






【大数据工具选型】ETL&同步&调度工具比较-Kettle、Streamset,DataX、Sqoop、Canel,DolphinSchedule、Azkaban、Oozie、Airflow、Xxl Job
〇、概述
1、常用资料
dolphinscheduler用户手册:https://dolphinscheduler.apache.org/zh-cn/docs/latest/user_doc/system-manual.html
airflow官方文档:airflow.apache.org
2、理解
数据从多个异构数据源加载到数据库或其他目标地址
3、选型
(1)ETL
Kettle
Streamset
(2)同步
DataX
Sqoop
Canel
(3)调度
DolphinSchedule
Azkaban
Oozie on Hue
Airflow
一、ETL
(一)Kettle
1、简介
Spoon图形化界面操作
支持的数据源丰富,但支持的数据源不主流
kettle是做数据清洗,转换工作的工具
2、组成
(1)转换Transformation:多个数据源输入
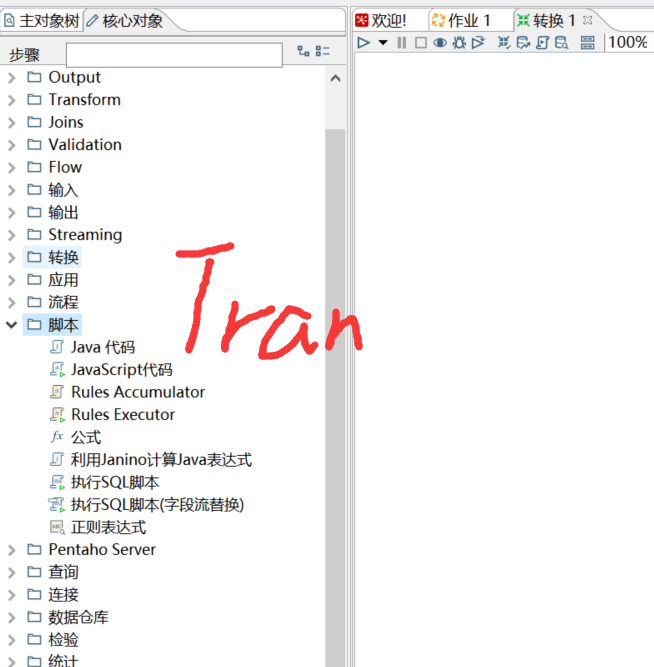
各种各样的输入(HDFS、parquet、HBASE输入)、转换和输出(如HDFS、parquet、HBASE、表输出或数据同步功能)【dolphinschedule需要集成datax插件做数据同步】
(2)作业Job:循环成圈,可以包含作业或转换
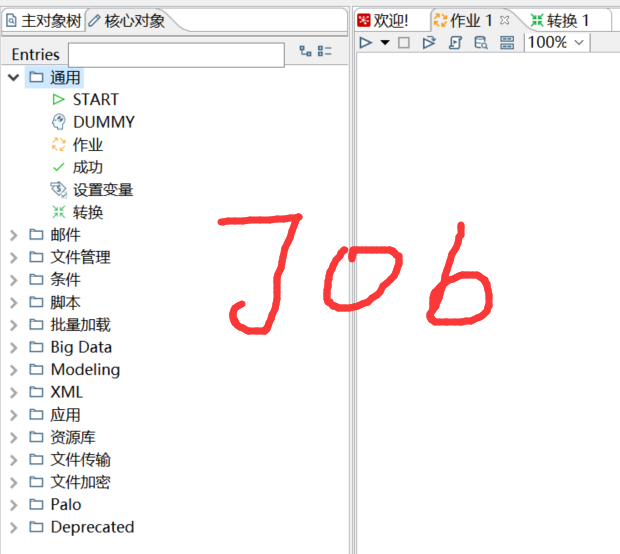
内部可以包含:开始、设置变量、成功和转换
可以定时调度&发送邮件
3、kettle调用
(1)API方式调用kettle
https://blog.csdn.net/qq_32577829/article/details/123867367
http://www.kettle.net.cn/2230.html
(2)集成平台
构建定时调度任务
4、优化
spoon脚本
调大JVM内存大小
线程堆栈大小
if "%PENTAHO_DI_JAVA_OPTIONS%"=="" set PENTAHO_DI_JAVA_OPTIONS="-Xms2048m" "-Xmx2048m" "-XX:MaxPermSize=256m"增大缓存
使用数据库连接池
提高批处理的commit size
避免使用update , delete操作,尤其是update,如果可以把update变成先delete, 后insert;
5、解决阻塞
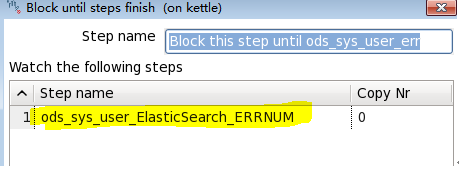
(1)流数据执行阻塞
添加阻塞的组件

可以设置阻塞到哪一步才能执行
(2)资源库死锁问题
dbeaver连kettle库,打开锁古管理器,关掉被锁住的进程
出现原因:同一时间更新同一表会造成线程占用
6、其他版本
spoon:客户端,免安装
kettle online:不好下载,收费
webspoon:docker安装,有点卡顿,和spoon界面一样
kettle-scheduler-boot:基于kettle8.3的API,https://www.35youth.cn/886.html
(博主整理了mysql手册https://www.35youth.cn/mysql.html)
(二)Streamset
大数据实时采集ETL工具,可以实现不写一行代码完成数据的采集和流转。通过拖拽式的可视化界面,实现数据管道(Pipelines)的设计和定时任务调度。
数据源支持MySQL、Oracle等结构化和半/非结构化,目标源支持HDFS、Hive、Hbase、Kudu、Solr、Elasticserach等
创建一个Pipelines管道需要配置数据源(Origins)、操作(Processors)、目的地(Destinations)三部分
二、同步
(一)DataX
1、概述
(1)概述
异构数据源离线同步工具,将网状同步链路转为星型同步链路,通过接入不同的数据源,让datax作为中间载体
【想起kettle的转换图标】
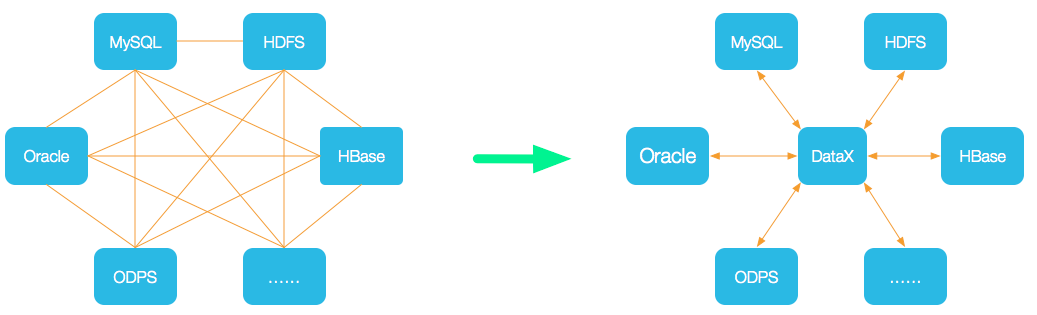
(2)组成
Reader采集模块、Writer写入模块、Framework数据传输通道

(3)原理
job管理单个作业,task对job切分(作业最小单元),每个task负责一部分同步工作;schedule将task归为5个一组,通过taskgroup对task进行启动
(4)实现方式
通过脚本调用Python2,再解析JSON文件(如:python datax.py /opt/module/datax/job/job.json)
对数据库压力小,全量速度快,适合做数据同步工作
不支持增量同步
2、案例
查看官方模板:python /opt/module/datax/bin/datax.py -r mysqlreader -w hdfswriter
使用:[atguigu@hadoop102 datax]$ bin/datax.py job/hdfs2mysql.json


(1)从stream流读取数据并打印到控制台
[atguigu@hadoop102 job]$ /opt/module/datax/bin/datax.py /opt/module/datax/job/stream2stream.json
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
],(2)读取MySQL中的数据存放到HDFS
[atguigu@hadoop102 datax]$ bin/datax.py job/mysql2hdfs.json
(3)读取HDFS数据写入MySQL
[atguigu@hadoop102 datax]$ bin/datax.py job/hdfs2mysql.json
(4)从Oracle中读取数据存到MySQL
/opt/module/datax/bin/datax.py /opt/module/datax/job/oracle2mysql.json
(5)读取Oracle的数据存入HDFS中
[oracle@hadoop102 datax]$ bin/datax.py job/oracle2hdfs.json
(6)读取MongoDB的数据导入到HDFS
[atguigu@hadoop102 datax]$ bin/datax.py job/mongdb2hdfs.json
(7)读取MongoDB的数据导入MySQL
[atguigu@hadoop102 datax]$ bin/datax.py job/mongodb2mysql.json
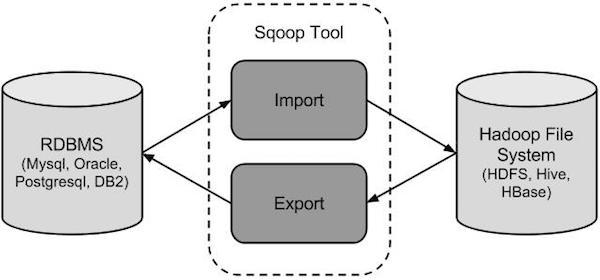
(二)Sqoop
Sqoop,SQL-to-Hadoop 即 “SQL到Hadoop和Hadoop到SQL”
(三)Canel
基于数据库增量日志解析,提供增量数据实时订阅和消费,目前主要支持了MySQL,也支持mariaDB。

三、调度
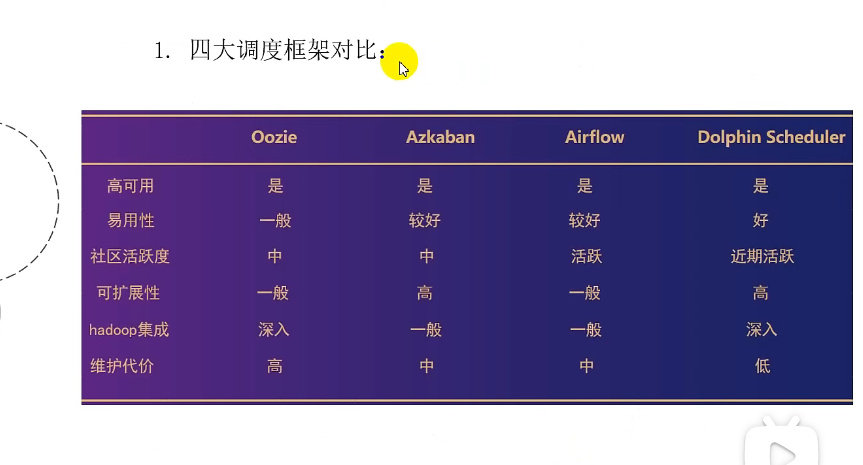
(一)DolphinSchedule
支持传统的shell任务,同时支持大数据平台任务调度:MR、Spark、SQL(mysql、postgresql、hive/sparksql)、python、procedure、sub_process【兼容传统与大数据】
通过拖拽来绘制DAG
(二)Azkaban
hadoop的job调度,适合shell脚本,当job不多的时候,可以使用
Azkaban支持直接传参,例如${input}。
(三)Oozie on Hue
hadoop可视化平台Hue的插件
Cloudera公司,需要预先将规则定义在workflow.xml中
Oozie支持参数和EL表达式,例如${fs:dirSize(myInputDir)}
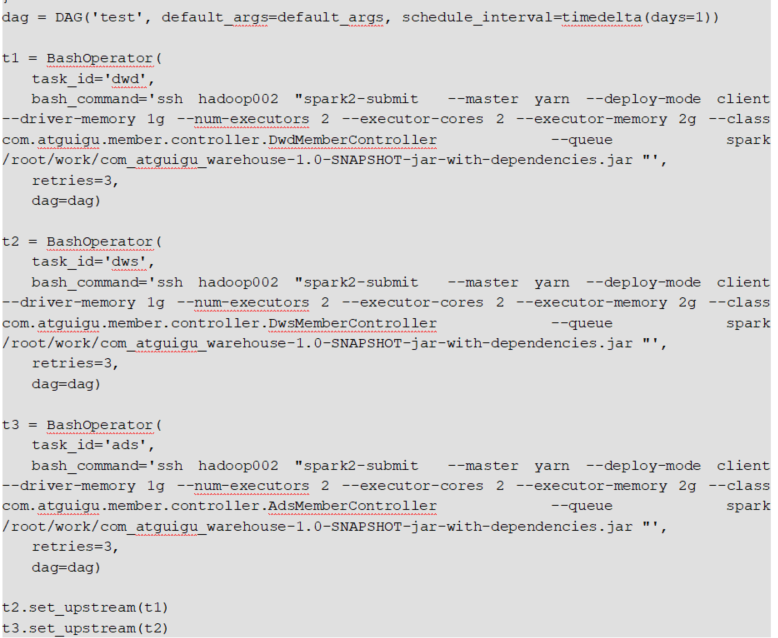
(四)Airflow
是apache的一个顶级开源项目由python编写
ariflow功能比azkaban完整强大
airflow在部署运维以及使用上要比azkaban复杂,成本高
将工作流编写任务的有向无环图(DAG)
通过airflow webserver -p 8080 -D启动web服务,通过airflow scheduler -D启动调度
通过编写python文件和配置文件,执行python文件中对应的任务
查看所有dag任务:airflow list_dags
(五)Xxl Job
转载:















 214
214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









