







# coding=utf8
import sys
import random
import string
import urllib
import urllib2
import re
#设置多个user_agents,防止百度限制IP
user_agents = ['Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20130406 Firefox/23.0', \
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:18.0) Gecko/20100101 Firefox/18.0', \
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/533+ \
(KHTML, like Gecko) Element Browser 5.0', \
'IBM WebExplorer /v0.94', 'Galaxy/1.0 [en] (Mac OS X 10.5.6; U; en)', \
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0)', \
'Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14', \
'Mozilla/5.0 (iPad; CPU OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) \
Version/6.0 Mobile/10A5355d Safari/8536.25', \
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/28.0.1468.0 Safari/537.36', \
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.0; Trident/5.0; TheWorld)']
def baidu_search(keyword,pn):
p= {'wd': keyword}
url = ("http://www.baidu.com/s?"+urllib.urlencode(p)+"&pn={0}").format(pn)
res=urllib2.urlopen(url)
html=res.read()
return html
def getList(regex,text):
arr = []
res = re.findall(regex, text)
if res:
for r in res:
arr.append(r)
return arr
def getMatch(regex,text):
res = re.findall(regex, text)
if res:
return res[0]
return ""
def clearTag(text):
p = re.compile(u'<[^>]+>')
retval = p.sub("",text)
return retval
def geturl(keyword):
for page in range(2):
pn=page*10+1
html = baidu_search(keyword,pn)
content = unicode(html, 'utf-8','ignore')
arrList = getList(u"<div class=\"result c-container \"[\s\S]*?>([\s\S]*?</a>)", content)
for item in arrList:
regex = u"<h3.*?class=\".*\".*?><a[\s\S]*?href = \"([\s\S]*?)\"[\s\S]*?>([\s\S]*?)</a>"
link = getMatch(regex,item)
url = link[0]
#获取标题
title = clearTag(link[1]).encode('utf8')
print title
try:
domain=urllib2.Request(url)
r=random.randint(0,11)
domain.add_header('User-agent', user_agents[r])
domain.add_header('connection','keep-alive')
response=urllib2.urlopen(domain)
uri=response.geturl()
print uri
except:
continue
if __name__=='__main__':
geturl(sys.argv[1])
用法举例: python xxx.py "关联分析"
效果如图:
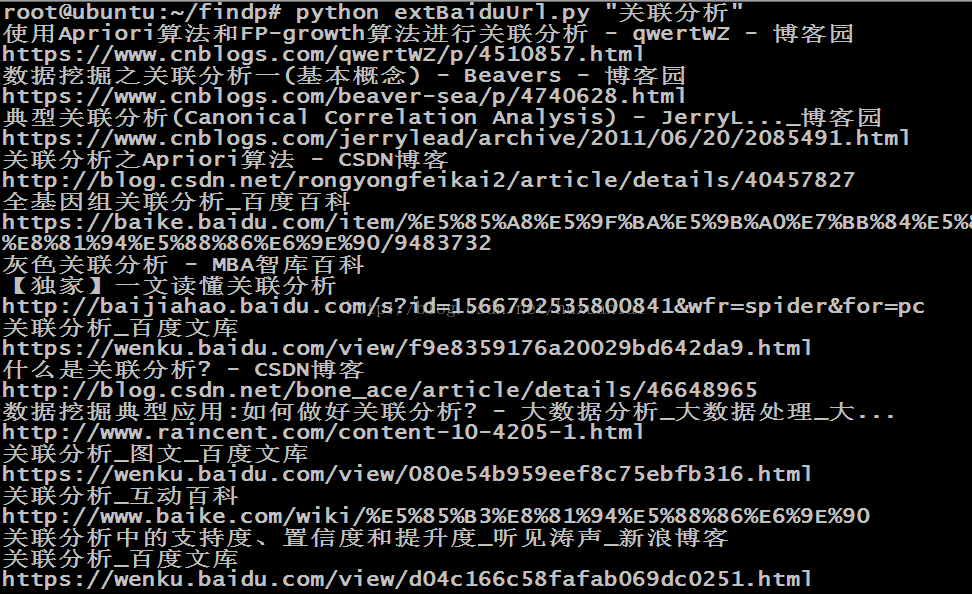
参考:
https://www.2cto.com/kf/201306/223584.html 代码大体没变,我对原代码的抽取标签内容的部分有修改。
表格内容抽取:
https://pypi.org/project/scrapely/
http://item.jd.com/26793464002.html
https://www.jianshu.com/p/136a714d5382















 6708
6708











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









