记录的Worker信息记录在Master缓存中。然后利用持久化引擎持久化Worker注册信息,然后发送回执消息。最后的schedule()方法开始对当前处于等待状态的Application进行调度。
RequestSubmitDriver
这是Driver的注册事件,主要一些工作流程跟RegisterWorker差不多。看下代码即可:

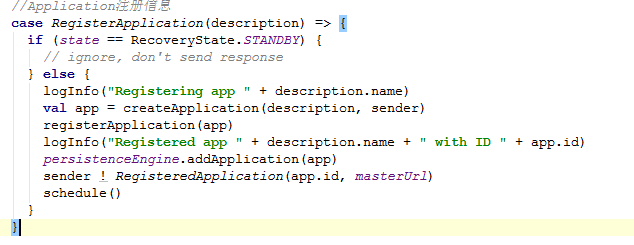
RegisterApplication
Application的注册信息,与Worker、Driver一样。源码如下:
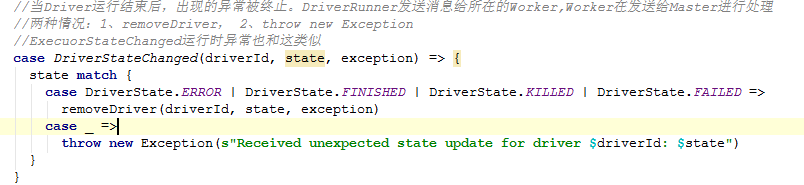
DriverStateChanged
当Driver运行结束后,出现的异常被终止。DriverRunner发送消息给所在的Worker,Worker在发送给Master进行处理。源码如下:
schdule
关于类似在Master中的注册事件还有很多,这里就不一一的列出源码了,感兴趣的朋友可以自行查看。在面的的Worker、Driver、Application注册信息中都看到了schdule()方法。
解下来就分析下这个方法:
第一步:在Master缓存中的workers队列打乱,形成一个新的队列shuffledWorkers。
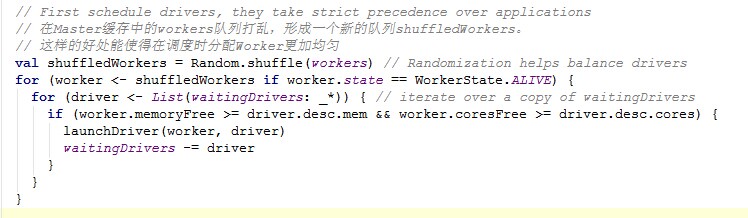
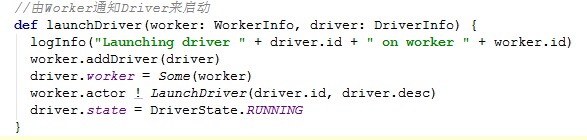
第二步:对与状态为ALIVE的worker,根据该worker节点上的CPU、内存数据再次遍历Driver,最后找到合适的Driver进行launchDriver(),由相应的Worker来启动Driver
接下来有一个校验spreadOutApps。这个变量就是在上文中说名的配置参数spark.deploy.spreadOut。如果该值配置为true就需要遍历App等待队列中的需要被分配资源的APP,根据剩余的资源查找能用的Worker,并且在分配了资源的Worker节点上调用launchExecutor来启动Executor。下面的源码内容:
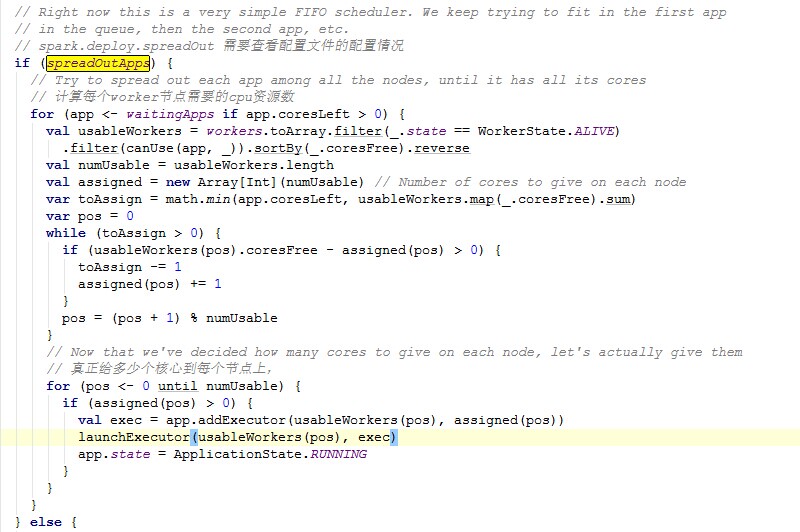
而为false的情况,就变得简单得多,不同的是它是匹配当前Worker节点资源满足条件的情况则直接启动Executor
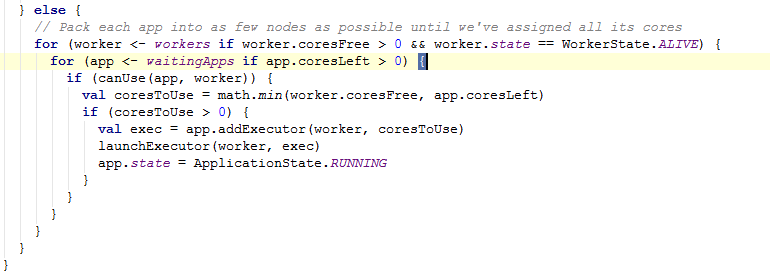
Worker
Worker和Yarn中的NodeManager非常类似,它负责当前节点的资源上报、监督Executor、心跳等问题。上一节中降到Master节点接收Worker节点的通讯时间,现在同样看看Worker中的事件。在Worker上所处理的事件有:RegisteredWorker、SendHeartbeat、WorkDirCleanup、
MasterChanged、Heartbeat、RegisterWorkerFailed、LaunchExecutor、ExecutorStateChanged、KillExecutor、LaunchDriver、KillDriver、DriverStateChanged、DisassociatedEvent、RequestWorkerState。解下来挑选几个看下源码
RegisteredWorker
在Master中已经看到了Worker发送的注册事件。这里简单的列一下Worker的源码:

LaunchExecutor
Worker接收到Master的launnchExecutor事件后,先初始化ExecutorRunner,然后将ExecutorRunner加入到executors队列中,然后启动他。ExecutorRunner负责管理ExecutorBackend的启动、终止、运行。该时间源码如下:
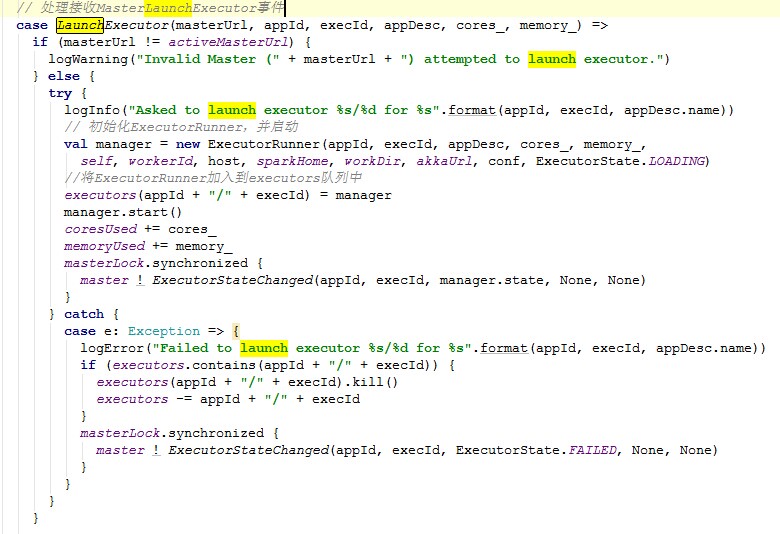
具体看下ExecutorRunner。

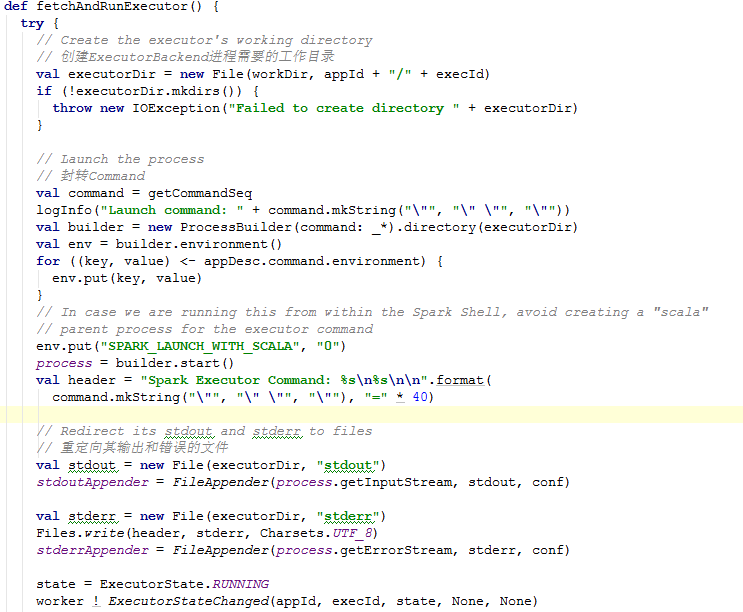
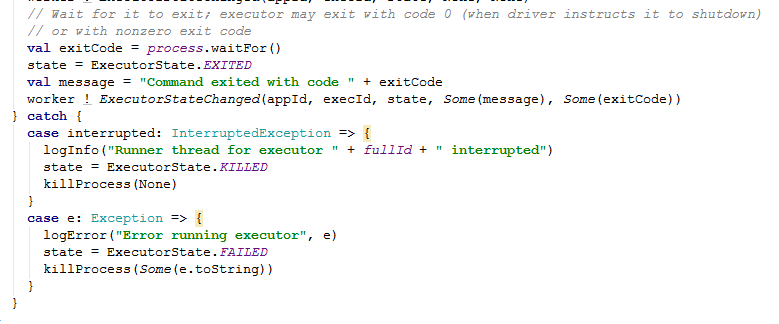
在start()方法中run调用的是fetchAndRunExecutor,解析这个方法有如下几个步骤:
1)创建ExecutorBackend进程需要的工作目录
2)将Executor相关信息封装成Command
3)使用process = builder.start()启动ExecutorBackend
4)重定向其输出和错误的文件
源码内容如下:
LaunchDriver
和LaunchExecutor事件类似
1、初始化DriverRunner
2、添加到drivers队列这是个HashSet drivers(driverId) = driver
3、启动driver.start()
......
CoarseGrainedSchedulerBackend
CoarseGrainedExecutorBackend是一个单独的进程,同时也是一个Actor,他负责具体Task的执行,同时与Worker、Driver都有通讯。它负责处理的事件:RegisteredExecutor、RegisterExecutorFailed、LaunchTask、KillTask、DisassociatedEvent、StopExecutor。下面具体看下几个事件源码。
RegisteredExecutor
它的操作就是初始化一个Executor对象

LaunchTask
LaunchTask事件调用在RegisteredExecutor已经初始化的Executor对象中的launchTask方法来加载运行。具体源码如下:
跟踪executor.launchTask代码:
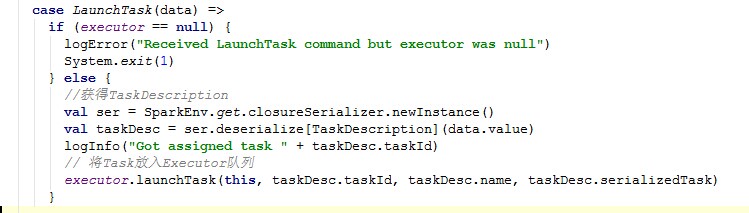
这里初始化了一个TaskRunner,这个对象实现了Runnable接口,每个任务对应一个TaskRunner。
在TaskRunner重写的run方法中
1)设置spark-evn,这里的配置参数在spark-evn.sh文件中有配置和说明。
2)将当前的Task状态改为running
3)反序列化Task运行需要的类和文件
4)在updateDependencies方法中,如果没有相关jar等文件需要通过Utils.fetchFile(name,new File(SparkFiles.getRootDirectory),conf, env.securityManager)获取
5)反序列化Task对象
6)调用run
7)序列化结构
8)判断将结构写入磁盘
9)汇报结构给Driver
10)移除当前任务
具体run方法源码如下:
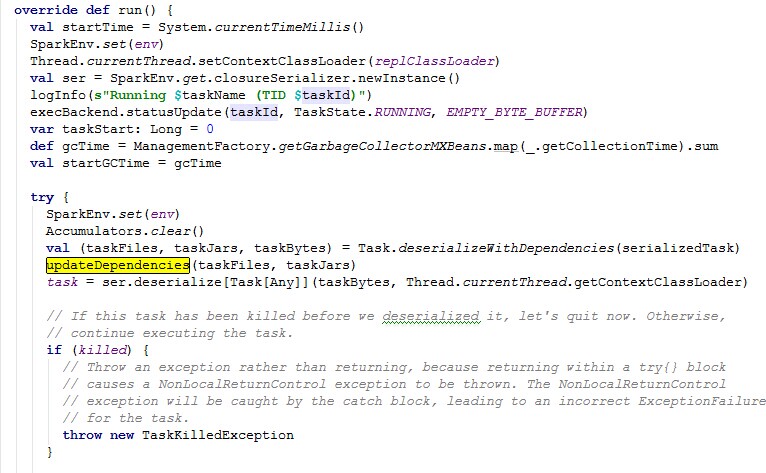

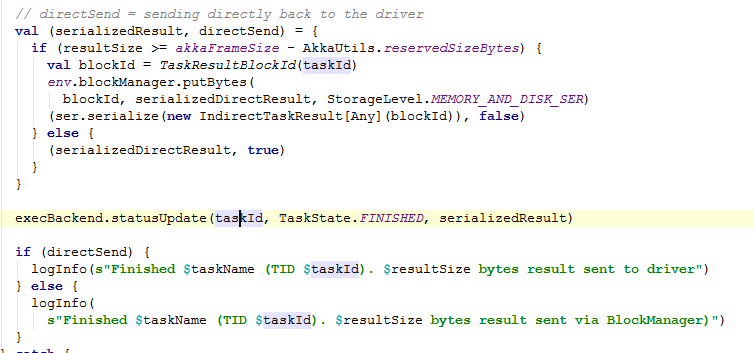
DAGScheduler
DAGScheduler是stage导向的高级别调度层,负责接收用户提交的Job,根据RDD的依赖关系划分不同的stage,并将tastSet提交给底层的TaskScheduler实现。

DAGScheduler构造函数
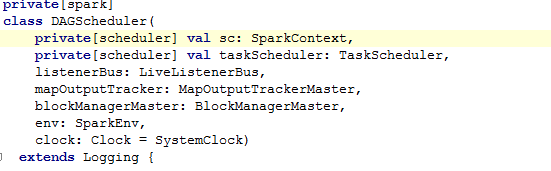
下面给构造函数中的参数进行简单的介绍:
SparkContext:是所有spark程序的接口,无论用户提交什么任务,都需要实例化 SparkContextx。然后基于这个sc进行RDD操作
TaskScheduler:是低级别的任务调度程序的接口,目前由TaskSchedulerImpl完全实现。
LiveListenerBus:异步注册Spark监听
MapOutputTrackerMaster:是一个driver。这使用TimeStampedHashMap跟踪map输出信息, 它允许根据一个TTL旧输出信息。
BlockManagerMaster:高层级别的Block总管,它管理所有的BlockManager,BolckManager 又管理着Bolck的Storage
SparkEnv:环境配置信息,这个在spark-env中阅读过
Clock:测试使用
在DAGScheduler内部有一个DAGSchedulerEventProcessActor类,它是一个Actor,这里DAGScheduler所有的时间由它来处理
DAGSchedulerEventProcessActor
DAGSchedulerEventProcessActor处理的主要事件有:JobSubmitted、StageCancelled、JobCancelled...... 从它的源码中可以看到事件处理都非常的简单直接掉用DAGSchudler中的方法。下面的源码内容:
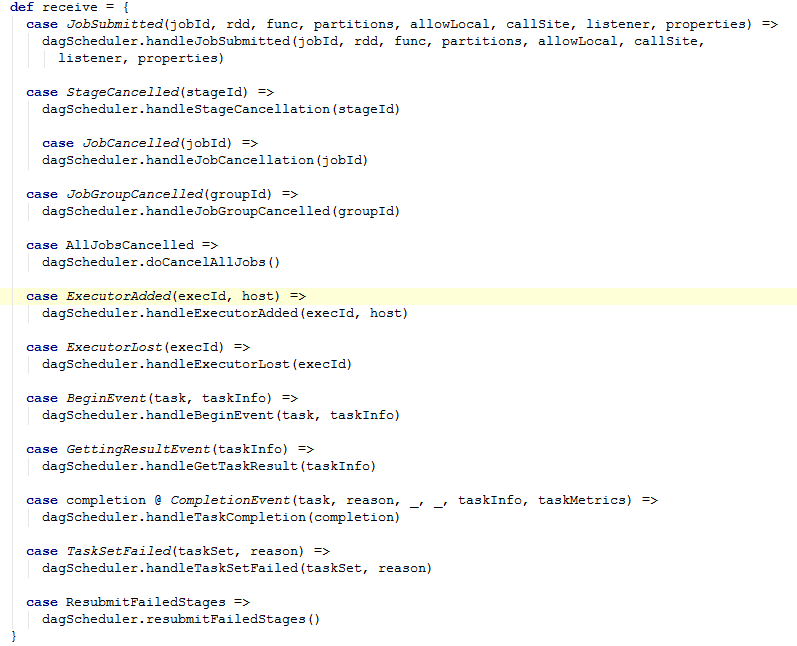
接下来,从SparkContext中的一个runJob任务来分析DAGScheduler。
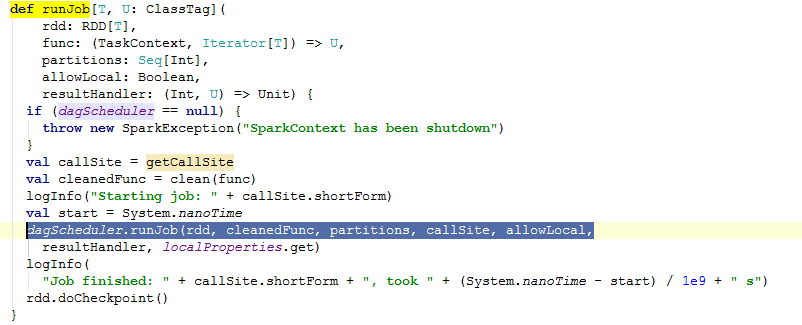
上图中阴影部分的代码调用了dagScheduler.runJob,点击源码进行跟踪,一路会跟踪到DAGScheduler中的submitJob

上面源码中,Job提交触发了DAGSchedulerEventProcessActor中的JobSubmitted事件(eventProcessActor ! JobSubmitted)。而这个事件调用的是:dagScheduler.handleJobSubmitted(jobId,rdd, func, partitions, allowLocal, callSite,
listener, properties)。
在这个方法中调用newStage(finalRDD,partitions.size, None, jobId, callSite)创建一个stage。
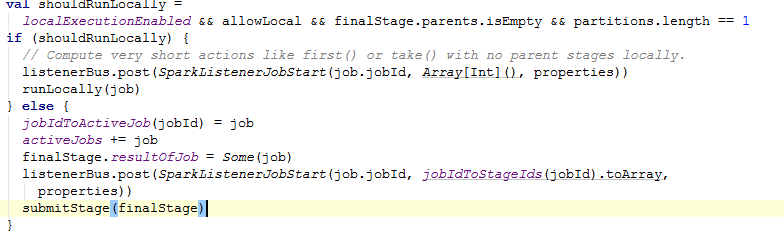
接下来有一个判断,当上面创建的stage不为空,它又创建了一个job,看源码:

第一次调用的job只有一个partition没有其他的依赖关系,这个线程会使用本地线程处理,如果并非本地运行的job,它会提交stage。源码如下:
这里的submitStage方法如下:
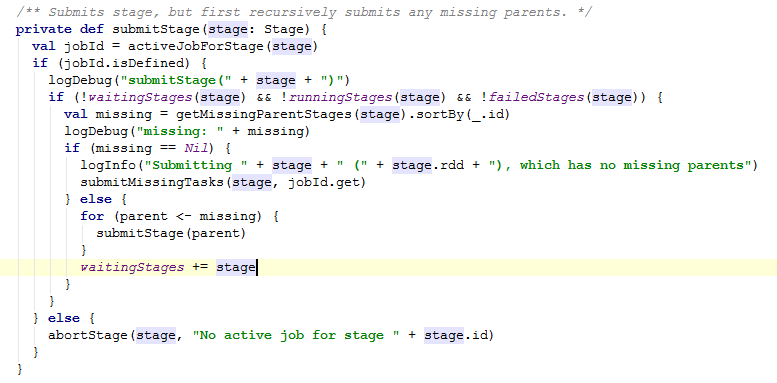
它主要计算stage之间的依赖关系,并对依赖关系进行处理。怎么处理呢,当然是从父stage中查找,如果查找不到的话,则提交Task任务,并且将当前的stage放进runningStage中。如果查找到了父stage,则先提交父stage,让后将它放入到队列中。这里看得出来,stage的调度是从后往前来查找各个依赖的stage。
源码中的getMissingParentStages就是对父stage的查找,首先根据当前的stage中的RDD,得到RDD的依赖关系。在宽依赖的情况下,则生成一个mapStage作为当前stage的父stage,窄依赖则不会生成。
接下来到了submitMissingTasks(stage: Stage, jobId: Int)这个方法。他是根据当前的stage所依赖的RDD的partition的分布,来产生partition数量相等的Task。如果当前的Stage是MapStage类型,则产生ShuffleMapTask,否则产生ResultTask。Task的位置都是通过getPreferredLocs方法计算得到的。下面具体看下 submitMissingTasks方法源码:
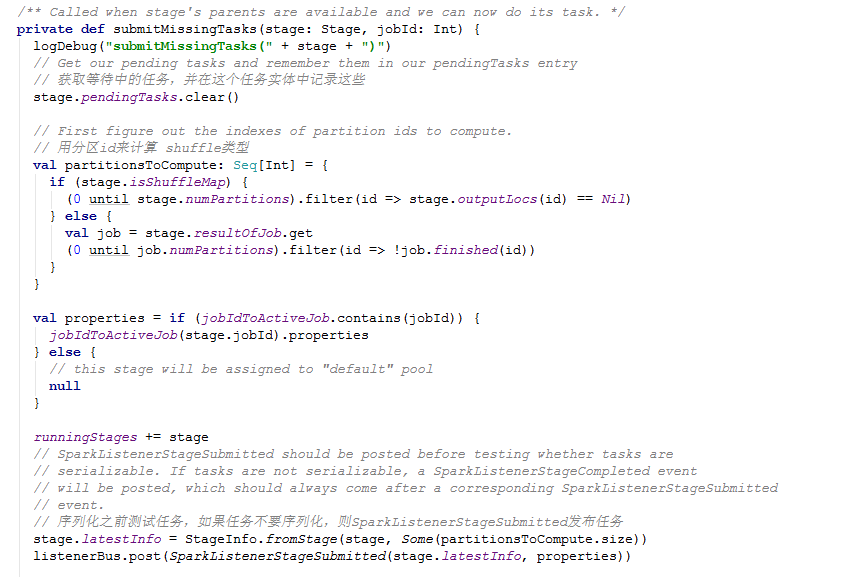

TaskScheduler
TaskScheduler是低级别的任务调度程序的接口,目前由TaskSchedulerImpl完全实现。该接口允许插入不同的任务调度。每个的TaskScheduler调度任务用于单个SparkContext。接收DAGScheduler提交的taskSet,并负责发送任务到集群,运行它们,重试,并且为每个TaskSet维护了一个TaskSetManager(追踪错误信息等)。
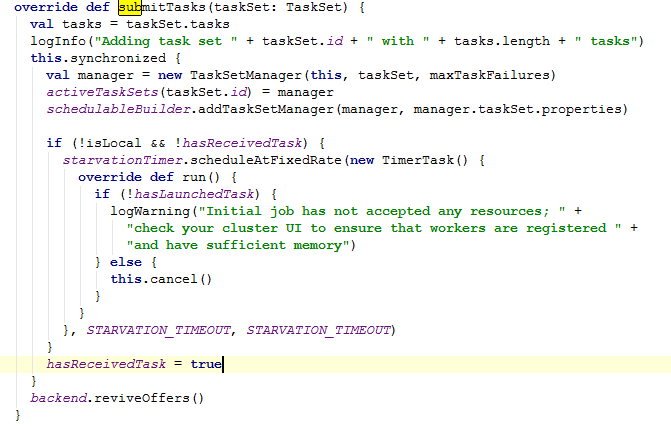
在不同的集群模式下针对TaskScheduler的实现也就不同了,在standalone的模式下的实现是TaskSchedulerImpl。在上节中的DAGScheduler的源码阅读中job任务提交到了TaskScheduler中的submitTasks方法。现在具体来跟踪这个方法的代码,源码如下:
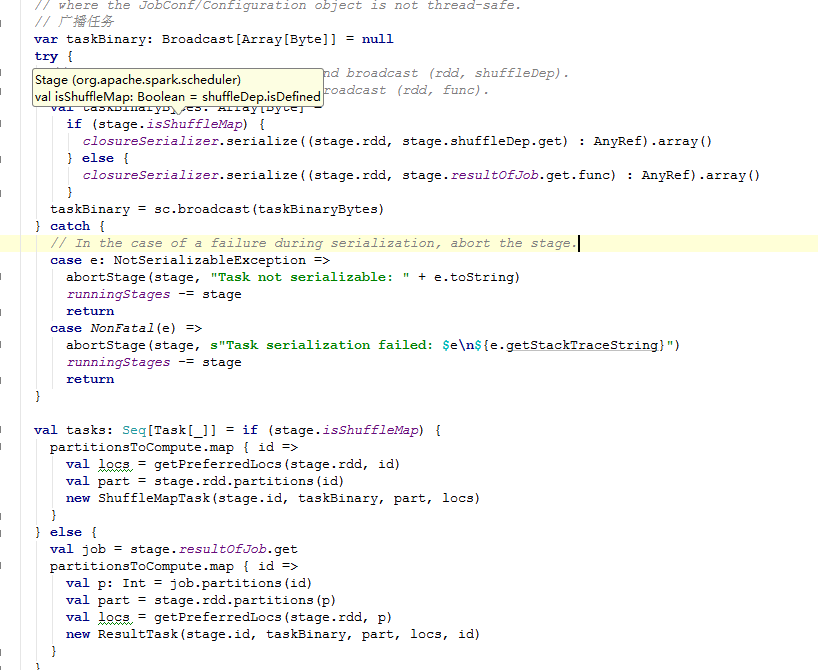
在这个方法中的代码流程
1)根据taskSet等参数首先封装了TaskSetManager。这个类用此类跟踪每个任务,重试任务 如果失败(最多的有限次数)它负责taskSet中Task的启动、重启、本地化处理等。
2)将TaskSetManager添加到调度器中SchedulableBuilder。SchedulableBuilder有两种调度模 式实现FIFOSchedulableBuilder、FairSchedulableBuilder。这调度模式可以用 “spark.scheduler.mode”属性指定
3)请求资源,执行Task。根据源码跟踪到了CoarseGrainedSchedulerBackend中的makeOffers 方法。源码如下:

4)根据上面launchTasks方法中的参数是resourceOffers方法,跟踪进去。这个resourceOffers 方法通过集群管理器调用,向salves提供资源。下面是源码:
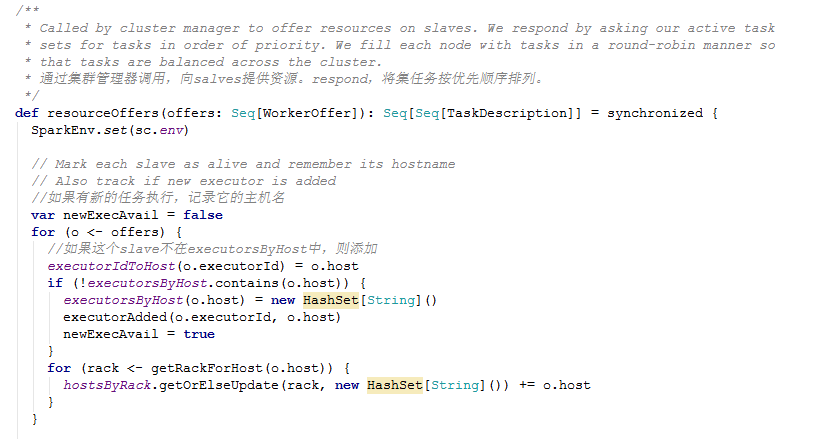
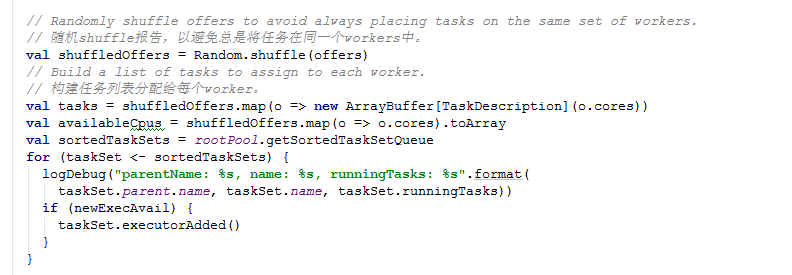
















 1543
1543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









