









1.描述
指标描述:该指标主要用于计算用户平均购买一次商品需要多长时间。因为需要求两次购买行为的时间的差值,所以最少的购买行为为两次。假如用户购买了两次,第一次购买为08-01,第二次购买为08-05,则购买间隔为4天,则平均购买间隔周期为4,即大约4天购买一次。
在本节的指标统计逻辑为上述,下面的代码也是根据此逻辑来编写。
2.数据准备
数据为构造的用户购买行为数据,如果每天有多次购买行为则算一次,本次的数据表为清洗过的数据。
下面为建表语句:
CREATE TABLE test.user_buy_record(
user_id STRING COMMENT '用户id',
buy_time STRING COMMENT '购买时间'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','准备txt文本数据,文件名称为 user_buy_record.txt:
1,2019-07-23
1,2019-07-24
1,2019-07-26
1,2019-07-28
2,2019-07-23
2,2019-07-28
2,2019-08-12
2,2019-08-23通过LOAD命令把txt文本数据加载到hive表中:
load data local inpath '/home/hadoop/data/user_buy_record.txt' into table test.user_buy_record;然后通过select可以查看到数据:

3.执行SQL
第一步需要计算出用户下一次购买行为和当前购买行为之间的时间间隔。
select user_id
-- 下一次的购买行为时间
,lead(buy_time,1,'1970-01-01') over(partition by user_id order by buy_time) as next_buy_time
,buy_time
-- 下一次的购买行为和当前购买行为的时间间隔
,datediff(lead(buy_time,1,'1970-01-01') over(partition by user_id order by buy_time),buy_time) as diff_day
from test.user_buy_record执行上述的SQL得出的结果:

然后我们把最后一次的购买行为删除掉即可得到用户的总的购买行为时间间隔和购买次数(抛出了最后一次的购买行为)。
第二步把上述的结果数据按照用户平均即可得到平均购买时间间隔。
select user_id,avg(diff_day) as avg_buy_period
from (
select user_id
,lead(buy_time,1,'1970-01-01') over(partition by user_id order by buy_time) as next_buy_time
,buy_time
,datediff(lead(buy_time,1,'1970-01-01') over(partition by user_id order by buy_time),buy_time) as diff_day
from test.user_buy_record
) t1
where diff_day>0
group by user_id执行SQL即可得到最终的结果:
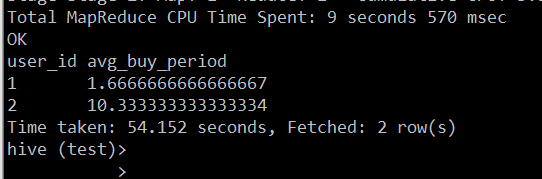
至此用户平均购买间隔周期的指标计算完成,算出了每个用户的平均购买间隔周期。需要注意的是,每个用户在每天的购买行为记录为一条,这个数据需要进行处理,一般用户在一天会有多条购买行为记录。















 7477
7477











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









