









levelDB 源码分析之 SSTable
1 SSTable 基本组成
SSTable 是 levelDB 磁盘上存储数据的结构。SSTable 分为不同的层次,其中除了第 0 层的 SSTable 之外,其他各层的 SSTable 中数据的 key 的范围没有任何重叠,并且各个 SSTable 内部数据按照 key 有序排列:

对于 levelDB 中的单个 SSTable,其内部数据也是根据 key 的大小有序排列的。对于 level0 的单个 SSTable ,它是将 memtable 持久化到磁盘中形成的,其格式如下:

SSTable 由 5 种 block 组成,分别为:Data block、Meta block、MetaIndex block、Index block 和 Footer。其中,Data block 中存储的是插入到 DB 中的 key/value 数据对;而其他的所有 block 都是为了索引或者加速 Data block 的读取,因此可以统称为元数据块。下面分别对它们进行详细的分析:
2 Data block 分析
Data block 存储的是插入到 DB 中的 key/value 数据,默认每个 block 的大小为 4KB(不是精确的 4KB,后面我们可以看到, datablock 中除了数据之外还有一些辅助字段,如重启点、CRC32校验码等。此外,还可以通过选项设置对 block 块进行压缩)。
Data block 结构:
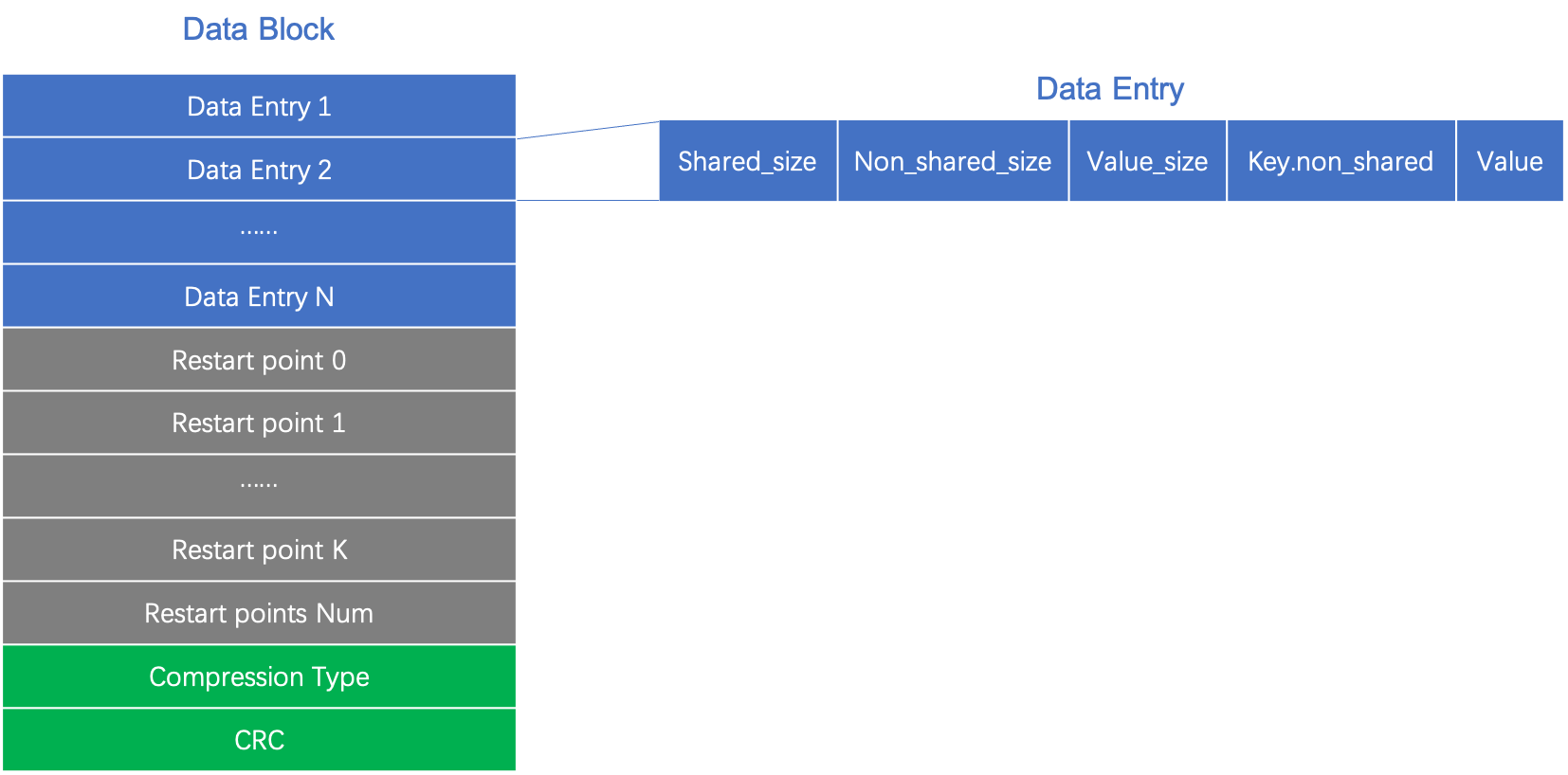
从上图可以看出,datablock 主要由数据项、重启点、压缩算法类型、CRC校验码四个部分组成。其中,数据项采用了共享前缀编码的方式来减少数据占用的存储空间;重启点主要用于防止数据损坏导致的雪崩效应和作为索引加速数据的搜索;Compression Type 标记数据压缩使用的算法类型;CRC32 校验码用于校验数据的完整性;对于上述的四个部分后面都会有详细的分析,这里先看看 data block 的构造过程:
data block 构造过程: 在向 SSTable 插入 key/value 数据对时,首先对数据进行编码(共享前缀编码),同时每隔固定条数据(默认为 16)记录一次数据的起始位置作为重启点;当数据占用总空间大于等于 block 的上限时表示 block 已满,此时需要将记录的重启点信息添加到数据末尾,然后使用压缩算法(默认为 Snappy 算法)对数据进行压缩;压缩完成之后计算 block 内容的 crc32 校验码,最后将压缩算法类型和校验码添加到 block 末尾形成一个完整的 data block。
下面对 data block 结构和构造过程中的两个重要点进行详细的分析:
(1)数据编码(共享前缀编码)
由于 SSTable 中数据的 key 是有序的,相邻数据对很大概率上会有相同的前缀。因此,在存储数据时,对于数据项的 key 可以只保存与前一个数据项的 key 不同的部分,并标记相同部分的大小,从而实现对 key 的压缩;
例如,要存储的相邻两项数据的 key 分别为 “hello” 和 “helloworld” ,则后一项数据的 key 可以只存储非共享前缀部分,也就是 “world”,并标记 key 的共享前缀大小为 5。
如 data block 的结构图中所示,leveldb 中对 key/value 的实际存储格式如下:

- shared_size:与前一对数据 key 共享前缀长度;
- non_shared_size:与前一对数据 key 非共享前缀长度;
- value_size:value 的长度;
- key.non_shared:与前一对数据 key 非共享前缀部分内容;
- value:value 的内容;
leveldb 代码中构造 data entry 的核心代码如下:
size_t shared = 0;
const size_t min_length = std::min(last_key_piece.size(), key.size());
while ((shared < min_length) && (last_key_piece[shared] == key[shared])) {
shared++;
}
const size_t non_shared = key.size() - shared;
// Add "<shared><non_shared><value_size>" to buffer_
PutVarint32(&buffer_, shared);
PutVarint32(&buffer_, non_shared);
PutVarint32(&buffer_, value.size());
// Add string delta to buffer_ followed by value
buffer_.append(key.data() + shared, non_shared);
buffer_.append(value.data(), value.size());
// Update state
last_key_.resize(shared);
last_key_.append(key.data() + shared, non_shared);
从代码中可以看出,leveldb 中首先计算 key 和 last_key 的共享前缀长度 shared,并计算出非共享前缀长度 non_shared = key.size() - shared,然后依次将 shared、non_shared、 value.size() 、key 的非共享部分和 value 写入到缓存区 buffer 中,最后更新 last_key。
(2)重启点(restart point)
从上一节可以看出,data block 中的数据项依赖于其前面的数据,如果 data block 中某个位置的数据发生损坏,则其后的所有数据都无法正常解析出来,形成雪崩效应。因此,为了避免单个数据损坏导致整个 data block 的数据不可用,leveldb 中每隔若干个数据项会强制取消共享 key 机制,这些位置的数据项会存储完整的 key/value 信息,这些位置也会保存在 data block 中,称为重启点。

其中,Restart point 0、1、2 分别记录的是 Data Entry 0、16、32 在 data block 中的位置。为了方便进行读取,这里的 restart poing 采用的 32bit 的固定长度编码,因此每个 restart point 占用 4bytes。
leveldb 中记录重启点的核心代码如下:
void BlockBuilder::Add(const Slice& key, const Slice& value) {
...
// options_->block_restart_interval 是重启点的间隔,默认为 16
if (counter_ < options_->block_restart_interval) {
... // 非重启点位置的处理,这里省略
} else {
// Restart compression
restarts_.push_back(buffer_.size());
counter_ = 0;
}
...
counter_++;
}
Slice BlockBuilder::Finish() {
// Append restart array
for (size_t i = 0; i < restarts_.size(); i++) {
PutFixed32(&buffer_, restarts_[i]);
}
PutFixed32(&buffer_, restarts_.size());
finished_ = true;
return Slice(buffer_);
}
从上述代码中可以看出,leveldb 中每隔 block_restart_interval 对数据记录一次重启点,最后在 block 构造结束的时候将重启点信息编码写入到缓存区 buffer 中。
Restart point 的另一个作用是作为 Data Entry 的索引,从而在 Data Entry 中搜索指定 key 的时候可以使用二分搜索(binary search)加速搜索。
leveldb 中在 data block 中搜索指定 key 的过程:
(1)首先根据布隆过滤器判断当前 block 是否可能存在 target key;
(2)查看 block cache 中是否缓存了该 block ,如果未缓存就从磁盘中读取整个 block 到内存并插入到 block cache 中。
(3)根据重启点信息在 block 中对 key 进行二分搜索(lower bound),找到最后一个小于等于 target key 的重启点。
(4)在该重启点之后的 16 项数据进行线性搜索,查找到 target key。
下面是利用重启点搜索 key 的核心代码:
while (left < right) {
uint32_t mid = (left + right + 1) / 2;
uint32_t region_offset = GetRestartPoint(mid);
uint32_t shared, non_shared, value_length;
const char* key_ptr =
DecodeEntry(data_ + region_offset, data_ + restarts_, &shared,
&non_shared, &value_length);
if (key_ptr == nullptr || (shared != 0)) {
CorruptionError();
return;
}
Slice mid_key(key_ptr, non_shared);
if (Compare(mid_key, target) < 0) {
// Key at "mid" is smaller than "target". Therefore all
// blocks before "mid" are uninteresting.
left = mid;
} else {
// Key at "mid" is >= "target". Therefore all blocks at or
// after "mid" are uninteresting.
right = mid - 1;
}
}
// We might be able to use our current position within the restart block.
// This is true if we determined the key we desire is in the current block
// and is after than the current key.
assert(current_key_compare == 0 || Valid());
bool skip_seek = left == restart_index_ && current_key_compare < 0;
if (!skip_seek) {
SeekToRestartPoint(left);
}
// Linear search (within restart block) for first key >= target
while (true) {
if (!ParseNextKey()) {
return;
}
if (Compare(key_, target) >= 0) {
return;
}
}
从上述代码中可以看出,leveldb 中先利用重启点二分搜索到了大概位置,然后对重启点之后的数据进行线性搜索,从而找到指定的 key。
3 Meta block 分析
Meta block 是 SSTable 中的元数据块。目前 levelDB 仅支持两种元数据块:“filter” Meta Block 和 “stats” Meta Block。其中,“filter” Meta Block 存储的是布隆过滤器,用于加速 data block 的搜索,后文会对布隆过滤器的实现进行详细分析;“stats” Meta Block 包含一系列统计信息,但 leveldb 中似乎没有用到,这里暂不分析。
因此,levelDB 中的 Meta block 主要就是指的 “filter” Meta Block,并且一个 SSTable 只包含一个 Meta Block,紧跟在 Data block 之后。下面是 “filter” Meta Block 的结构:
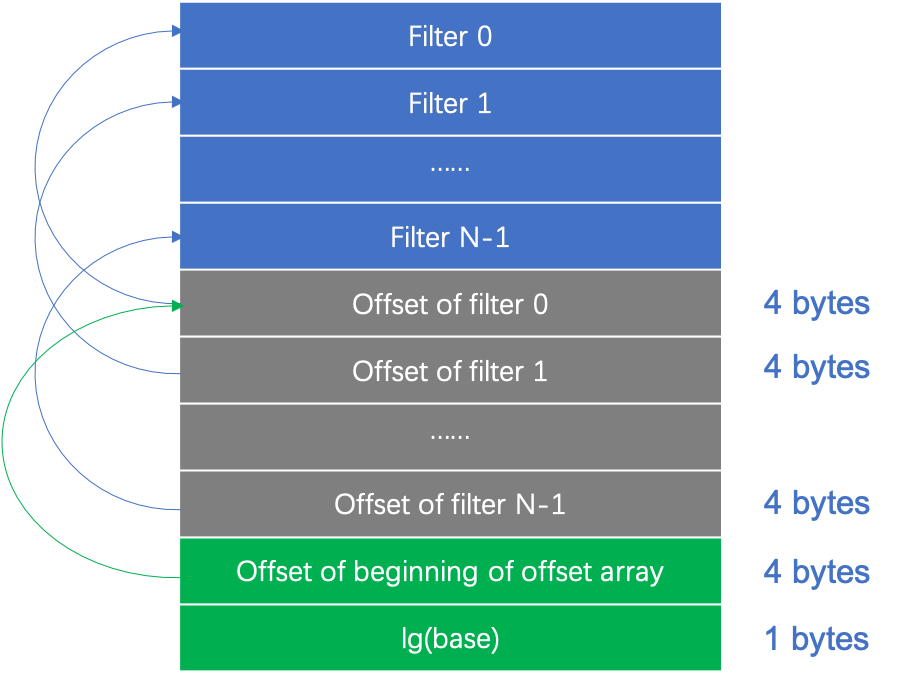
从上图可以看出,“filter” Meta Block 包含了多个 filter,以及它们的偏移信息。实际上,leveldb 中为每 2KB 的 data block 数据会生成一个 filter,因此上述的 Filter0、Filter1、… 和 Data block 0、Data block1、… 并不是一一对应的。
下面对 filter block 的构建和使用进行详细的分析:
filter block 构建过程:在向 SSTaable 插入key/value 数据对时, filterblock 的缓存区同步存储一份 key。当 datablock 数据满时,leveldb 会将 datablock 数据写入到文件的缓存区,随后利用 filterblock 缓存区的 key 数据构造出若干个 filter,并记录它们的偏移。最后在所有 datablock 构建完成之后,将所有的 filter 以及 filter 的偏移等信息写入到文件的缓存区中,形成一个 filterblock。
下面是 filter block 构建过程的核心代码:
void TableBuilder::Add(const Slice& key, const Slice& value) {
...
// 添加 key 的信息到 filterblock 的缓存中
if (r->filter_block != nullptr) {
r->filter_block->AddKey(key);
}
...
// datablock 已满时调用 Flush()
if (estimated_block_size >= r->options.block_size) {
Flush();
}
}
void TableBuilder::Flush() {
...
// 将 datablock 写入到文件缓存区
WriteBlock(&r->data_block, &r->pending_handle);
// 根据 filter_block 缓存的 key 构造 filter
if (r->filter_block != nullptr) {
r->filter_block->StartBlock(r->offset);
}
}
void FilterBlockBuilder::StartBlock(uint64_t block_offset) {
uint64_t filter_index = (block_offset / kFilterBase);
assert(filter_index >= filter_offsets_.size());
while (filter_index > filter_offsets_.size()) {
// 构造 filter
GenerateFilter();
}
}
void FilterBlockBuilder::GenerateFilter() {
...
// Generate filter for current set of keys and append to result_.
filter_offsets_.push_back(result_.size());
policy_->CreateFilter(&tmp_keys_[0], static_cast<int>(num_keys), &result_);
...
}
上述调用关系为:Add() -> Flush() -> StartBlock() -> GenerateFilter() -> CreateFilter(),最后的 CreateFilter 就是布隆过滤器的构造函数,这个在后面会详细分析。
filte block 使用过程:在 SSTable 中查找指定的 key 时,首先根据索引找到可能存在 target 的 datablock 的偏移 block_offset,然后block_offset / 2K 计算出 filter 的 index,根据索引信息在 filterblock 中找到对应的 filter,最后调用布隆过滤器的匹配函数进行过滤。
Status Table::InternalGet(const ReadOptions& options, const Slice& k, void* arg,
void (*handle_result)(void*, const Slice&,
const Slice&)) {
Status s;
Iterator* iiter = rep_->index_block->NewIterator(rep_->options.comparator);
iiter->Seek(k);
if (iiter->Valid()) {
Slice handle_value = iiter->value();
...
if (filter != nullptr && handle.DecodeFrom(&handle_value).ok() &&
!filter->KeyMayMatch(handle.offset(), k)) {
// Not found
} else {
// ...
}
}
...
}
bool FilterBlockReader::KeyMayMatch(uint64_t block_offset, const Slice& key) {
uint64_t index = block_offset >> base_lg_;
if (index < num_) {
uint32_t start = DecodeFixed32(offset_ + index * 4);
uint32_t limit = DecodeFixed32(offset_ + index * 4 + 4);
if (start <= limit && limit <= static_cast<size_t>(offset_ - data_)) {
Slice filter = Slice(data_ + start, limit - start);
return policy_->KeyMayMatch(key, filter);
} else if (start == limit) {
// Empty filters do not match any keys
return false;
}
}
return true; // Errors are treated as potential matches
}
其中,iiter->Seek(k) 找到了可能存在 key 的 datablock,然后根据 datablock 的偏移信息计算出了 filter 的位置。
值得注意的是,leveldb 中的 datablock 和 filter 并不是一一对应,因此需要根据 datablock 的 block_offset 计算得到 filter 的位置,理解了这一点就更容易理解 filterblock 的构建和使用过程了。
4 Metaindex block 分析
Metaindex block 叫做元索引块,它为每一个 Meta block 保存一个 key/value 对:
key :Meta block 的名字(name);
value:Meta block 的 大小(size)和偏移(offset);
Metaindex block 和 Data block 的存储方式相同,采用了前缀压缩编码和重启点的技术,但是由于目前只有 “filter” Meta block 一个 Meta block,因此 Metaindex block 中最多只有一个 entry 和一个 restart point。
Metaindex block 的构建:在构建 SSTable 的收尾阶段,levedb 会将 Metablock 的内容写入到文件缓存区中,同时将 Metablock 的大小和起始位置记录到 filter_block_handle ,随后和 Metablock 的名字一起通过前缀压缩和重启点的技术编码到 Metaindex block 中。由于目前 SSTable 中只有一个 Metablock,因此直接将 Metaindex block 写入到文件缓冲区,完成 Metaindex block 的构建。
Status TableBuilder::Finish() {
// 完成 Data block 的构建
...
// Write filter block
if (ok() && r->filter_block != nullptr) {
WriteRawBlock(r->filter_block->Finish(), kNoCompression,
&filter_block_handle);
}
// Write metaindex block
if (ok()) {
BlockBuilder meta_index_block(&r->options);
if (r->filter_block != nullptr) {
std::cout << __LINE__ << std::endl;
// Add mapping from "filter.Name" to location of filter data
std::string key = "filter.";
key.append(r->options.filter_policy->Name());
std::string handle_encoding;
filter_block_handle.EncodeTo(&handle_encoding);
meta_index_block.Add(key, handle_encoding);
}
// TODO(postrelease): Add stats and other meta blocks
WriteBlock(&meta_index_block, &metaindex_block_handle);
}
// index block、footer 的构建
return r->status;
}
Metaindex block 的使用:在打开 SSTable 的最后一步是读取 Metablock 的信息,也就是读取 “filter” Meta block 的数据。首先从 footer 中获取 metaindex block 的大小和偏移,并将其从磁盘中读取出来。然后根据 filter block 的 name 从 metaindex block 中搜索出对应的 “filter” Meta block,这个过程和 datablock 中搜索指定的 key 相同。当搜索到 “filter” Meta block 的 metaindex 信息后就可以从磁盘中读取出完整的 “filter” Meta block,待后续使用。
Status Table::Open(const Options& options, RandomAccessFile* file,
uint64_t size, Table** table) {
...
if (s.ok()) {
...
// @wavenz: 读取 Meta block 的数据
(*table)->ReadMeta(footer);
}
return s;
}
void Table::ReadMeta(const Footer& footer) {
...
BlockContents contents;
if (!ReadBlock(rep_->file, opt, footer.metaindex_handle(), &contents).ok()) {
// Do not propagate errors since meta info is not needed for operation
return;
}
Block* meta = new Block(contents);
// @wavenz: 在 Metaindex block 中搜索 "filter" Meta block
Iterator* iter = meta->NewIterator(BytewiseComparator());
std::string key = "filter.";
key.append(rep_->options.filter_policy->Name());
iter->Seek(key);
if (iter->Valid() && iter->key() == Slice(key)) {
ReadFilter(iter->value());
}
delete iter;
delete meta;
}
从上述代码可以看出,Metaindex block 和 Meta block 的数据都是在打开 SSTable 的时候进行读取。
5 Index block 分析
Index block 存储的是 SSTable 中所有 Data block 的索引信息,如下图所示:
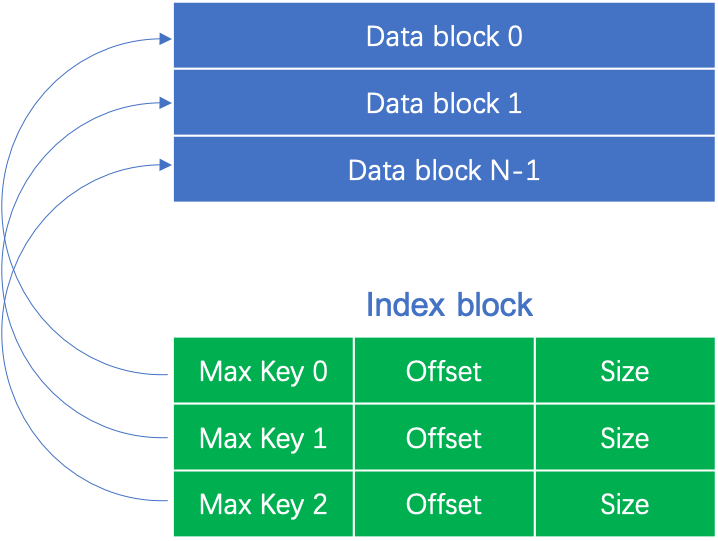
其中,Max Key 0 是 Data block 0 中最大的 key,offset 和 size 是对应的 Data block 的起始位置和大小。当然,Index block 中的数据并不是按上图中的格式进行存储,而是与 Data block 和 MetaIndex block 一样采用了前缀压缩和重启点技术进行编码,然后再写入到 SSTable 中。
从 Index block 中查找指定的 key 所在的 data block 的过程与在 data block 中搜索指定 key 的过程是完全一致的,因为他们都是通过 Block::Iter::Seek() 方法进行查找。大致的过程是:首先通过 index block 的重启点信息在所有的 Index Entry 中进行二分搜索,搜索出最后一个 key 小于等于 target 的重启点,然后在该重启点位置的后面的 Index Entry 中进行线性搜索,搜索出可能存在 target 的 data block 的 Index Entry,从而找到对应的 data block。
上述搜索过程在 Index block 中比较难以理解,这里我们可能看作是在一本书的目录中先后进行二分搜索和线性搜索,而在 data block 中的搜索则是在对应的章节进行二分搜索和线性搜索。
6 Footer 分析
Footer 是文件末尾存储的 SSTable 的一些固定信息,这里实际上就是 metaindex block 和 index block 的大小和文件偏移位置,以及一个 Magic number;

因此,可以通过 Footer 的信息解析出 Metaindex blcok 和 Index block 的位置和大小。
下面是构造 Footer 的核心代码:
void Footer::EncodeTo(std::string* dst) const {
const size_t original_size = dst->size();
metaindex_handle_.EncodeTo(dst);
index_handle_.EncodeTo(dst);
dst->resize(2 * BlockHandle::kMaxEncodedLength); // Padding
PutFixed32(dst, static_cast<uint32_t>(kTableMagicNumber & 0xffffffffu));
PutFixed32(dst, static_cast<uint32_t>(kTableMagicNumber >> 32));
assert(dst->size() == original_size + kEncodedLength);
(void)original_size; // Disable unused variable warning.
}
7 总结
上面梳理了 SSTable 的 5 个组成块:Data block、Meta block、MetaIndex block、Index block、Footer。其中,Data block、MetaIndex block 和 Index block 同样采用了前缀压缩和重启点技术进行存储,减少了存储的空间并提高了搜索的效率;Meta block 目前只支持 “filter” Meta block,也就是布隆过滤器,用于减少不必要的 Data block 的读取;Footer 存储了两个索引块的位置和大小,可以看作是索引的索引,因此在解析 SSTable 的时候可以从 Footer 开始一步一步地将所有的内容都解析出来。最后,给出 SSTable 的详细结构图:
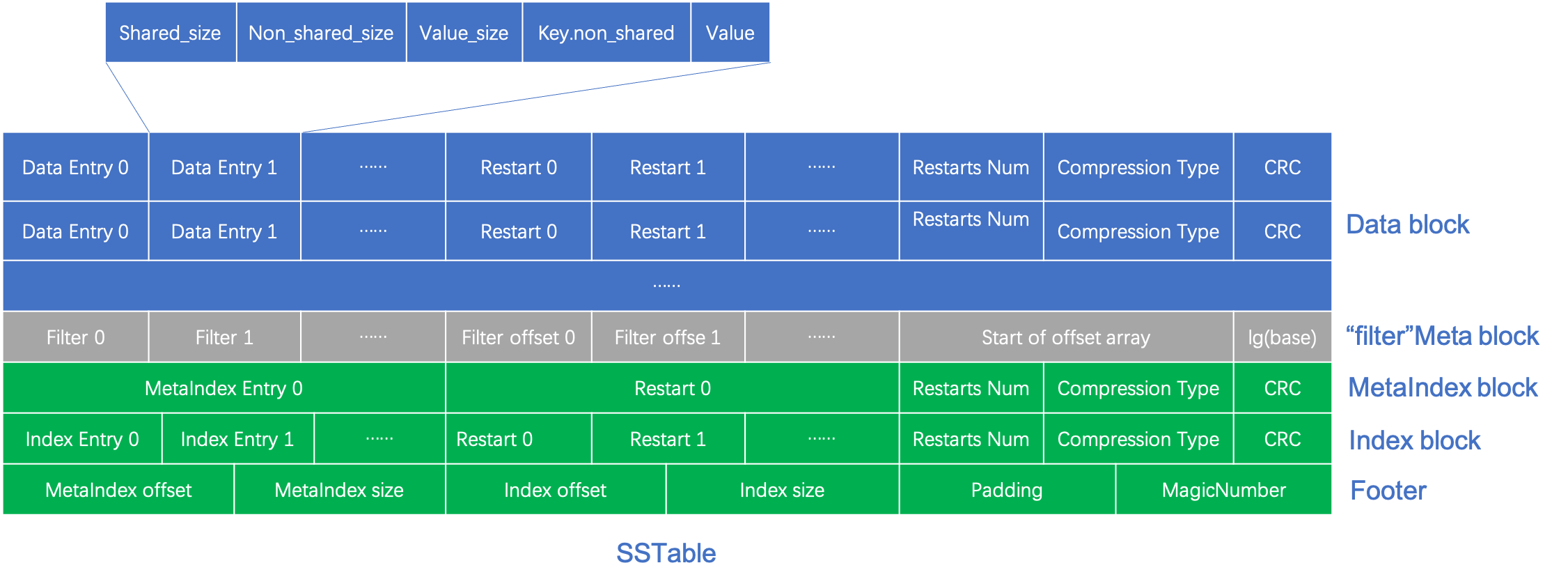















 4526
4526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









