







二、levelDB整体框架,及memtable、log文件、immutable memtable
之中已经讲了leveldb的三个组件,其中log文件和加下来的sstable文件是学习leveldb的重点内容,并且sstable比log文件相对复杂一些。
但是理解了sstable的设计思想,对于了解其他数据库的底层存储也是有很大帮助的,因为很多思想是通用的。
接下来我们继续讲解,剩下的3大组件,重点是sstable;
3.4 SST文件

接下来介绍SSTable某个文件在磁盘上的结构,这对了解LevelDb的很有帮助。

LevelDb不同层级有很多SSTable文件(以后缀.sst为特征),所有.sst文件内部布局都是一样的。
刚才讲的Log文件是物理分块的,SSTable也一样会将文件划分为固定大小的物理存储块,但是两者逻辑布局大不相同;
根本原因是:Log文件中的记录是Key无序的,即先后记录的key大小没有明确大小关系,
而.sst文件内部则是根据记录的Key由小到大排列的,其中Key有序是设计.sst文件结构的关键。
Sstable由以下两个部分:数据存储区,数据管理区
数据存储区:包括dataBlock,存放实际的Key:Value数据
数据管理区:包括filter block,metaindex block,index block,footer,提供一些索引指针等管理数据,目的是更快速便捷的查找相应的记录。
data block:存储数据的block,每个sstable文件中有多个data block。
filter block和metaindex block:这两个block不一定存在于sstable,取决于Options中的filter_policy参数值,LevelDb 1.2版对于Meta Block尚无实际使用,只是保留了一个接口,估计会在后续版本中加入内容,不对这两部分进行讲解。
index block:存储的是索引数据,即可以根据index block中的数据快速定位到数据处于哪个data block的哪个位置。
footer:脚注数据,每个footer数据信息大小固定,存储一个sstable文件的元信息(meta data)。可以理解为索引的索引
接下来讲每个部分:
先看一下其中数据存储区中的单个data block 结构,它就像洋葱,需要一层一层拨开:
3.4.1 data block

从图中可以看出,其内部也分为两个部分:Block内容,Block尾部;
Block内容,是一个个KV记录,其顺序是根据Key值由小到大排列的,
在Block尾部则是一些“重启点”(Restart Point),其实是一些指针,指出Block内容中的一些记录位置。
我们需要先理解重启点:
看右图,我们可以把多个record分成多个组(看右下角图),每个组的第一个record就是一个重启点(看中间图,相当于每隔一段距离设置一个重启点)
(目的:每隔一段距离设置一个重启点,也是防止第一个数据出错,导致后续数据全部出错,我把record的存储讲完,record的存储方式和重启点是相辅相成的,所以讲完record的存储方式,更好理解重启点)
这就需要我们看一下,record是怎么存储的?(目的:减少Key的存储量)
我们一再强调,Block内容里的KV记录是按照Key从小到大有序的,这样的话,相邻的两条记录很可能Key部分存在重叠
基于这个特性,为了减少Key的存储量,我们看看record的内部结构是什么样的?
其详细结构,每个记录包含5个字段:key共享长度,key非共享长度,value长度,key非共享内容,value内容;
看结构能感受到,record的存储,后边的记录,会依赖前边某一条记录,被依赖的那条记录,就是重启点(那么重启点的目的也就一目了然了)
上述说的存储方式:前缀压缩(prefix-compressed)方式。这种算法的原理是:针对一组数据,取出一个公共的前缀,而在该组中的其它字符串只保存非公共的字符串做为key即可,由于sstable保存KV数据是严格按照key的顺序来排序的,所以这样能节省出保存key数据的空间来
举个例子,感受一下:理解了record的存储方式,可以更好的理解重启点
key1=abc,key2=abcd,key3=abef,key4=acde,key5=bcde 首先key是有序的,从小到大排序;
“重启点”的意思是:在这条记录开始,不再采取只记载不同的Key部分,而是重新记录所有的Key值
key1=abc作为重启点,整个key要记录下来,作为非共享部分key;
后续的,key2,3,4,会依据key1只存储不同的部分,相同的key前缀不需要存储;
key5=bcde作为新的重启点,后续的数据会依赖key5继续存储;
这里需要辨别一个误区,同样的数据,可以有多种前缀压缩方式,以下两种把key1作为重启点的方式,是错误的
方式一:
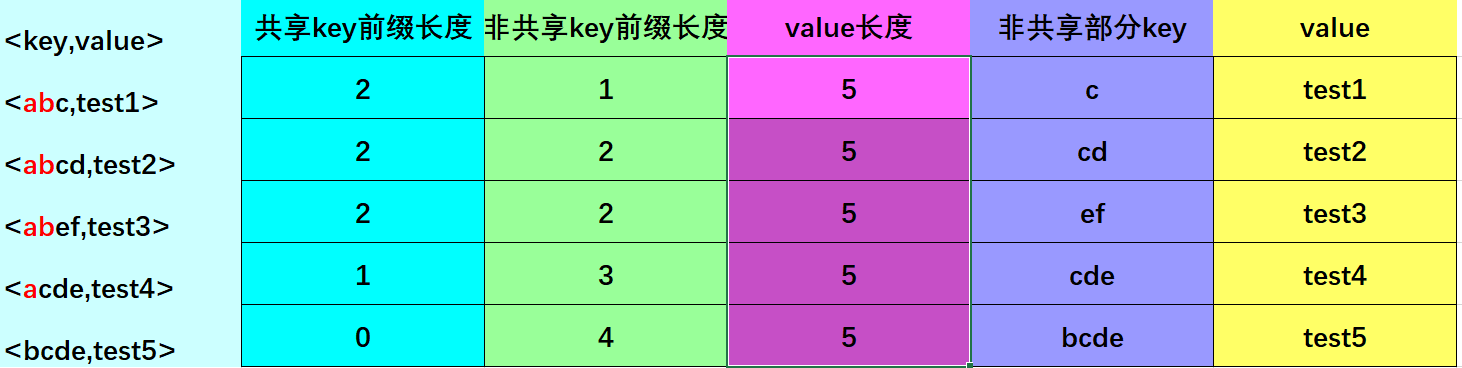
方式二:
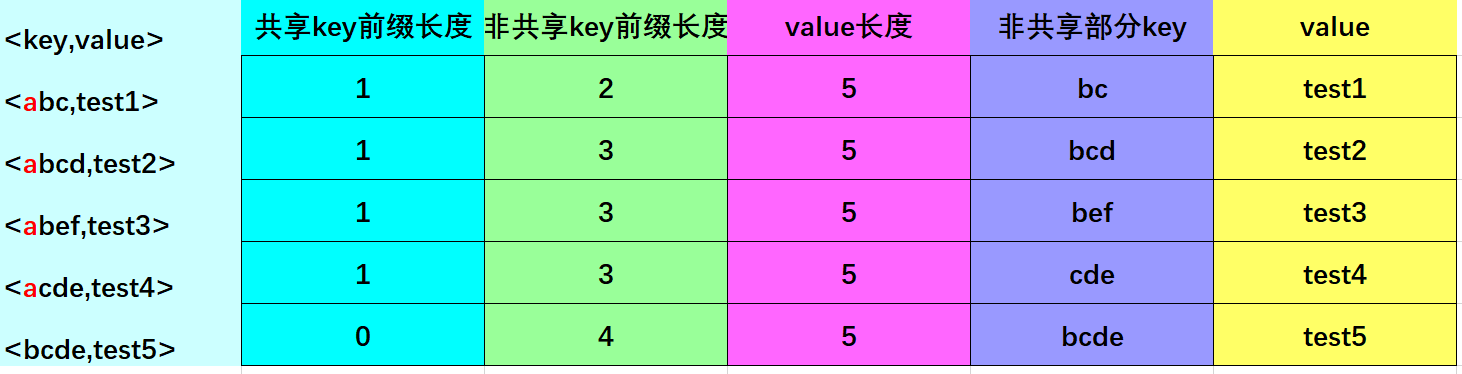
最终data block的整体结果如下:

3.4.2 index block
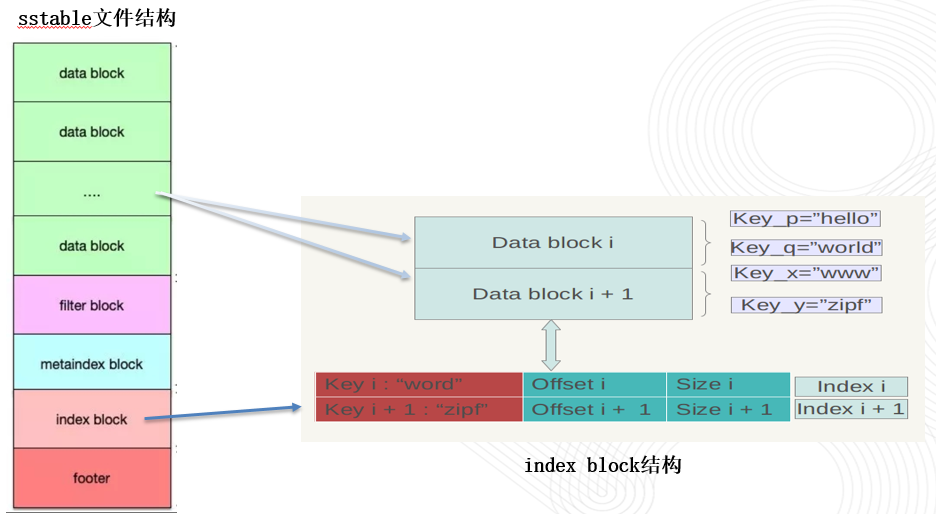
接着看看 index block的内部结构,相对简单一些。
index block:存储的是data block的索引数据,即可以根据index block中的数据快速定位到数据处于哪个data block的哪个位置。
每条索引信息包含三个内容,以图上的数据块i的索引Index i来说:
红色部分的第一个字段记载 数据块i中 最大的那个Key值,(每个block中有多个从小到大的record,取最大的key,我们可以想一下它的作用)
第二个字段指出 数据块i在.sst文件中的起始位置(偏移量)
第三个字段指出Data Block i的大小(有时候是有数据压缩的)。
3.4.3 footer

metaindex_handle指出了metaindex block的起始位置和大小;
inex_handle指出了index Block的起始地址和大小;
这两个字段可以理解为索引的索引,是为了正确读出索引值而设立的,后面跟着一个填充区和魔数
3.5 Current文件

3.6 Manifest文件

Manifest就记载了SSTable各个文件的管理信息。结构比较简单:属于哪个Level,文件名称叫什么,最小key和最大key。
到此,leveldb的6大组件,和其内部结构,我们讲完了!
接下来,看一下主要操作流程,后续更新。
相关内容快速导航:
一、LevelDB设计思想
二、levelDB整体框架,及memtable、log文件、immutable memtable
三、levelDB整体框架之sstable,manfest文件,current文件















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









