







备注: 转至 周磊的博客,http://blog.csdn.net/v_JULY_v/article/details/6057286
91.
1.一道著名的毒酒问题
有1000桶酒,其中1桶有毒。而一旦吃了,毒性会在1周后发作。
现在我们用小老鼠做实验,要在1周内找出那桶毒酒,问最少需要多少老鼠。
2.有趣的石头问题
有一堆1万个石头和1万个木头,对于每个石头都有1个木头和它重量一样,
把配对的石头和木头找出来。
92.
1.多人排成一个队列,我们认为从低到高是正确的序列,但是总有部分人不遵守秩序。
如果说,前面的人比后面的人高(两人身高一样认为是合适的),
那么我们就认为这两个人是一对“捣乱分子”,比如说,现在存在一个序列:
176, 178, 180, 170, 171
这些捣乱分子对为
<176, 170>, <176, 171>, <178, 170>, <178, 171>, <180, 170>, <180, 171>,
那么,现在给出一个整型序列,请找出这些捣乱分子对的个数(仅给出捣乱分子对的数目即可,不用具体的对)
要求:
输入:
为一个文件(in),文件的每一行为一个序列。序列全为数字,数字间用”,”分隔。
输出:
为一个文件(out),每行为一个数字,表示捣乱分子的对数。
详细说明自己的解题思路,说明自己实现的一些关键点。
并给出实现的代码 ,并分析时间复杂度。
限制:
输入每行的最大数字个数为100000个,数字最长为6位。程序无内存使用限制。
93.在一个int数组里查找这样的数,它大于等于左侧所有数,小于等于右侧所有数。
直观想法是用两个数组a、b。a[i]、b[i]分别保存从前到i的最大的数和从后到i的最小的数,
一个解答:这需要两次遍历,然后再遍历一次原数组,
将所有data[i]>=a[i-1]&&data[i]<=b[i]的data[i]找出即可。
给出这个解答后,面试官有要求只能用一个辅助数组,且要求少遍历一次。
94、金币概率问题(威盛笔试题)
题目:10个房间里放着随机数量的金币。每个房间只能进入一次,并只能在一个房间中拿金币。
一个人采取如下策略:前四个房间只看不拿。随后的房间只要看到比前四个房间都多的金币数,
就拿。否则就拿最后一个房间的金币。?
编程计算这种策略拿到最多金币的概率。
95、找出数组中唯一的重复元素
1-1000放在含有1001个元素的数组中,只有唯一的一个元素值重复,其它均只出现一次.
每个数组元素只能访问一次,设计一个算法,将它找出来;不用辅助存储空间,
能否设计一个算法实现?
96、一道SPSS笔试题求解
题目:输入四个点的坐标,求证四个点是不是一个矩形
关键点:
1.相邻两边斜率之积等于-1,
2.矩形边与坐标系平行的情况下,斜率无穷大不能用积判断。
3.输入四点可能不按顺序,需要对四点排序。
51、矩阵式螺旋输出
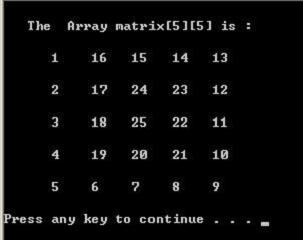
97、求两个或N个数的最大公约数和最小公倍数。
98、最长递增子序列
题目描述:设L=<a1,a2,…,an>是n个不同的实数的序列,L的递增子序列是这样一个子序列
Lin=<aK1,ak2,…,akm>,其中k1<k2<…<km且aK1<ak2<…<akm。
求最大的m值。
99、字符串原地压缩
题目描述:“eeeeeaaaff" 压缩为 "e5a3f2",请编程实现。
100、字符串匹配实现
请以俩种方法,回溯与不回溯算法实现。
101、一个含n个元素的整数数组至少存在一个重复数,
请编程实现,在O(n)时间内找出其中任意一个重复数。
102、求最大重叠区间大小
题目描述:请编写程序,找出下面“输入数据及格式”中所描述的输入数据文件中最大重叠区间的大小。
对一个正整数 n ,如果n在数据文件中某行的两个正整数(假设为A和B)之间,即A<=n<=B或A>=n>=B ,则 n 属于该行;
如果 n 同时属于行i和j ,则i和j有重叠区间;重叠区间的大小是同时属于行i和j的整数个数。
例如,行(10 20)和(12 25)的重叠区间为 [12 20] ,其大小为9,行(20 10)和( 20 30 )的重叠区间大小为 1 。
103、整数的素数和分解问题
歌德巴赫猜想说任何一个不小于6的偶数都可以分解为两个奇素数之和。
对此问题扩展,如果一个整数能够表示成两个或多个素数之和,则得到一个素数和分解式。
对于一个给定的整数,输出所有这种素数和分解式。
注意,对于同构的分解只输出一次(比如5只有一个分解2 + 3,而3 + 2是2 + 3的同构分解式
)。
例如,对于整数8,可以作为如下三种分解:
(1) 8 = 2 + 2 + 2 + 2
(2) 8 = 2 + 3 + 3
(3) 8 = 3 + 5
104、请编程实现全排列算法。
全排列算法有两个比较常见的实现:递归排列和字典序排列。
yysdsyl:
(1)递归实现
从集合中依次选出每一个元素,作为排列的第一个元素,然后对剩余的元素进行全排列,如此递归处理,从而
得到所有元素的全排列。算法实现如下:
- #include <iostream>
- #include <algorithm>
- using namespace std;
- template <typename T>
- void CalcAllPermutation_R(T perm[], int first, int num)
- {
- if (num <= 1) {
- return;
- }
- for (int i = first; i < first + num; ++i) {
- swap(perm[i], perm[first]);
- CalcAllPermutation_R(perm, first + 1, num - 1);
- swap(perm[i], perm[first]);
- }
- }
- int main()
- {
- const int NUM = 12;
- char perm[NUM];
- for (int i = 0; i < NUM; ++i)
- perm[i] = 'a' + i;
- CalcAllPermutation_R(perm, 0, NUM);
- }
程序运行结果(优化):
-bash-3.2$ g++ test.cpp -O3 -o ttt
-bash-3.2$ time ./ttt
real 0m10.556s
user 0m10.551s
sys 0m0.000s
程序运行结果(不优化):
-bash-3.2$ g++ test.cpp -o ttt
-bash-3.2$ time ./ttt
real 0m21.355s
user 0m21.332s
sys 0m0.004s
(2)字典序排列
把升序的排列(当然,也可以实现为降序)作为当前排列开始,然后依次计算当前排列的下一个字典序排列。
对当前排列从后向前扫描,找到一对为升序的相邻元素,记为i和j(i < j)。如果不存在这样一对为升序的相邻元素,则所有排列均已找到,算法结束;否则,重新对当前排列从后向前扫描,找到第一个大于i的元素k,交换i和k,然后对从j开始到结束的子序列反转,则此时得到的新排列就为下一个字典序排列。这种方式实现得到的所有排列是按字典序有序的,这也是C++ STL算法next_permutation的思想。算法实现如下:
- #include <iostream>
- #include <algorithm>
- using namespace std;
- template <typename T>
- void CalcAllPermutation(T perm[], int num)
- {
- if (num < 1)
- return;
- while (true) {
- int i;
- for (i = num - 2; i >= 0; --i) {
- if (perm[i] < perm[i + 1])
- break;
- }
- if (i < 0)
- break; // 已经找到所有排列
- int k;
- for (k = num - 1; k > i; --k) {
- if (perm[k] > perm[i])
- break;
- }
- swap(perm[i], perm[k]);
- reverse(perm + i + 1, perm + num);
- }
- }
- int main()
- {
- const int NUM = 12;
- char perm[NUM];
- for (int i = 0; i < NUM; ++i)
- perm[i] = 'a' + i;
- CalcAllPermutation(perm, NUM);
- }
程序运行结果(优化):
-bash-3.2$ g++ test.cpp -O3 -o ttt
-bash-3.2$ time ./ttt
real 0m3.055s
user 0m3.044s
sys 0m0.001s
程序运行结果(不优化):
-bash-3.2$ g++ test.cpp -o ttt
-bash-3.2$ time ./ttt
real 0m24.367s
user 0m24.321s
sys 0m0.006s
使用std::next_permutation来进行对比测试,代码如下:
- #include <iostream>
- #include <algorithm>
- using namespace std;
- template <typename T>
- size_t CalcAllPermutation(T perm[], int num)
- {
- if (num < 1)
- return 0;
- size_t count = 0;
- while (next_permutation(perm, perm + num)) {
- ++count;
- }
- return count;
- }
- int main()
- {
- const int NUM = 12;
- char perm[NUM];
- for (int i = 0; i < NUM; ++i)
- perm[i] = 'a' + i;
- size_t count = CalcAllPermutation(perm, NUM);
- return count;
- }
程序运行结果(优化):
-bash-3.2$ g++ test.cpp -O3 -o ttt
-bash-3.2$ time ./ttt
real 0m3.606s
user 0m3.601s
sys 0m0.002s
程序运行结果(不优化):
-bash-3.2$ g++ test.cpp -o ttt
-bash-3.2$ time ./ttt
real 0m33.850s
user 0m33.821s
sys 0m0.006s
测试结果汇总一(优化):
(1)递归实现:0m10.556s
(2-1)字典序实现:0m3.055s
(2-2)字典序next_permutation:0m3.606s
测试结果汇总二(不优化):
(1)递归实现:0m21.355s
(2-1)字典序实现:0m24.367s
(2-2)字典序next_permutation:0m33.850s
由测试结果可知,自己实现的字典序比next_permutation稍微快点,原因可能是next_permutation版本有额外的函数调用开销;而归实现版本在优化情况下要慢很多,主要原因可能在于太多的函数调用开销,但在不优化情况下执行比其它二个版本要快,原因可能在于程序结构更简单,执行的语句较少。
比较而言,递归算法结构简单,适用于全部计算出所有的排列(因此排列规模不能太大,计算机资源会成为限制);而字典序排列逐个产生、处理排列,能够适用于大的排列空间,并且它产生的排列的规律性很强。















 9528
9528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









