







Boyer-Moore在字符匹配中算是用得比较广泛的一种算法了,其在最坏情况下其时间复杂度是线性的在平均情况下还要低于线性,这也是它的应用比Knuth-Morris-Pratt算法应用更广的地方。由问题开始逐步探寻Boyer-Moore算法。
一开始我们将比较前缀和后缀的不同之处并列出两种算法之后再讨论两种算法的改进算法最后介绍BM(Boyer-Moore)算法。
一.字符串两种朴素算法。
前缀匹配,模式串P从右向左匹配,模式串从左向右移动的匹配过程,后缀匹配,模式串从左向右匹配,模式串从左向右移动的匹配过程,经典的匹配算法是直接暴力匹配的过程即:一旦一次匹配不成功,立即移动一步进行下次匹配。下面是前缀匹配和后缀匹配的伪代码。
前缀匹配:
T[0..m-1];
P[0..n-1];
PREFIX-MATCHING(T, P)
n=strlen(T);
m=strlen(P);
i=0;
for j=0 to m-n
while P[i]=T[i+j]
do i=i+1;
if i>=m
match;
i=0;
可以看出这两个算法其时间复杂度都是O(m*n),由串T和匹配串的长度来决定的,匹配串和模式串的字符比较多是时间复杂度比较大。因此必须采用时间度比较小的算法,其中有两种基于上面两个算法的改进,具有代表性的是KMP算法和BM算法。T[0..m-1]; P[0..n-1]; SUFFIX-MATCHING(T, P) n=strlen(T); m=strlen(P); i=m-1; for j=0 to m-n while P[i]==T[i+j] do i=i-1; if i<0 match; i=m-1;
二,KMP算法
先做如下定义:

之所以BM算法和KMP算法更有效率在与KMP算法与BM算法的信息的获取方式和获取信息量不同。如下图所示是KMP的前缀匹配的某一状态,P[0..n-1]和T[0..m-1]在此时在T[i+j]和P[i]处不能匹配,于是KMP算法根据以获取的信息做了以下工作。
信息:1,T[j..j+i-1]==P[0..i-1]。
2,T[i+j]!=P[i]。
工作:1,在P中寻找最大前缀P[0..i'],使得P[0..i'-1]为MSuf(P[0..i-1]
2,并且在P[i']!=P[i],否则利用现有的已匹配的字串P[0..i']重复进行第1步工作。
其中信息1决定第1步的工作,信息2决定中第2步的工作。如图1所示i=5,j=3,T[8]!=P[5]则在P中有最大前缀P[0..1]==MSuf(P[0..4]由于P[3]!=P[5]从而满足要求进行移动,有关于此算法的后面的博客将会说到。

图1,KMP匹配图
三,BM匹配算法
1,坏字符和好后缀
BM匹配算法是对暴力后缀匹配算法的改进,主要是基于坏字符和好后缀两条规则来进行先来区分什么是坏字符和什么是好后缀如下图2.

图2 BM匹配1
坏字符:字串P从右到左匹配,从左到右移动,如上图所示字串T中的字符‘e’与字串P中的字符‘g’不匹配则字符‘e'称为“坏字符”,即在字串T中从右到左第一个与字串P不匹配的字符。
好后缀:如上图中的“aca”在T和P中对应的位置相等即:P[m-i..m-1]==T[m-i+j..m-1+j] 中的Pm-i..m-1]即为“好后缀”。
2,坏字符规则
i,如果坏字符没有在P中出现,则整个匹配串跳过该坏字符。如图

图3
如图所示:模式串滑过过的距离d=m-i。
ii,如果在模式串中出现坏字符这时移动的情况的讨论比较复杂了,其几种情况的如下图:

图4
已知在上图中T与P1匹配时在P1[r-1]处与T模式串不匹配。此时,在P串中三个位置出现坏字符‘g'那么这三个位置与T串对齐时都有可能匹配,那么改选那个位置作为下次的匹配位置呢?下面分别就这三种选择给出三种解释,并且都是相对P1进行滑动。
先作如下定义:
如上图T[r+j-1]与P1[r-1]处不匹配并称此处的坏字符为 char 如上图的’g',假设在在P1处中有num_bad个坏字符,在上图r-1处的左边有num_badl个坏字符标号分别为badl[0..num_badl-1],在r-1处的右边有num_badr个坏字符标号为badr[0..num_badr-1],其中badl[num_badl-1]为在右边离char最近的的匹配字符,选择的位置为posbad
分为三个情况讨论:
A,0=<posbadl<num_badl-1,此时我们选择此坏字符所代表的位置posbadi,于是我们将char与posbadi对齐此时我们漏掉了一种可能性即:离char最近的字符badl[num_badl-1],并且由于再次选择的位置,其字符串最右端与T的匹配具有不确定性,而且漏掉的这种可能性可能是一种完全匹配的状态即:P与T在此时match了,例如上图中的P2,它选择最左端的字符与char对齐,漏掉了P3中这种对齐的状况,并且在P2中最右端与T所对的字符具有不确定性,可能会跳到P3状态,但仅仅是“可能”。因此这种选择不可取。
B,posbadl==num_badl-1此时为在左边离char最近的位置了,由于我们每次都是选都是离char最近的字符,因此可以确保每次移动都不会遗漏可能匹配的情况,很显然这种选取是最优的,因为它的每次移动都是选取最近一个可能匹配的状态并逐渐遍历它的。
C,0=<posbadr<=num_badr-1则此时与char对齐的则在char的右边了,此时模式串P向后面移动移动距离为负。但是从后面我们可以看出偏移距离为负这种情况不可能发生,但是如果只看坏字符规则,其向后面移动可能会造成字符串陷入死循环的状态。如图P1和P4,按照情况C的规则,P1先转到P4状态,然后P4转到P1状态,如此将陷入死循环。
基于对这三种情况的讨论衍生出三种坏字符规则:
a,在模式串P中寻找最左边的那个与char对应的字符,并且将char与此字符对齐。它处于上述A,B,C三种情况的任何一种,但是当num_badl不止一个字符时也就是处于A这种情况,此时将选择的是badl[0],因此这种规则并不符合需求。
b,就是对应的情况B,选择离char左边最近的字符,它对每个可能发生的状态的遍历是完备的。
c,在模式串P中寻找最左边的那个与char对应的字符,并且将char与此字符对齐,并且处于B或C情况,但是它是完备的,并且我们可以对C情况加以抑制,即:一旦出现C情况,便立即使此规则的影响对字符串的移动无效。
上面的三种规则中只有b,c两个规则符合完备性,现在对着两种规则进行可行性分析。
对应于b规则:
字母表Alph[alen]:可能被用来做为字符串的字母。
BUILD_ALPHABET_a(P,Plen, Alph,Alen)
build a table :SkipBad[Alen][Plen]
for i=0 to Alen-1
for j=0 to Plen
SkipBad[i][j]=-1; //-1表示在char右边不存在坏字符
for i=0 to Plen
SkipBad[P[i]][i]=i;
for i=0 to Plen
j=i+1;
while SkipBad[P[i]][j]==-1 do
SkipBad[P[i]][j]=i;
j=j+1; //列出右边出现的离char最近的坏字符
对应与c规则:
必须计算出每个在Alph[alen]在模式串P中出现在最右边的位置
上面的代码直接提供了每个在Alph的字符在P中最右边的位置,其实际时间复杂度O(Plen),如果对其出现在C的情况加以抑制,c还是可以采用的。BUILD_ALPHABET_b(P,Plen, Alph,Alen) build a table :SkipBad[Alen] //for the each alphabet in the Alph for i=0 to Alen-1 do SkipBad[i]=-1; //为-1则表示此字符在模式串P中未出现 for j=Plen-1 to 0 do if SkipBad[P[j]]==-1 do SkipBad[P[j]]=j; //对于每个在P中的字符都说明其在出现在P中最右边的位置,未出现则赋值为-1
这两段代码描述了Alph中字符出现在P中最右边的位置,基于对时间和空间复杂度和可操作性的综合考虑,最后我们选择规则c,并且对于这一规则和和上面建的SkipBad表:我们有一下跳转公式:

最后我们可以根据当前的 i,j来计算跳转的长度。
3,好后缀规则
根据后缀在P中的出现的情况又分为三种情况:
i,如果MSuf(P[m-i..m-1])和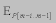

图5
如上图所示在P中除了最右端再也没有“acag"这样的字段或在P中找不MSuf("acag")因此P移动到P1位置。此时d=m。
ii,如果MSuf(P[m-i..m-1])为空,而

图6
如图寻找最大前缀长度为k,那么移动的距离为d=m-k。
iii,如果

图7
如图与其匹配的最近的字段的位置为k所以d=m-k。如果将P1移到最左边的并与最左边的“ag”对齐,那么可能会错失移到中间”ag“可能会发生匹配这一情况。
为了求上面的K值我们求出P中每个位置与后缀匹配的最大长度。我们将从右向左遍历P中每个字符。其代码如下:
下面利用上面创建的MaxSuffix表来创建SkipGood表:BUILD_MAX_MATCH(P,Plen) build a table :MaxMatch[Plen] //this table discribe the each's max matched P suffix build a table: MaxSuffix[Plen] for i=0 to Plen-1 do MaxSuffix[i]=-1; //initing the table MaxMatch[i]=-1; MaxMatch[Plen-1]=Plen; k=1; for i=plen-2 to 0 //Part 1 j=0; while j!=i+1 and P[i-j]==P[m-j-1] do j++;if j==i+1 doMaxMatch[i]=j; //Part 2
MaxSuffix[k++]=j;
MaxSuffix[0]=k-1;
下面来分析其时间复杂度 :BUILD_SKIPGOOD(P,Plen,MaxMatch, MaxSuffix) build a table :SkipGood[Plen] //Part 1 for i=0 to Plen-1 SkipGood[i]=m;for i=Plen-1 to 0//Part 1
if SkipGood[i]==m do
SkipGood[MaxMatch[i]]=m-i-1;Lm=Plen-2;//Part 2
for i=0 to MaxSuffix[0]-1
Ln=MaxSuffix[i+1]+1;
for j=Lm to Ln
if SkipGood[j]==m do
SkipGood[j]=Ln;
Lm=Ln-2;
我们在上面的代码中标注了颜色和标号分别作出说明
BUILD_MAX_MATCH(P,Plen) :
Part 1:将P中在i处与数组后面匹配的长度 j存在MaxSuffix数组中如下图如果P[i-j]与P[m-j-1]匹配则j加1否则MaxSuffix[i]=j;如图8
时间复杂度:其最好的情况是每一个字符与后面的字符匹配为O(m) ,最坏的情况是O(m^2)为了求平均情况下的时间复杂度将问题转化为:
数组长度为m,其中有g个字符(每个字符出现的概率相等)求Part 1过程中时间的平均复杂度?
Part 2:如果在Part 1中的j==i那么就有P[0..i]是P后缀,那么在Part 1过程中一共有多少个后缀呢?这就是Part 2等价的时间复杂度可见其最坏情况下是O(m),即:所有字符相同的时候。
对比Part 1和Part 2,Part 1的时间复杂度大于Part 2因此,BUILD_MAX_MATCH的主要复杂度主要是Part 1了。
BUILD_SKIPGOOD(P,Plen,MaxMatch, MaxSuffix):Part 1: O(m)主要是初始化的工作。
Part 2: 主要是利用MaxMatch的中匹配的数据来完成 iii 中的工作。寻找左边离匹配段最近的一段字符。
Part 3: 完成 ii 的工作,获取当前的小于匹配段的最大前缀。
Part 2和Part 3总共的时间复杂度是O(m)。

图8
可见预处理的的平均时间复杂度O(m)。
4,BM算法
主要是利用上面的两个表来进行动态跳转。
BM(SkipGood,SkipBad)
j=0;
while j<=n-m do
i=0;
while T[j+m-i-1]==P[m-i-1] do
i++;
if i==m do match
else
j+=max(SkipGood(i),m-SkipBad[T[m+j-i-1])-i-1])-i-1);
上述程序其时间复杂度最好情况为O(n/m)最坏情况下为O(m)。
参考:
2,一篇论文非常不错! http://www.cs.utexas.edu/~moore/publications/fstrpos.pdf
3,这篇也不错,不过整篇都是文字:http://www.ruanyifeng.com/blog/2013/05/boyer-moore_string_search_algorithm.html
4,不错,不过就是不是很详细:http://wenku.baidu.com/view/20c7eec34028915f804dc2fa.html
5,复杂度总结的不错:http://www.cnblogs.com/a180285/archive/2011/12/15/BM_algorithm.html















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









