






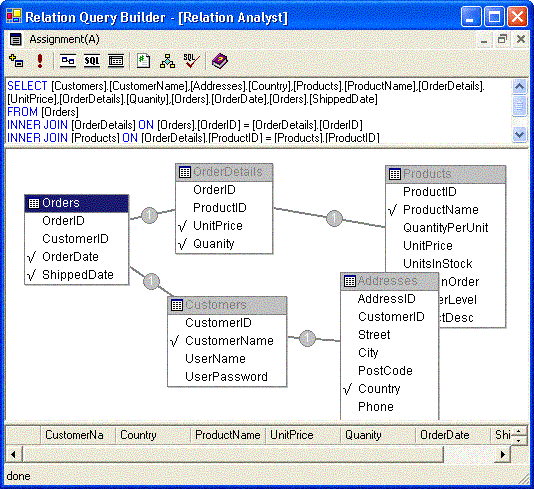
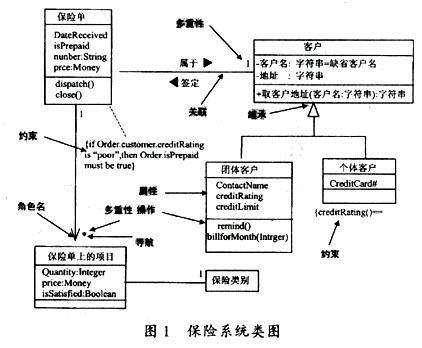
| 模式-> | 属性 | 属性 | 属性 | 属性 | 属性 | 属性 | 属性 |
| 记录 | Name | Id | Gender | Address | post | Age | salary |
| 记录 | *** | ||||||
| 记录 | *** | ||||||
| *** | *** | ||||||
| *** | *** |

<img alt="" src="http://writeblog.csdn.net/Editor/FCKeditor/editor/%3Chtml%3E%20%20%20%20%3Chead%3E%20%20%20%20%20%20%20%20%3Ctitle%3E%E9%8D%99%E5%82%9B%E6%9A%9F%E9%8F%83%E7%8A%B3%E6%99%A5%E9%8A%86?/title%3E%20%20%20%20%20%20%20%20%3Cstyle%3E%20%20%20%20%20%20%20%20%20body%20{font-family:%22Verdana%22;font-weight:normal;font-size:%20.7em;color:black;}%20%20%20%20%20%20%20%20%20%20p%20{font-family:%22Verdana%22;font-weight:normal;color:black;margin-top:%20-5px}%20%20%20%20%20%20%20%20%20b%20{font-family:%22Verdana%22;font-weight:bold;color:black;margin-top:%20-5px}%20%20%20%20%20%20%20%20%20H1%20{%20font-family:%22Verdana%22;font-weight:normal;font-size:18pt;color:red%20}%20%20%20%20%20%20%20%20%20H2%20{%20font-family:%22Verdana%22;font-weight:normal;font-size:14pt;color:maroon%20}%20%20%20%20%20%20%20%20%20pre%20{font-family:%22Lucida%20Console%22;font-size:%20.9em}%20%20%20%20%20%20%20%20%20.marker%20{font-weight:%20bold;%20color:%20black;text-decoration:%20none;}%20%20%20%20%20%20%20%20%20.version%20{color:%20gray;}%20%20%20%20%20%20%20%20%20.error%20{margin-bottom:%2010px;}%20%20%20%20%20%20%20%20%20.expandable%20{%20text-decoration:underline;%20font-weight:bold;%20color:navy;%20cursor:hand;%20}%20%20%20%20%20%20%20%20%3C/style%3E%20%20%20%20%3C/head%3E%20%20%20%20%3Cbody%20bgcolor=%22white%22%3E%20%20%20%20%20%20%20%20%20%20%20%20%3Cspan%3E%3Cdiv%3E%3Cb%3E%3Cfont%20size=%226%22%3E%E9%88%A5?%E9%88%A5%E6%BF%86%E7%B0%B2%E9%90%A2%E3%84%A7%E2%96%BC%E6%90%B4%E5%BF%8E%E8%85%91%E9%90%A8%E5%8B%AC%E6%B9%87%E9%8D%94%E2%80%B3%E6%AB%92%E9%96%BF%E6%AC%92%EE%87%A4%E9%8A%86?hr%20width=100%%20size=1%20color=silver%3E%3C/font%3E%3C/b%3E%3C/div%3E%20%20%20%20%20%20%20%20%20%20%20%20%3Cdiv%3E%3Cb%3E%3Cfont%20size=%225%22%3E%20%3Ci%3E%E9%8D%99%E5%82%9B%E6%9A%9F%E9%8F%83%E7%8A%B3%E6%99%A5%E9%8A%86?/i%3E%20%3C/font%3E%3C/b%3E%3C/div%3E%3C/span%3E%20%20%20%20%20%20%20%20%20%20%20%20%3Cfont%20face=%22Arial,%20Helvetica,%20Geneva,%20SunSans-Regular,%20sans-serif%20%22%3E%20%20%20%20%20%20%20%20%20%20%20%20%3Cb%3E%20%E7%92%87%E5%AD%98%E6%A7%91:%20%3C/b%3E%E9%8E%B5%D1%86%EE%94%91%E8%A4%B0%E6%92%B3%E5%A2%A0%20Web%20%E7%92%87%E9%94%8B%E7%9C%B0%E9%8F%88%E7%86%BC%E6%A3%BF%E9%94%9B%E5%B1%BD%E5%9A%AD%E9%90%9C%E7%89%88%E6%B9%AD%E6%BE%B6%E5%8B%AD%E6%82%8A%E9%90%A8%E5%8B%AB%E7%B4%93%E7%94%AF%E6%90%9E%E2%82%AC%E5%82%9D%EE%87%AC%E5%A6%AB%E2%82%AC%E9%8F%8C%E3%83%A5%E7%88%A2%E9%8F%8D%E5%A0%A3%E7%AA%A1%E9%9F%AA%EE%81%83%E4%BF%8A%E9%8E%AD%EE%88%A4%E7%B4%9D%E6%B5%A0%E3%83%A4%E7%B0%A1%E7%91%99%EF%BD%86%E6%B9%81%E9%8D%8F%E5%AE%A0%EE%87%9A%E9%96%BF%E6%AC%92%EE%87%A4%E6%B5%A0%E3%83%A5%E5%BC%B7%E6%B5%A0%EF%BD%87%E7%88%9C%E6%B6%93%EE%85%9E%EE%87%B1%E9%91%B7%E6%92%AE%E6%95%8A%E7%92%87%EE%88%9C%E6%AE%91%E9%8D%91%E5%93%84%EE%98%A9%E9%90%A8%E5%8B%AE%EE%87%9B%E7%BC%81%E5%97%95%E4%BF%8A%E9%8E%AD%EE%88%98%E2%82%AC?%20%20%20%20%20%20%20%20%20%20%20%20%3Cbr%3E%3Cbr%3E%20%20%20%20%20%20%20%20%20%20%20%20%3Cb%3E%20%E5%AF%AE%E5%82%9A%E7%88%B6%E7%92%87%EF%B8%BE%E7%B2%8F%E6%B7%87%E2%84%83%E4%BC%85:%20%3C/b%3ESystem.ArgumentException:%20%E9%8D%99%E5%82%9B%E6%9A%9F%E9%8F%83%E7%8A%B3%E6%99%A5%E9%8A%86?br%3E%3Cbr%3E%20%20%20%20%20%20%20%20%20%20%20%20%3Cb%3E%E5%A9%A7%E6%84%B0%E6%95%8A%E7%92%87?%3C/b%3E%20%3Cbr%3E%3Cbr%3E%20%20%20%20%20%20%20%20%20%20%20%20%3Ctable%20width=100%%20bgcolor=%22#ffffcc"> <tr> <td> <code>鍙湁鍦ㄨ皟璇曟ā寮忎笅杩涜缂栬瘧鏃讹紝鐢熸垚姝ゆ湭澶勭悊寮傚父鐨勬簮浠g爜鎵嶄細鏄剧ず鍑烘潵銆傝嫢瑕佸惎鐢ㄦ鍔熻兘锛岃鎵ц浠ヤ笅姝ラ涔嬩竴锛岀劧鍚庤姹?URL: <br><br>1. 鍦ㄤ骇鐢熼敊璇殑鏂囦欢鐨勯《閮ㄦ坊鍔犱竴鏉♀€淒ebug=true鈥濇寚浠ゃ€備緥濡? <br><br> <%@ Page Language="C" Debug="true" %><br><br>鎴?<br><br>2. 灏嗕互涓嬬殑鑺傛坊鍔犲埌搴旂敤绋嬪簭鐨勯厤缃枃浠朵腑:<br><br><configuration><br> <system.web><br> <compilation debug="true"/><br> </system.web><br></configuration><br><br> 璇锋敞鎰忥紝绗簩涓楠ゅ皢浣跨粰瀹氬簲鐢ㄧ▼搴忎腑鐨勬墍鏈夋枃浠跺湪璋冭瘯妯″紡涓嬭繘琛岀紪璇戯紱绗竴涓楠や粎浣胯鐗瑰畾鏂囦欢鍦ㄨ皟璇曟ā寮忎笅杩涜缂栬瘧銆?br><br>閲嶈浜嬮」: 浠ヨ皟璇曟ā寮忚繍琛屽簲鐢ㄧ▼搴忎竴瀹氫細浜х敓鍐呭瓨/鎬ц兘绯荤粺寮€閿€銆傚湪閮ㄧ讲鍒扮敓浜ф柟妗堜箣鍓嶏紝搴旂‘淇濆簲鐢ㄧ▼搴忚皟璇曞凡绂佺敤銆?/code> </td> </tr> </table> <br> <b>鍫嗘爤璺熻釜:</b> <br><br> <table width=100% bgcolor="ffffcc"> <tr> <td> <code><pre>[ArgumentException: 鍙傛暟鏃犳晥銆俔 System.Drawing.Image.FromStream(Stream stream, Boolean useEmbeddedColorManagement, Boolean validateImageData) +388134 System.Drawing.Image.FromStream(Stream stream) +8 Dottext.Admin.UploadWord.SaveFile(HttpPostedFile File) +32 Dottext.Admin.UploadWord.Page_Load(Object sender, EventArgs e) +76 System.Web.Util.CalliHelper.EventArgFunctionCaller(IntPtr fp, Object o, Object t, EventArgs e) +15 System.Web.Util.CalliEventHandlerDelegateProxy.Callback(Object sender, EventArgs e) +34 System.Web.UI.Control.OnLoad(EventArgs e) +99 System.Web.UI.Control.LoadRecursive() +47 System.Web.UI.Page.ProcessRequestMain(Boolean includeStagesBeforeAsyncPoint, Boolean includeStagesAfterAsyncPoint) +1061</pre></code> </td> </tr> </table> <br> <hr width=100% size=1 color=silver> <b>鐗堟湰淇℃伅:</b> Microsoft .NET Framework 鐗堟湰:2.0.50727.832; ASP.NET 鐗堟湰:2.0.50727.832 </font> </body></html><!-- [ArgumentException]: 鍙傛暟鏃犳晥銆? 鍦?System.Drawing.Image.FromStream(Stream stream, Boolean useEmbeddedColorManagement, Boolean validateImageData) 鍦?System.Drawing.Image.FromStream(Stream stream) 鍦?Dottext.Admin.UploadWord.SaveFile(HttpPostedFile File) 鍦?Dottext.Admin.UploadWord.Page_Load(Object sender, EventArgs e) 鍦?System.Web.Util.CalliHelper.EventArgFunctionCaller(IntPtr fp, Object o, Object t, EventArgs e) 鍦?System.Web.Util.CalliEventHandlerDelegateProxy.Callback(Object sender, EventArgs e) 鍦?System.Web.UI.Control.OnLoad(EventArgs e) 鍦?System.Web.UI.Control.LoadRecursive() 鍦?System.Web.UI.Page.ProcessRequestMain(Boolean includeStagesBeforeAsyncPoint, Boolean includeStagesAfterAsyncPoint)[HttpUnhandledException]: 寮曞彂绫诲瀷涓衡€淪ystem.Web.HttpUnhandledException鈥濈殑寮傚父銆? 鍦?System.Web.UI.Page.HandleError(Exception e) 鍦?System.Web.UI.Page.ProcessRequestMain(Boolean includeStagesBeforeAsyncPoint, Boolean includeStagesAfterAsyncPoint) 鍦?System.Web.UI.Page.ProcessRequest(Boolean includeStagesBeforeAsyncPoint, Boolean includeStagesAfterAsyncPoint) 鍦?System.Web.UI.Page.ProcessRequest() 鍦?System.Web.UI.Page.ProcessRequestWithNoAssert(HttpContext context) 鍦?System.Web.UI.Page.ProcessRequest(HttpContext context) 鍦?ASP.uploadword_aspx.ProcessRequest(HttpContext context) 鍦?System.Web.HttpApplication.CallHandlerExecutionStep.System.Web.HttpApplication.IExecutionStep.Execute() 鍦?System.Web.HttpApplication.ExecuteStep(IExecutionStep step, Boolean& completedSynchronously)--><!-- 姝ら敊璇〉鍙兘鍖呭惈鏁忔劅淇℃伅锛屽洜涓?ASP.NET 閫氳繃 <customErrors mode=" off"="" >="" 琚厤缃负鏄剧ず璇︾粏閿欒淇℃伅銆傝鑰冭檻鍦ㄧ敓浜х幆澧冧腑浣跨敤="" <customerrors="" mode="On" 鎴?<customerrors="" >銆?-="" style="border-top-style: none; border-right-style: none; border-bottom-style: none; border-left-style: none; border-width: initial; border-color: initial; border-image: initial; ">'>1
| 企业名称 | 工商登记号 | 经营地址 | 纳税号 | 财务主管 |
| 甲 | 1 | 胡同口 | 45661 | Mary |
| 乙 | ⊥ | ⊥ | 214555 | John |
| 丙 | 2 | 大坡 | 225553 | Lion |
| 丁 | 3 | 河畔路 | ⊥ | ⊥ |
| 企业4 | 4 | 开发区 | ⊥ | ⊥ |
| 企业5 | 5 | 创业园 | ⊥ | ⊥ |
|
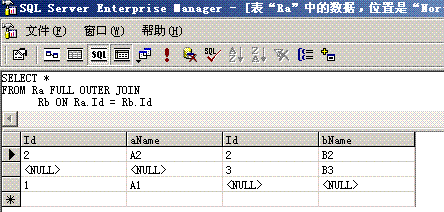
关系
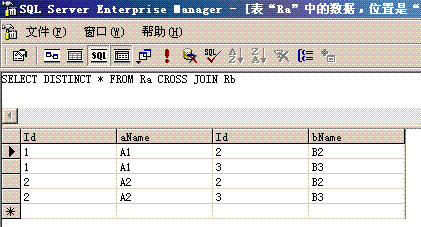
Ra
Id aName
|
关系
Rb
Id bName
| |||
| 1 | A1 | 2 | B2 | |
| 2 | A2 | 3 | B3 | |
|
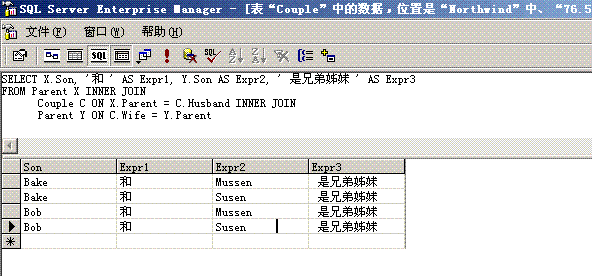
Relation: Parent
| |
|
Parent
|
Son
|
| JaSen | Tom |
| JaSen | Jack |
| Larry | Bob |
| Larry | Bake |
| Batti | Susen |
| Batti | Mussen |
|
| |
|
Relation: Couple
| |
|
Husband
|
Wife
|
| Larry | Batti |
| … | … |
|
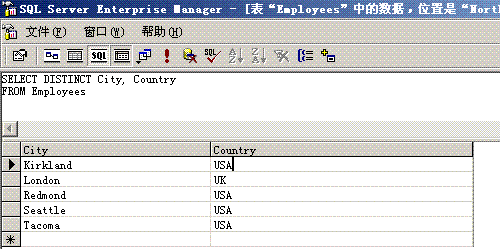
Asp
中用顺序号引用数据
|
Asp.net
中用属性名引用数据
|
|
Set RS=newconn.Execute(SQLcmd)
For i=0 To RS.Fields.Count-1
=RS(i)
Next
|
While(DataReader.Read())
{
int myAge=DataReader.GetInt32
(DataReader.GetOrdinal(“age”))
}
|

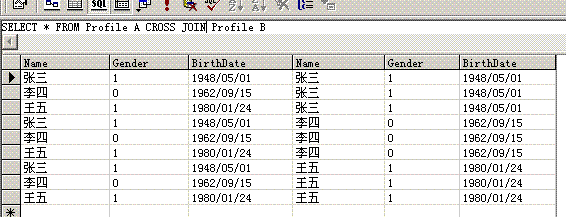
|
Name
|
Gender
|
BirthDate
|
| 张三 |
1
|
1948/5/1
|
| 李四 |
0
|
1962/9/15
|
| 王五 |
1
|
1980/1/24
|
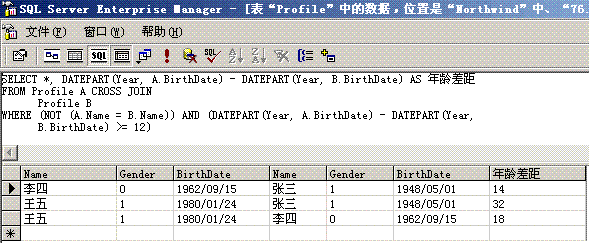
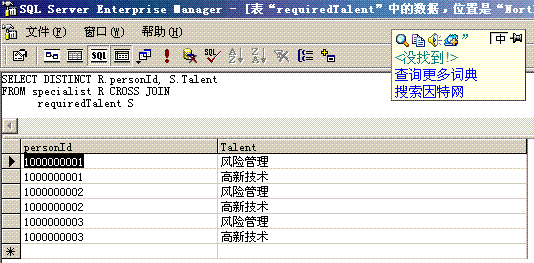
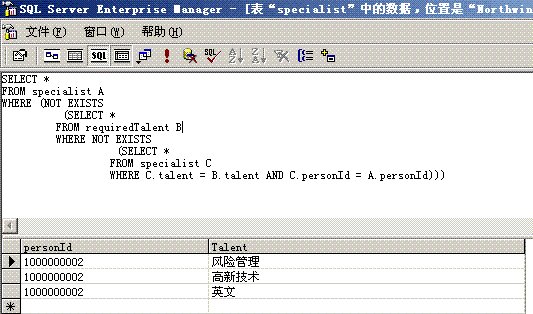
|
PersonId
|
Talent
|
| 1000000001 | 一级厨师—川菜系 |
| 1000000001 | 一级厨师—鲁菜系 |
| 1000000001 | 一级厨师—西式面点 |
| 1000000002 | 风险管理 |
| 1000000002 | 高新技术 |
| 1000000002 | 英文 |
| 1000000003 | 项目管理 |
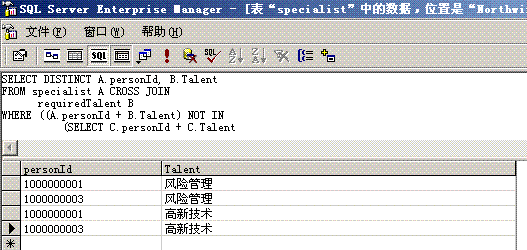
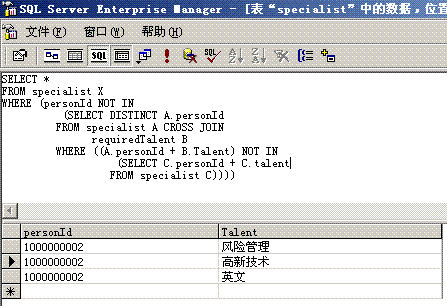

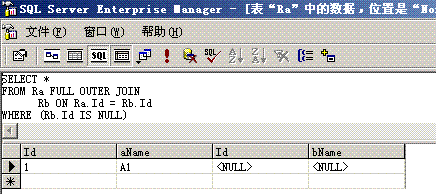
连接运算也是使用比较频繁的一种二元运算,它用来根据一定的关系把两个关系连接成一个关系,两个关系R和S的连接运算定义形式是R 1S,其中i和j表示关系R的第i列和关系S的第j列,θ表示比较运算。从原理上讲,连接运算是一种比较特殊的选择运算,即两个关系的连接是在两个关系的笛卡尔积的基础之上把连接关系作为选择关系对笛卡尔积执行选择运算,这个选择运算涉及到两个关系的两个字段的比较运算。我们写出连接运算的等价公式:
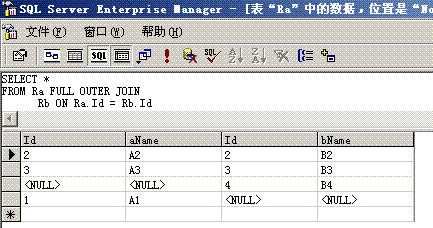
δR.i θ S.j(R×S)例如:Ra <img src="http://blog.csdn.net/jinweifu/article/details/%3Chtml%3E%20%20%20%20%3Chead%3E%20%20%20%20%20%20%20%20%3Ctitle%3E%E9%8D%99%E5%82%9B%E6%9A%9F%E9%8F%83%E7%8A%B3%E6%99%A5%E9%8A%86?/title%3E%20%20%20%20%20%20%20%20%3Cstyle%3E%20%20%20%20%20%20%20%20%20body%20{font-family:%22Verdana%22;font-weight:normal;font-size:%20.7em;color:black;}%20%20%20%20%20%20%20%20%20%20p%20{font-family:%22Verdana%22;font-weight:normal;color:black;margin-top:%20-5px}%20%20%20%20%20%20%20%20%20b%20{font-family:%22Verdana%22;font-weight:bold;color:black;margin-top:%20-5px}%20%20%20%20%20%20%20%20%20H1%20{%20font-family:%22Verdana%22;font-weight:normal;font-size:18pt;color:red%20}%20%20%20%20%20%20%20%20%20H2%20{%20font-family:%22Verdana%22;font-weight:normal;font-size:14pt;color:maroon%20}%20%20%20%20%20%20%20%20%20pre%20{font-family:%22Lucida%20Console%22;font-size:%20.9em}%20%20%20%20%20%20%20%20%20.marker%20{font-weight:%20bold;%20color:%20black;text-decoration:%20none;}%20%20%20%20%20%20%20%20%20.version%20{color:%20gray;}%20%20%20%20%20%20%20%20%20.error%20{margin-bottom:%2010px;}%20%20%20%20%20%20%20%20%20.expandable%20{%20text-decoration:underline;%20font-weight:bold;%20color:navy;%20cursor:hand;%20}%20%20%20%20%20%20%20%20%3C/style%3E%20%20%20%20%3C/head%3E%20%20%20%20%3Cbody%20bgcolor=%22white%22%3E%20%20%20%20%20%20%20%20%20%20%20%20%3Cspan%3E%3Cdiv%3E%3Cb%3E%3Cfont%20size=%226%22%3E%E9%88%A5?%E9%88%A5%E6%BF%86%E7%B0%B2%E9%90%A2%E3%84%A7%E2%96%BC%E6%90%B4%E5%BF%8E%E8%85%91%E9%90%A8%E5%8B%AC%E6%B9%87%E9%8D%94%E2%80%B3%E6%AB%92%E9%96%BF%E6%AC%92%EE%87%A4%E9%8A%86?hr%20width=100%%20size=1%20color=silver%3E%3C/font%3E%3C/b%3E%3C/div%3E%20%20%20%20%20%20%20%20%20%20%20%20%3Cdiv%3E%3Cb%3E%3Cfont%20size=%225%22%3E%20%3Ci%3E%E9%8D%99%E5%82%9B%E6%9A%9F%E9%8F%83%E7%8A%B3%E6%99%A5%E9%8A%86?/i%3E%20%3C/font%3E%3C/b%3E%3C/div%3E%3C/span%3E%20%20%20%20%20%20%20%20%20%20%20%20%3Cfont%20face=%22Arial,%20Helvetica,%20Geneva,%20SunSans-Regular,%20sans-serif%20%22%3E%20%20%20%20%20%20%20%20%20%20%20%20%3Cb%3E%20%E7%92%87%E5%AD%98%E6%A7%91:%20%3C/b%3E%E9%8E%B5%D1%86%EE%94%91%E8%A4%B0%E6%92%B3%E5%A2%A0%20Web%20%E7%92%87%E9%94%8B%E7%9C%B0%E9%8F%88%E7%86%BC%E6%A3%BF%E9%94%9B%E5%B1%BD%E5%9A%AD%E9%90%9C%E7%89%88%E6%B9%AD%E6%BE%B6%E5%8B%AD%E6%82%8A%E9%90%A8%E5%8B%AB%E7%B4%93%E7%94%AF%E6%90%9E%E2%82%AC%E5%82%9D%EE%87%AC%E5%A6%AB%E2%82%AC%E9%8F%8C%E3%83%A5%E7%88%A2%E9%8F%8D%E5%A0%A3%E7%AA%A1%E9%9F%AA%EE%81%83%E4%BF%8A%E9%8E%AD%EE%88%A4%E7%B4%9D%E6%B5%A0%E3%83%A4%E7%B0%A1%E7%91%99%EF%BD%86%E6%B9%81%E9%8D%8F%E5%AE%A0%EE%87%9A%E9%96%BF%E6%AC%92%EE%87%A4%E6%B5%A0%E3%83%A5%E5%BC%B7%E6%B5%A0%EF%BD%87%E7%88%9C%E6%B6%93%EE%85%9E%EE%87%B1%E9%91%B7%E6%92%AE%E6%95%8A%E7%92%87%EE%88%9C%E6%AE%91%E9%8D%91%E5%93%84%EE%98%A9%E9%90%A8%E5%8B%AE%EE%87%9B%E7%BC%81%E5%97%95%E4%BF%8A%E9%8E%AD%EE%88%98%E2%82%AC?%20%20%20%20%20%20%20%20%20%20%20%20%3Cbr%3E%3Cbr%3E%20%20%20%20%20%20%20%20%20%20%20%20%3Cb%3E%20%E5%AF%AE%E5%82%9A%E7%88%B6%E7%92%87%EF%B8%BE%E7%B2%8F%E6%B7%87%E2%84%83%E4%BC%85:%20%3C/b%3ESystem.ArgumentException:%20%E9%8D%99%E5%82%9B%E6%9A%9F%E9%8F%83%E7%8A%B3%E6%99%A5%E9%8A%86?br%3E%3Cbr%3E%20%20%20%20%20%20%20%20%20%20%20%20%3Cb%3E%E5%A9%A7%E6%84%B0%E6%95%8A%E7%92%87?%3C/b%3E%20%3Cbr%3E%3Cbr%3E%20%20%20%20%20%20%20%20%20%20%20%20%3Ctable%20width=100%%20bgcolor=%22#ffffcc"> <tr> <td> <code>鍙湁鍦ㄨ皟璇曟ā寮忎笅杩涜缂栬瘧鏃讹紝鐢熸垚姝ゆ湭澶勭悊寮傚父鐨勬簮浠g爜鎵嶄細鏄剧ず鍑烘潵銆傝嫢瑕佸惎鐢ㄦ鍔熻兘锛岃鎵ц浠ヤ笅姝ラ涔嬩竴锛岀劧鍚庤姹?URL: <br><br>1. 鍦ㄤ骇鐢熼敊璇殑鏂囦欢鐨勯《閮ㄦ坊鍔犱竴鏉♀€淒ebug=true鈥濇寚浠ゃ€備緥濡? <br><br> <%@ Page Language="C#" Debug="true" %><br><br>鎴?<br><br>2. 灏嗕互涓嬬殑鑺傛坊鍔犲埌搴旂敤绋嬪簭鐨勯厤缃枃浠朵腑:<br><br><configuration><br> <system.web><br> <compilation debug="true"/><br> </system.web><br></configuration><br><br> 璇锋敞鎰忥紝绗簩涓楠ゅ皢浣跨粰瀹氬簲鐢ㄧ▼搴忎腑鐨勬墍鏈夋枃浠跺湪璋冭瘯妯″紡涓嬭繘琛岀紪璇戯紱绗竴涓楠や粎浣胯鐗瑰畾鏂囦欢鍦ㄨ皟璇曟ā寮忎笅杩涜缂栬瘧銆?br><br>閲嶈浜嬮」: 浠ヨ皟璇曟ā寮忚繍琛屽簲鐢ㄧ▼搴忎竴瀹氫細浜х敓鍐呭瓨/鎬ц兘绯荤粺寮€閿€銆傚湪閮ㄧ讲鍒扮敓浜ф柟妗堜箣鍓嶏紝搴旂‘淇濆簲鐢ㄧ▼搴忚皟璇曞凡绂佺敤銆?/code> </td> </tr> </table> <br> <b>鍫嗘爤璺熻釜:</b> <br><br> <table width=100% bgcolor="#ffffcc"> <tr> <td> <code><pre>[ArgumentException: 鍙傛暟鏃犳晥銆俔 System.Drawing.Image.FromStream(Stream stream, Boolean useEmbeddedColorManagement, Boolean validateImageData) +388134 System.Drawing.Image.FromStream(Stream stream) +8 Dottext.Admin.UploadWord.SaveFile(HttpPostedFile File) +32 Dottext.Admin.UploadWord.Page_Load(Object sender, EventArgs e) +76 System.Web.Util.CalliHelper.EventArgFunctionCaller(IntPtr fp, Object o, Object t, EventArgs e) +15 System.Web.Util.CalliEventHandlerDelegateProxy.Callback(Object sender, EventArgs e) +34 System.Web.UI.Control.OnLoad(EventArgs e) +99 System.Web.UI.Control.LoadRecursive() +47 System.Web.UI.Page.ProcessRequestMain(Boolean includeStagesBeforeAsyncPoint, Boolean includeStagesAfterAsyncPoint) +1061</pre></code> </td> </tr> </table> <br> <hr width=100% size=1 color=silver> <b>鐗堟湰淇℃伅:</b> Microsoft .NET Framework 鐗堟湰:2.0.50727.832; ASP.NET 鐗堟湰:2.0.50727.832 </font> </body></html><!-- [ArgumentException]: 鍙傛暟鏃犳晥銆? 鍦?System.Drawing.Image.FromStream(Stream stream, Boolean useEmbeddedColorManagement, Boolean validateImageData) 鍦?System.Drawing.Image.FromStream(Stream stream) 鍦?Dottext.Admin.UploadWord.SaveFile(HttpPostedFile File) 鍦?Dottext.Admin.UploadWord.Page_Load(Object sender, EventArgs e) 鍦?System.Web.Util.CalliHelper.EventArgFunctionCaller(IntPtr fp, Object o, Object t, EventArgs e) 鍦?System.Web.Util.CalliEventHandlerDelegateProxy.Callback(Object sender, EventArgs e) 鍦?System.Web.UI.Control.OnLoad(EventArgs e) 鍦?System.Web.UI.Control.LoadRecursive() 鍦?System.Web.UI.Page.ProcessRequestMain(Boolean includeStagesBeforeAsyncPoint, Boolean includeStagesAfterAsyncPoint)[HttpUnhandledException]: 寮曞彂绫诲瀷涓衡€淪ystem.Web.HttpUnhandledException鈥濈殑寮傚父銆? 鍦?System.Web.UI.Page.HandleError(Exception e) 鍦?System.Web.UI.Page.ProcessRequestMain(Boolean includeStagesBeforeAsyncPoint, Boolean includeStagesAfterAsyncPoint) 鍦?System.Web.UI.Page.ProcessRequest(Boolean includeStagesBeforeAsyncPoint, Boolean includeStagesAfterAsyncPoint) 鍦?System.Web.UI.Page.ProcessRequest() 鍦?System.Web.UI.Page.ProcessRequestWithNoAssert(HttpContext context) 鍦?System.Web.UI.Page.ProcessRequest(HttpContext context) 鍦?ASP.uploadword_aspx.ProcessRequest(HttpContext context) 鍦?System.Web.HttpApplication.CallHandlerExecutionStep.System.Web.HttpApplication.IExecutionStep.Execute() 鍦?System.Web.HttpApplication.ExecuteStep(IExecutionStep step, Boolean& completedSynchronously)--><!-- 姝ら敊璇〉鍙兘鍖呭惈鏁忔劅淇℃伅锛屽洜涓?ASP.NET 閫氳繃 <customErrors mode="Off"/> 琚厤缃负鏄剧ず璇︾粏閿欒淇℃伅銆傝鑰冭檻鍦ㄧ敓浜х幆澧冧腑浣跨敤 <customErrors mode="On"/> 鎴?<customErrors mode="RemoteOnly"/>銆?->" />1Rb</span></p><div><span style="FONT-SIZE: 12pt">这个连接运算用SQL语句表达如下:</span></div><div style="TEXT-INDENT: 30.85pt"><span style="FONT-SIZE: 12pt">SELECT * FROM Ra, Rb WHERE Ra.id = Rb.id</span></div><div align="center"><span style="FONT-SIZE: 12pt"><img alt="" src="https://p-blog.csdn.net/images/p_blog_csdn_net/jinweifu/e4f9af89d5b74f13954303c08512905c.gif" /></span></div><div align="left"><span style="FONT-SIZE: 12pt">又如:</span><span style="FONT-SIZE: 12pt">Select * From Ra, Rb Where Ra.id>Rb.id</span></div><div align="left"><span style="FONT-SIZE: 12pt">再如</span><span style="FONT-SIZE: 12pt">:Select * From Ra, Rb Where Ra.id+Len(Ra.aName)%Ra.id=Rb.id</span></div><div align="left"><span style="FONT-SIZE: 12pt">我们看到了最后一个连接条件是</span><span style="FONT-SIZE: 12pt">Ra.id+Len(Ra.aName)%Ra.id=Rb.id</span><span style="FONT-SIZE: 12pt">,涉及到了</span><span style="FONT-SIZE: 12pt">Ra</span><span style="FONT-SIZE: 12pt">表的两个字段,并且使用了很不容易理解的连接条件,说实话,我也不知道这个连接条件的真实用途(即使是我设计的),但它能够合法运行。</span></div><div align="center"><span style="FONT-SIZE: 12pt"><img alt="" src="https://p-blog.csdn.net/images/p_blog_csdn_net/jinweifu/54e81327c89943228390057f383f4f05.gif" /></span></div><div align="center"><span style="FONT-SIZE: 12pt">Figure 1.2.1.4.2 一个奇怪但合法的连接运算</span></div><div align="left"><strong><span style="FONT-SIZE: 14pt">1.2.1.4.3 自然连接运算(Natural Join)</span></strong></div><div style="TEXT-INDENT: 23.05pt" align="left"><span style="FONT-SIZE: 12pt">自然连接运算是连接运算(Join)的一个子集,是一种特殊的连接运算,它也是两个关系R和S的二元关系代数运算符。自然连接是一个连接,其连接条件是两个关系所有的Common key的键值相等。用描述性的语言就是:</span></div><div align="left"><span style="FONT-SIZE: 10.5pt">relation naturalJoin(relation R, relation S)</span></div><div align="left"><span style="FONT-SIZE: 10.5pt">{ relation CartesianRS=new relation();</span></div><div align="left"><span style="FONT-SIZE: 10.5pt">CartesianRS=R×S; //</span><span style="FONT-SIZE: 10.5pt">先计算两个关系的笛卡尔积</span></div><div align="left"><span style="FONT-SIZE: 10.5pt">Foreach(attribute r in R)</span></div><div align="left"><span style="FONT-SIZE: 10.5pt"> Foreach(attribute s in S)</span></div><div align="left"><span style="FONT-SIZE: 10.5pt"> filterCond=filterCond+r.name=s.name;</span></div><div align="left"><span style="FONT-SIZE: 10.5pt">return δ<sub>filter</sub>(CartesianRS);</span></div><div align="left"><span style="FONT-SIZE: 10.5pt">}</span></div><div align="left"><span style="FONT-SIZE: 12pt">我们对例</span><span style="FONT-SIZE: 12pt">1.1.3.4.2</span><span style="FONT-SIZE: 12pt">中的</span><span style="FONT-SIZE: 12pt">Ra</span><span style="FONT-SIZE: 12pt">和</span><span style="FONT-SIZE: 12pt">Rb</span><span style="FONT-SIZE: 12pt">求自然连接的</span><span style="FONT-SIZE: 12pt">SQL</span><span style="FONT-SIZE: 12pt">语句如下:</span></div><div align="left"><span style="FONT-SIZE: 12pt">Select * from Ra, Rb where Ra.id=Rb.id</span></div><div align="left"><span style="FONT-SIZE: 12pt">因为Ra和Rb只有一个Common key,所以在笛卡尔积上的过滤条件只有一个。</span></div><div align="left"><strong><span style="FONT-SIZE: 14pt">1.2.1.4.4 半连接运算(Semi join)</span></strong></div><div style="TEXT-INDENT: 27pt" align="left"><span style="FONT-SIZE: 12pt">两个关系</span><span style="FONT-SIZE: 12pt">R</span><span style="FONT-SIZE: 12pt">和</span><span style="FONT-SIZE: 12pt">S</span><span style="FONT-SIZE: 12pt">的半连接运算是在关系</span><span style="FONT-SIZE: 12pt">R</span><span style="FONT-SIZE: 12pt">和</span><span style="FONT-SIZE: 12pt">S</span><span style="FONT-SIZE: 12pt">的自然连接运算的基础之上再作一次投影运算,投影的属性是半连接运算左算子的属性。</span><span style="FONT-SIZE: 12pt">R</span><span style="FONT-SIZE: 12pt">∝S可以形式化地表示为:R∝S = π</span><sub><span style="FONT-SIZE: 12pt">R</span></sub><span style="FONT-SIZE: 12pt">(R∞S)。我们换个角度思考,两个关系得半连接运算实际上使用了两个关系的Common Keys对关系R做了一次选择运算,选择的条件就是R的Common Keys的键值全部等于S的Common Keys的键值。</span></div><div style="TEXT-INDENT: 18pt" align="left"><span style="FONT-SIZE: 12pt">我们再以</span><span style="FONT-SIZE: 12pt">Figure 1.1.3.4.2</span><span style="FONT-SIZE: 12pt">中的</span><span style="FONT-SIZE: 12pt">Ra</span><span style="FONT-SIZE: 12pt">和</span><span style="FONT-SIZE: 12pt">Rb</span><span style="FONT-SIZE: 12pt">为例,</span><span style="FONT-SIZE: 12pt">Ra</span><span style="FONT-SIZE: 12pt">∝</span><span style="FONT-SIZE: 12pt">Rb</span><span style="FONT-SIZE: 12pt">可以表述为:</span></div><div style="TEXT-INDENT: 30.85pt" align="left"><span style="FONT-SIZE: 12pt">SELECT Ra.* FROM Ra INNER JOIN Rb ON Ra.Id = Rb.Id</span></div><div align="left"> </div><div><strong><font size="4">1.2.2 关系代数的运算法则</font></strong></div><div style="TEXT-INDENT: 27pt" align="left"><span style="FONT-SIZE: 12pt">就像数学代数运算中加法、乘法满足交换率、结合率和分配率一样,关系代数也有自己的运算法则。</span></div><div align="left"><strong><span style="FONT-SIZE: 16pt">1.2.2.1结合律</span></strong></div><div style="TEXT-INDENT: 18pt" align="left"><span style="FONT-SIZE: 12pt">对于一个二元运算△,结合率的表示方式为:</span><span style="FONT-SIZE: 12pt">(A</span><span style="FONT-SIZE: 12pt">△</span><span style="FONT-SIZE: 12pt">B)</span><span style="FONT-SIZE: 12pt">△</span><span style="FONT-SIZE: 12pt">C=A</span><span style="FONT-SIZE: 12pt">△</span><span style="FONT-SIZE: 12pt">(B</span><span style="FONT-SIZE: 12pt">△</span><span style="FONT-SIZE: 12pt">C)</span><span style="FONT-SIZE: 12pt">,其中括号表示了运算的优先级。我们知道数学运算的加法和乘法都是满足结合率的,但减法和除法不满足结合率。对于关系代数,联合运算</span><span style="FONT-SIZE: 12pt">Union</span><span style="FONT-SIZE: 12pt">、笛卡尔积</span><span style="FONT-SIZE: 12pt">Cartesian Product</span><span style="FONT-SIZE: 12pt">、自然连接运算</span><span style="FONT-SIZE: 12pt">Natural Join</span><span style="FONT-SIZE: 12pt">等运算都是满足结合率的,我们在此给出联合运算</span><span style="FONT-SIZE: 12pt">Union</span><span style="FONT-SIZE: 12pt">满足结合率的证明,其他证明从略。</span></div><div align="left"><span style="FONT-SIZE: 12pt">Theorem 1.2.2.1.1 </span><span style="FONT-SIZE: 12pt">联合运算满足结合率</span></div><div align="left"><span style="FONT-SIZE: 12pt">证明</span><span style="FONT-SIZE: 12pt">Proof</span><span style="FONT-SIZE: 12pt">:对于具有相同关系模式的三个关系</span><span style="FONT-SIZE: 12pt">Ra</span><span style="FONT-SIZE: 12pt">、</span><span style="FONT-SIZE: 12pt">Rb</span><span style="FONT-SIZE: 12pt">和</span><span style="FONT-SIZE: 12pt">Rc</span><span style="FONT-SIZE: 12pt">,我们有</span></div><div align="left"><span style="FONT-SIZE: 12pt">(Ra</span><span style="FONT-SIZE: 12pt">∪Rb) ∪Rc={t|t是一个元组 and (t</span><span style="FONT-SIZE: 12pt">∈</span><span style="FONT-SIZE: 12pt">Ra </span><span style="FONT-SIZE: 12pt">∨ </span><span style="FONT-SIZE: 12pt">t</span><span style="FONT-SIZE: 12pt">∈</span><span style="FONT-SIZE: 12pt">Rb</span><span style="FONT-SIZE: 12pt">) ∨ t</span><span style="FONT-SIZE: 12pt">∈</span><span style="FONT-SIZE: 12pt">Rc</span><span style="FONT-SIZE: 12pt">}</span></div><div align="left"><span style="FONT-SIZE: 12pt">并根据布尔代数的或运算满足结合率,我们有</span></div><div align="left"><span style="FONT-SIZE: 12pt">(Ra</span><span style="FONT-SIZE: 12pt">∪Rb) ∪Rc={t|t是一个元组 and t</span><span style="FONT-SIZE: 12pt">∈</span><span style="FONT-SIZE: 12pt">Ra </span><span style="FONT-SIZE: 12pt">∨ (</span><span style="FONT-SIZE: 12pt">t</span><span style="FONT-SIZE: 12pt">∈</span><span style="FONT-SIZE: 12pt">Rb</span><span style="FONT-SIZE: 12pt"> ∨ t</span><span style="FONT-SIZE: 12pt">∈</span><span style="FONT-SIZE: 12pt">Rc</span><span style="FONT-SIZE: 12pt">)</span><span style="FONT-SIZE: 12pt">}</span></div><div align="left"><span style="FONT-SIZE: 12pt">=Ra</span><span style="FONT-SIZE: 12pt">∪(Rb∪)Rc</span></div><div align="left"><span style="FONT-SIZE: 12pt">所以我们可以得出结论:关系代数的联合运算满足结合率。</span></div><div style="TEXT-INDENT: 27pt" align="left"><span style="FONT-SIZE: 12pt">同样还有:(Ra∩Rb) ∩Rc=Ra∩(Rb∩Rc)</span></div><div style="TEXT-INDENT: 27pt" align="left"><span style="FONT-SIZE: 12pt"> (Ra×Rb) ×Rc=Ra×(Rb×Rc)</span></div><div style="TEXT-INDENT: 27pt" align="left"><span style="FONT-SIZE: 12pt"> (Ra∞Rb) ∞Rc=Ra∞(Rb∞Rc)</span></div><div align="left"><strong><span style="FONT-SIZE: 16pt">1.2.2.2交换律</span></strong></div><div style="TEXT-INDENT: 27pt" align="left"><span style="FONT-SIZE: 12pt">交换率的表示方式是A△B=B△A,如算术运算中的加法和乘法满足交换率,但减法和除法不满足交换率。对于关系代数,我们有</span></div><div style="TEXT-INDENT: 27pt" align="left"><span style="FONT-SIZE: 12pt">Ra∪Rb=Rb∪Ra Ra∩Rb=Rb∩Ra</span></div><div align="left"><span style="FONT-SIZE: 12pt">□对于两个复合的选择运算,我们可以交换二者的先后执行顺序(不是交换率)</span></div><div style="TEXT-INDENT: 27pt" align="left"><span style="FONT-SIZE: 12pt">δ<sub>F2</sub>(δ<sub>F1</sub>(R)) = δ<sub>F1</sub>(δ<sub>F2</sub>(R)) 证明从略,读者可以利用逻辑与的交换率证明。</span></div><div style="MARGIN-LEFT: 18pt; TEXT-INDENT: -18pt; TEXT-ALIGN: left" align="left"><span style="FONT-SIZE: 12pt">□<span style="FONT: 7pt" times="" new="" roman'"="" style="border-top-style: none; border-right-style: none; border-bottom-style: none; border-left-style: none; border-width: initial; border-color: initial; border-image: initial; "> 如果在一个关系中,各个字段出现的顺序是无关紧要的话,下面的运算也满足交换率(即用映射的观点而不是用元组的观点来理解):

















 4740
4740

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









