






MapReduce分组求TOP
原始数据:
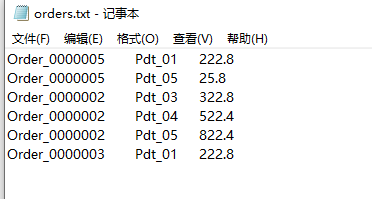
第一列是订单编号,称为orderId,第二列是产品编号,称为productId,第三列是价格,称为price。
目的:对同一orderId的数据当中求取价格最高的2条数据。
实现原理
自定义一个实现WritableComparable接口的JavaBean(需要实现数据转化和排序)来接收数据,在Map阶段完成原始数据向JavaBean类型数据的转化,然后自定义partition按orderId将数据分区,然后自定义一个继承WritableComparator的类来根据orderId对数据分组,而不是按整个JavaBean对象来分组,在Reduce阶段遍历每个数据组中的数据,在遍历到第二条时break。**
代码实现
1、自定义JavaBean
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class OrderBean implements WritableComparable<OrderBean>
{
private String orderId;
private String productId;
private Double price;
public OrderBean()
{
}
public OrderBean(String orderId, String productId, Double price)
{
this.orderId = orderId;
this.productId = productId;
this.price = price;
}
@Override
public int compareTo(OrderBean o)
{
int reslut=0;
//在orderId相同的情况下才进行price的比较
if (this.getOrderId().equals(o.getOrderId()))
reslut=-(this.price.compareTo(o.price)); //降序
return reslut;
}
@Override
public void write(DataOutput dataOutput) throws IOException
{
dataOutput.writeUTF(orderId);
dataOutput.writeUTF(productId);
dataOutput.writeDouble(price);
}
@Override
public void readFields(DataInput dataInput) throws IOException
{
this.orderId=dataInput.readUTF();
this.productId=dataInput.readUTF();
this.price=dataInput.readDouble();
}
public String getOrderId()
{
return orderId;
}
public void setOrderId(String orderId)
{
this.orderId = orderId;
}
public String getProductId()
{
return productId;
}
public void setProductId(String productId)
{
this.productId = productId;
}
public Double getPrice()
{
return price;
}
public void setPrice(Double price)
{
this.price = price;
}
@Override
public String toString()
{
return orderId+"\t"+productId+"\t"+price;
}
}
2、自定义Mapper
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class GroupMapper extends Mapper<LongWritable, Text,OrderBean, DoubleWritable>
{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
{
String[] sArr=value.toString().split("\t");
OrderBean order=new OrderBean(sArr[0],sArr[1],Double.valueOf(sArr[2]));
Double price=Double.valueOf(sArr[2]);
context.write(order,new DoubleWritable(price));
}
}
3、自定义Partitoner
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.mapreduce.Partitioner;
public class GroupPartitioner extends Partitioner<OrderBean, DoubleWritable>
{
@Override
public int getPartition(OrderBean orderBean, DoubleWritable doubleWritable, int i)
{
return (orderBean.getOrderId().hashCode() & Integer.MAX_VALUE) % i;
}
}
4、自定义WritableComparator
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class MyGroupComparetor extends WritableComparator
{
//通过重写构造方法,使GroupComparetor反射出来的类是OrderBean
public MyGroupComparetor()
{
super(OrderBean.class,true);
}
//重写compare方法可以实现数据按某个字段分组
@Override
public int compare(WritableComparable a, WritableComparable b)
{
OrderBean first= (OrderBean) a;
OrderBean second= (OrderBean) b;
return first.getOrderId().compareTo(second.getOrderId());
}
}
5、自定义Reducer
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class GroupReducer extends Reducer<OrderBean, DoubleWritable,OrderBean,NullWritable>
{
@Override
protected void reduce(OrderBean key, Iterable<DoubleWritable> values, Context context) throws IOException, InterruptedException
{
int i=0;
for (DoubleWritable v : values)
{
context.write(key,NullWritable.get());
i++;
if (i>=2)
break;
}
}
}
6、主类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class GroupRun extends Configured implements Tool
{
@Override
public int run(String[] strings) throws Exception
{
Job job= Job.getInstance(super.getConf(),"group");
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,
new Path("E:\\自定义groupingComparator\\input"));
job.setMapperClass(GroupMapper.class);
job.setMapOutputKeyClass(OrderBean.class);
job.setMapOutputValueClass(DoubleWritable.class);
job.setPartitionerClass(GroupPartitioner.class);
job.setGroupingComparatorClass(MyGroupComparetor.class);
/*
由于要将所有结果输出到一个文件中,所以虽然自定义了Partitioner,
但是不设置NumReduceTasks,
这里作Partition这一步操作,
只是要让数据在分组前先按orderId进行一次分区
*/
job.setReducerClass(GroupReducer.class);
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,
new Path("E:\\自定义groupingComparator\\topN_output"));
return job.waitForCompletion(true)?0:1;
}
public static void main(String[] args) throws Exception
{
System.exit(ToolRunner.run(new Configuration(),new GroupRun(),args));
}
}
MapReduce参数调优
资源相关参数
mapred-site.xml中参数:
以下参数是在用户自己的mr应用程序中配置就可以生效
(1) mapreduce.map.memory.mb: 一个Map Task可使用的资源上限(单位:MB),默认为1024。如果Map Task实际使用的资源量超过该值,则会被强制杀死。
(2) mapreduce.reduce.memory.mb: 一个Reduce Task可使用的资源上限(单位:MB),默认为1024。如果Reduce Task实际使用的资源量超过该值,则会被强制杀死。
(3) mapred.child.java.opts 配置每个map或者reduce使用的内存的大小,默认是200M
(4) mapreduce.map.cpu.vcores: 每个Map task可使用的最多cpu core数目, 默认值: 1
(5) mapreduce.reduce.cpu.vcores: 每个Reduce task可使用的最多cpu core数目, 默认值: 1
mapreduce.map.cpu和mapreduce.reduce.cpu的设置不是设置实际CPU的核数,而是设置虚拟CPU的核数,这与CPU的性能有关。
shuffle性能优化的关键参数,应在yarn启动之前就配置好
(6)mapreduce.task.io.sort.mb 100 //shuffle的环形缓冲区大小,默认100m
(7)mapreduce.map.sort.spill.percent 0.8 //环形缓冲区溢出的阈值,默认80%
yarn-site.xml中的参数
以下配置都在配置文件当中配置,应该在yarn启动之前就配置在服务器的配置文件中才能生效
(1) yarn.scheduler.minimum-allocation-mb 1024 给应用程序container分配的最小内存
(2) yarn.scheduler.maximum-allocation-mb 8192 给应用程序container分配的最大内存
(3) yarn.scheduler.minimum-allocation-vcores 1 container最小的虚拟内核的个数
(4)yarn.scheduler.maximum-allocation-vcores 32 container最大的虚拟内核的个数
(5)yarn.nodemanager.resource.memory-mb 8192 每个nodemanager给多少内存
容错相关参数
(1) mapreduce.map.maxattempts: 每个Map Task最大重试次数,一旦重试参数超过该值,则认为Map Task运行失败,默认值:4。
(2) mapreduce.reduce.maxattempts: 每个Reduce Task最大重试次数,一旦重试参数超过该值,则认为Map Task运行失败,默认值:4。
(3) mapreduce.job.maxtaskfailures.per.tracker: 当失败的Map Task失败比例超过该值为,整个作业则失败,默认值为0. 如果你的应用程序允许丢弃部分输入数据,则该该值设为一个大于0的值,比如5,表示如果有低于5%的Map Task失败(如果一个Map Task重试次数超过mapreduce.map.maxattempts,则认为这个Map Task失败,其对应的输入数据将不会产生任何结果),整个作业仍认为成功。
(5) mapreduce.task.timeout: Task超时时间,默认值为600000毫秒,经常需要设置的一个参数,该参数表达的意思为:如果一个task在一定时间内没有任何进入,即不会读取新的数据,也没有输出数据,则认为该task处于block状态,可能是卡住了,也许永远会卡主,为了防止因为用户程序永远block住不退出,则强制设置了一个该超时时间(单位毫秒)。如果你的程序对每条输入数据的处理时间过长(比如会访问数据库,通过网络拉取数据等),建议将该参数调大,该参数过小常出现的错误提示是“AttemptID:attempt_14267829456721_123456_m_000224_0 Timed out after 300 secsContainer killed by the ApplicationMaster.”。
本地运行mapreduce 作业
设置以下几个参数: file:///
mapreduce.framework.name=local
mapreduce.jobtracker.address=local
fs.defaultFS=local
在JavaAPI中运行本地MapReduce则是需要把输入和输出路径改为本地路径即可。
效率和稳定性相关参数
(1) mapreduce.map.speculative: 是否为Map Task打开推测执行机制,默认为true,如果为true,如果Map执行时间比较长,那么集群就会推测这个Map已经卡住了,会重新启动同样的Map进行并行的执行,哪个先执行完了,就采取哪个的结果来作为最终结果,一般直接关闭推测执行
(2) mapreduce.reduce.speculative: 是否为Reduce Task打开推测执行机制,默认为true,如果reduce执行时间比较长,那么集群就会推测这个reduce已经卡住了,会重新启动同样的reduce进行并行的执行,哪个先执行完了,就采取哪个的结果来作为最终结果,一般直接关闭推测执行
(3) mapreduce.input.fileinputformat.split.minsize: FileInputFormat做切片时的最小切片大小,默认为0
Yarn的架构与调优
yarn的介绍
yarn是hadoop集群当中的资源管理系统模块,从hadoop2.x开始引入yarn来进行管理集群当中的资源(主要是服务器的各种硬件资源,包括CPU,内存)以及运行在yarn上面的各种任务。
总结一句话就是说:yarn主要就是为了调度资源,管理任务等
其调度分为两个层级来说:
一级调度管理:
计算资源管理(CPU,内存,网络IO,磁盘)
App生命周期管理 (每一个应用执行的情况,都需要汇报给ResourceManager)
二级调度管理:
任务内部的计算模型管理 (AppMaster的任务精细化管理)
多样化的计算模型
yarn当中的各个主要组件的介绍
ResourceManager:yarn集群的主节点,主要用于接收客户端提交的任务,并对资源进行分配
NodeManager:yarn集群的从节点,主要用于任务的计算
ApplicationMaster:当有新的任务提交到ResourceManager的时候,ResourceManager会在某个从节点nodeManager上面启动一个ApplicationMaster进程,负责这个任务执行的资源的分配,任务的生命周期的监控等
Container:资源的分配单位,ApplicationMaster启动之后,与ResourceManager进行通信,向ResourceManager提出资源申请的请求,然后ResourceManager将资源分配给ApplicationMaster,这些资源的表示,就是一个个的container
JobHistoryServer:这是yarn提供的一个查看已经完成的任务的历史日志记录的服务,我们可以启动jobHistoryServer来观察已经完成的任务的所有详细日志信息
TimeLineServer:hadoop2.4.0以后出现的新特性,主要是为了监控所有运行在yarn平台上面的所有任务(例如MR,Storm,Spark,HBase等等)
yarn当中各个主要组件的作用
resourceManager主要作用:
处理客户端请求
启动/监控ApplicationMaster
监控NodeManager
资源分配与调度
NodeManager主要作用:
单个节点上的资源管理和任务管理
接收并处理来自resourceManager的命令
接收并处理来自ApplicationMaster的命令
管理抽象容器container
定时向RM汇报本节点资源使用情况和各个container的运行状态
ApplicationMaster主要作用:
数据切分
为应用程序申请资源
任务监控与容错
负责协调来自ResourceManager的资源,开通NodeManager监视容的执行和资源使用(CPU,内存等的资源分配)
Container主要作用:
对任务运行环境的抽象
任务运行资源(节点,内存,cpu)
任务启动命令
任务运行环境
yarn的架构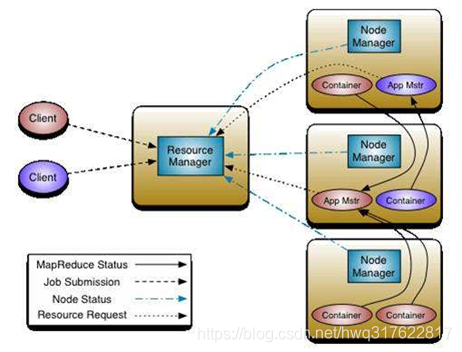
yarn当中的调度器
yarn我们都知道主要是用于做资源调度,任务分配等功能的,那么在hadoop当中,究竟使用什么算法来进行任务调度就需要我们关注了,hadoop支持好几种任务的调度方式,不同的场景需要使用不同的任务调度器。
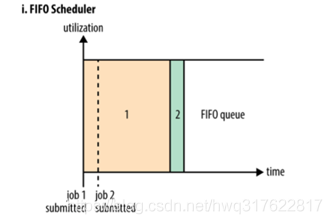
第一种调度器:FIFO Scheduler (队列调度器)
把应用按提交的顺序排成一个队列,这是一个先进先出队列,在进行资源分配的时候,先给队列中最头上的应用进行分配资源,待最头上的应用需求满足后再给下一个分配,以此类推。
FIFO Scheduler是最简单也是最容易理解的调度器,也不需要任何配置,但它并不适用于共享集群。大的应用可能会占用所有集群资源,这就导致其它应用被阻塞。在共享集群中,更适合采用Capacity Scheduler或Fair Scheduler,这两个调度器都允许大任务和小任务在提交的同时获得一定的系统资源。
第二种调度器:capacity scheduler(容量调度器,apache版本默认使用的调度器)
Capacity 调度器允许多个组织共享整个集群,每个组织可以获得集群的一部分计算能力。通过为每个组织分配专门的队列,然后再为每个队列分配一定的集群资源,这样整个集群就可以通过设置多个队列的方式给多个组织提供服务了。除此之外,队列内部又可以垂直划分,这样一个组织内部的多个成员就可以共享这个队列资源了,在一个队列内部,资源的调度是采用的是先进先出(FIFO)策略。

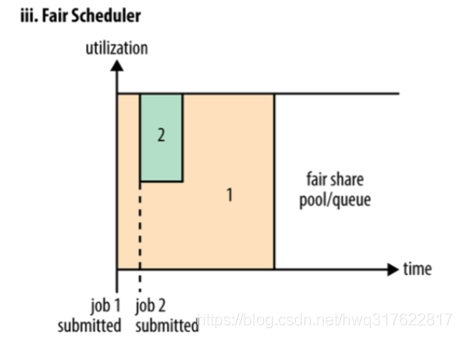
第三种调度器:Fair Scheduler(公平调度器,CDH版本的hadoop默认使用的调度器)
Fair调度器的设计目标是为所有的应用分配公平的资源(对公平的定义可以通过参数来设置)。公平调度在也可以在多个队列间工作。举个例子,假设有两个用户A和B,他们分别拥有一个队列。当A启动一个job而B没有任务时,A会获得全部集群资源;当B启动一个job后,A的job会继续运行,不过一会儿之后两个任务会各自获得一半的集群资源。如果此时B再启动第二个job并且其它job还在运行,则它将会和B的第一个job共享B这个队列的资源,也就是B的两个job会用于四分之一的集群资源,而A的job仍然用于集群一半的资源,结果就是资源最终在两个用户之间平等的共享
关于yarn常用参数设置
| 参数作用 | 参数 | 默认值 | 备注 |
|---|---|---|---|
| container分配最小内存 | yarn.scheduler.minimum-allocation-mb | 1024 | |
| container分配最大内存 | yarn.scheduler.maximum-allocation-mb | 8192 | |
| 每个container的最小虚拟内核个数 | yarn.scheduler.minimum-allocation-vcores | 1 | |
| 每个container的最大虚拟内核个数 | yarn.scheduler.maximum-allocation-vcores | 32 | |
| nodeManager可以分配的内存大小 | yarn.nodemanager.resource.memory-mb | 8192 | |
| 定义每台机器的内存使用大小 | yarn.nodemanager.resource.memory-mb | 8192 | 这与机器实际的内存大小几乎无关,定义多少,集群的总内存就是定义的值乘以机器数 |
| 定义每台机器的虚拟内核使用大小 | yarn.nodemanager.resource.cpu-vcores | 8 | 这与机器实际的CPU核数几乎无关,定义多少,集群的CPU总核数就是定义的值乘以机器数 |
| 定义交换区空间可以使用的大小 | yarn.nodemanager.vmem-pmem-ratio | 2.1 | 交换区空间就是讲一块硬盘拿出来做内存使用,这里指定的交换区的大小是nodemanager的内存的2.1倍 |















 694
694











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









