







大数据之hive文件格式(三)
一、hive文件存储格式分类:
- TEXTFILE(建表时默认格式,导入数据直接到hdfs,不处理)
- SEQUENCEFILE
- RCFFILE
- ORCFILE
其他格式不能直接从本地文件导入数据,需先导入textfile格式的表中,然后再从表中insert导入sequencefile rcffile orcfile表中
1. 列式存储和行式存储
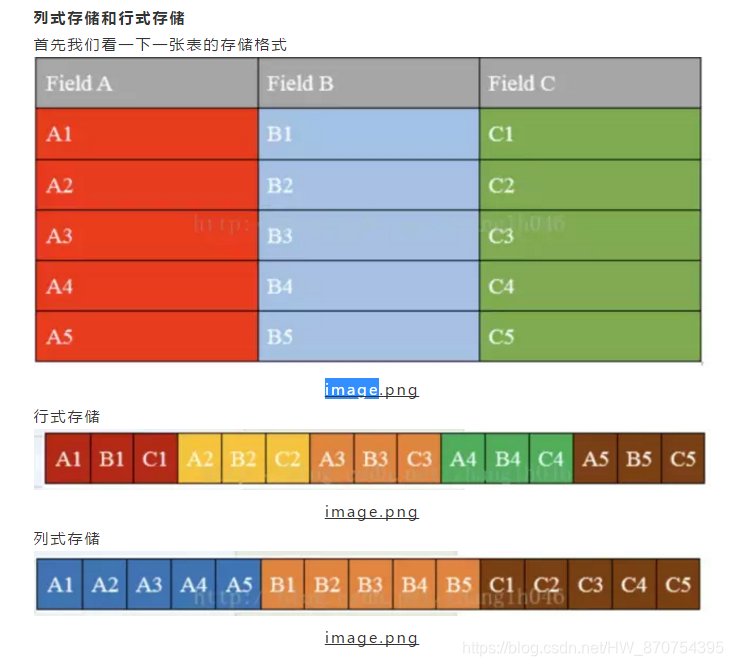
(1)行式存储
优点:
- 相关的数据是保存在一起,比较符合面向对象的思维
- 方便进行insert/update操作
缺点: - 若查询只涉及某几个列,需要整行数据读取,不能跳过不必要的列,数据量大时,影响性能
- 压缩比空低,空间利用率不高
- 不是所有的列都适合作为索引
(2)列式存储
优点:
- 只查询涉及到的列,不会把所有列都查询,即可以跳过不必要的列查询
- 高效的压缩率,不仅节省空间也节省计算内存和cpu
- 任何列都可以所谓索引
缺点: - insert/update不便
- 不适合扫描小量的数据
2. textfile
- 默认格式,数据不做压缩,磁盘开销大,数据解析开销大
- hive不会对数据进行切分,从而无法对数据进行并行操作
3. sequencefile
- 方便、可分割、可压缩的特点
- 支持三种压缩:none、record(压缩率低)、block (建议)
4. rcfile
- 行列存储相结合的存储方式
- 先将数据按行分块,保证同一个record在一个块上;
- 然后块数据列式存储
- 保证同一个record的数据位于同一节点上,因此元祖重构代价较低
- 通过列进行数据压缩,同一列数据类型相同,压缩比较好
- 可跳过不必要的列读取
5. orcfile
- 对rcfile的优化
- rcfile与orcfile比较:
- 每一个任务只输出单个文件,减少namenode的负载
- 支持各种复杂的数据结构(datetime,decimal,以及复杂的struct,List,map)
- 存储了轻量级的索引数据
- 基于数据类型的块模式压缩(比如Integer类型使用RLE(RunLength Encoding)算法,而字符串使用字典编码(DictionaryEncoding))
- 使用单独的RecordReader并行读相同的文件
- 无需扫描标记就能分割文件
- 绑定读写需要的内存
- 元数据存储使用PB,允许添加和删除字段
6. Hive ROW FORMAT
Serde是 Serializer/Deserializer的简写。hive使用Serde进行行对象的序列与反序列化。
你可以创建表时使用用户自定义的Serde或者native Serde,如果 ROW FORMAT没有指定或者指定了 ROW FORMAT DELIMITED就会使用native Serde。
hive已经实现了许多自定义的Serde,之前我们在介绍stored时也涉及到:
- Avro (Hive 0.9.1 and later)
- ORC (Hive 0.11 and later)
- RegEx
- Thrift
- Parquet (Hive 0.13 and later)
- CSV (Hive 0.14 and later)
- JsonSerDe (Hive 0.12 and later)
三、hive写入数据的方式
hive目前不支持 “insert into … values”
1. 从本地文件系统中导入数据到hive表
load data local inpath ‘xxx.txt’ into table xxx;
2. 从hdfs上导入数据到hive表
load data inpath ‘/home/xxx/add.txt’ into table xxx
alter table db.access_log add partition (dt=‘18-09-18’) location ‘hdfs://ns/hive/warehouse/access_log/dt=18-09-18’;
3. 从别的表查询出相应的数据并导入到hive表中
insert overwrite table db.log_v2 partition(dt=‘18-09-26’)
select uid,model,key,value,time from db.log where dt=‘18-09-26’;
4. 在创建表的时候通过从别的表中查询出相应的记录并插入到所创建的表中
create table test4 as select id, name, tel from xxx;














 2789
2789











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









