






概念
Map和set是一种专门用来进行搜索的容器或者数据结构,其搜索的效率与其具体的实例化子类有关。在之前我们常见的搜索方式一般有两种:
- 一种是直接遍历,这种方法的时间复杂度为O(N),如果元素比较多的话效率会十分低下
- 另一种是二分查找,时间复杂度为O(logN),但是有局限性必须是有序的
这两种排序一般用在静态查找,在查找时一般不会进行插入和删除,但现实中我们需要的往往是动态查找,即在查找时会进行一些插入和删除操作。这时就要用到map和set了,这两个是一种适合动态查找的集合容器。
模型
在聊map和set之前我们要先聊一聊key模型和value模型,一般把搜索的数据称为关键字(Key),和关键字对应的称为值(Value),将其称之为Key-value的键值对,所以 模型会有两种:
1. 纯 key 模型,比如:
有一个英文词典,快速查找一个单词是否在词典中
快速查找某个名字在不在通讯录中
2. Key-Value 模型,比如:
统计文件中每个单词出现的次数,统计结果是每个单词都有与其对应的次数:<单词,单词出现的次数>
而Map中存储的就是key-value的键值对,Set中只存储了Key。
Map
说明
Map是一个接口类,不能直接实例化,该类并不继承自Cllection,它按照特定的次序(按照key来比较)存储由键值key和值value组合而成的元素,并且Key一定是唯一的,不能重复。
Map.Entry<k,v>
Map.Entry 是Map内部实现的用来存放键值对映射关系的内部类,该内部类中主要提供了 的获取,value的设置以及Key的比较方式。

Map.Entry的主要作用就是将key和value组合起来方便之后打印
//注意:Map.Entry并没有提供设置Key的方法
Map的常用方法
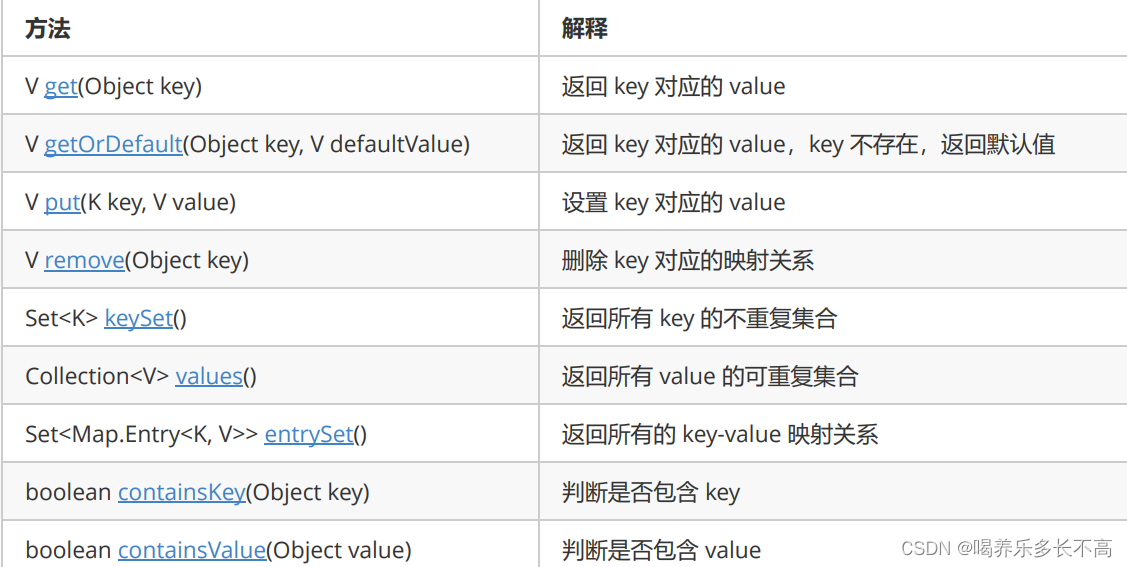
- Map是一个接口,不能直接实例化对象,如果要实例化对象只能实例化其实现类TreeMap或者HashMap
- Map中存放键值对的Key是唯一的,value是可以重复的
- 在Map中插入键值对时,key不能为空,否则就会抛NullPointerException异常,但是value可以为空
- Map中的Key可以全部分离出来,存储到Set中来进行访问(因为Key不能重复)。
- Map中的value可以全部分离出来,存储在Collection的任何一个子集合中(value可能有重复)。
- Map中键值对的Key不能直接修改,value可以修改,如果要修改key,只能先将该key删除掉,然后再来进行 重新插入。
- Map中不能存储重复的Key如果存入的Key在Map里有则会覆盖掉原来的Key和value
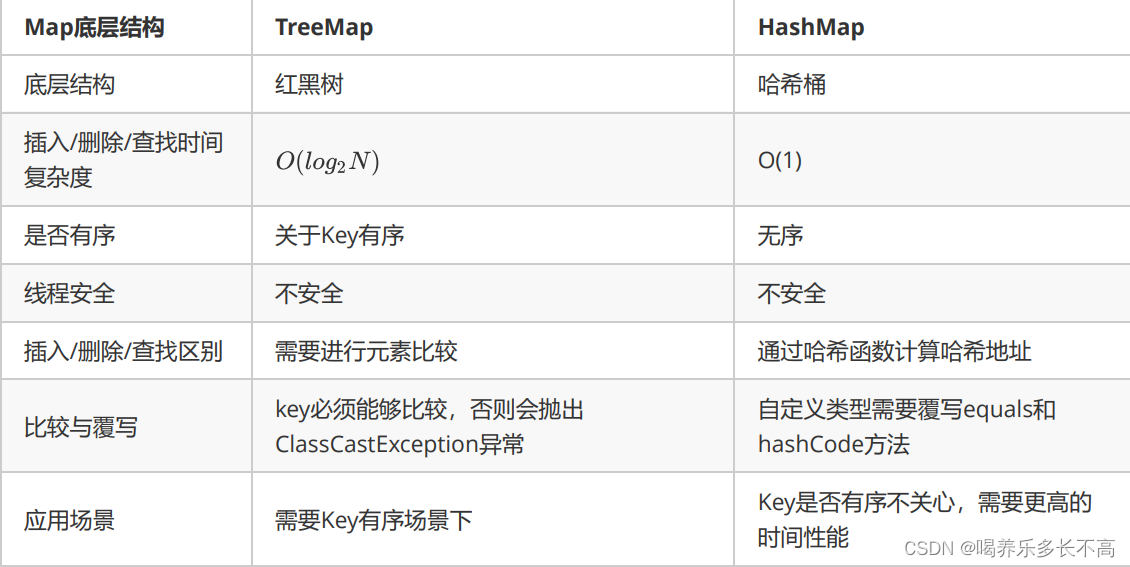
TreeMap的使用
TreeMap的底层是一颗搜索树,搜索树的插入需要通过key来比较大小的如下图案例:


我们再来思考一下,既然插入是通过key来比较的那么是不是就意味着,key一定是可以比较的,所以当key是自定义类型时一定要注意,key要可比较。
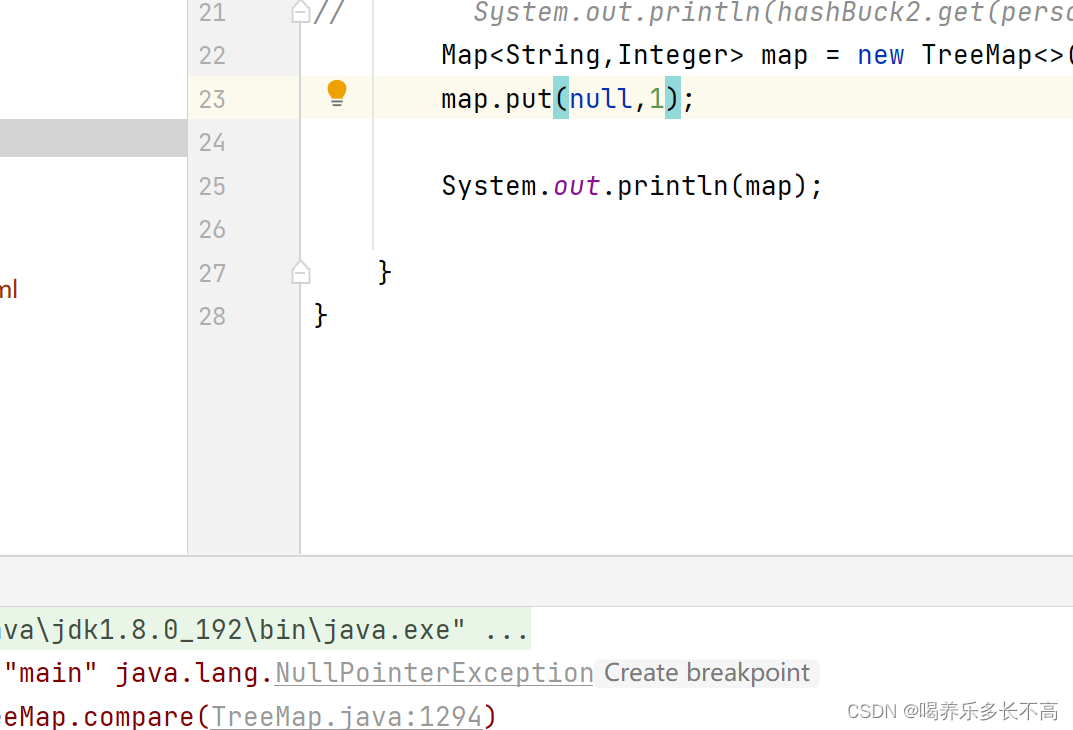
key的值不能是null
TreeMap的遍历
TreeMap的遍历分为调用keySet()方法遍历和entrySet()方法遍历两种:
keySet():
Map<String,Integer> map = new TreeMap<>();
map.put("a",1);
map.put("c",3);
map.put("d",4);
map.put("b",2);
//在TreeMap的遍历中我们可以通过key利用get方法找到value
//keySet(),的作用是返回所有 key 的不重复集合
//所以set的泛型与key的数据类型一致,在本代码中为String类型
Set<String> set = map.keySet();//返回所有map中的key存入Set集合中
//set就是一个存放map中的key的集合
//接下来利用forEach遍历
//String为set中元素的类型,str里存的就是map里key的值
//所以可以通过str找到value
for (String str:set) {
//通过map.get(str)来获得map里每一个key所对应的value值
Integer a = map.get(str);//根据str的值找到对应的value存入a中
System.out.println("key:" + str +" "+ "val:" + a);
}
System.out.println(map);运行结果

entrySet():
Map<String,Integer> map = new TreeMap<>();
//存放数据
map.put("a",1);
map.put("c",3);
map.put("d",4);
map.put("b",2);
//当我们调用entrySet()时,Set的泛型类型应与Map.Entry的类型一致,即<String,Integer>
//<String,Integer>就是<k,v>键值对
Set<Map.Entry<String,Integer>> set = map.entrySet();//返回所有map中的 key-value 映射关系
//存储在set中,set就是<String,Integer>的集合(<a,1>,<b,2>,<c,3>,<d,4>)
//之后通过forEnch遍历
//Map.Entry<String,Integer>就是set里元素的类型
//m就是map里的每一个键值对<String,Integer>
for (Map.Entry<String,Integer> m :set) {
//因为m就是map里的每一个键值对<String,Integer>
//所以直接输出m也可以
//也可以利用get.Value和get.Key进行打印
System.out.println(m);
}
//hashmap会在之后的博客中讲到
Set
Set与Map主要的不同有两点:
- Set是继承自Collection的接口类
- Set中只存储了Key
Set的常用方法:
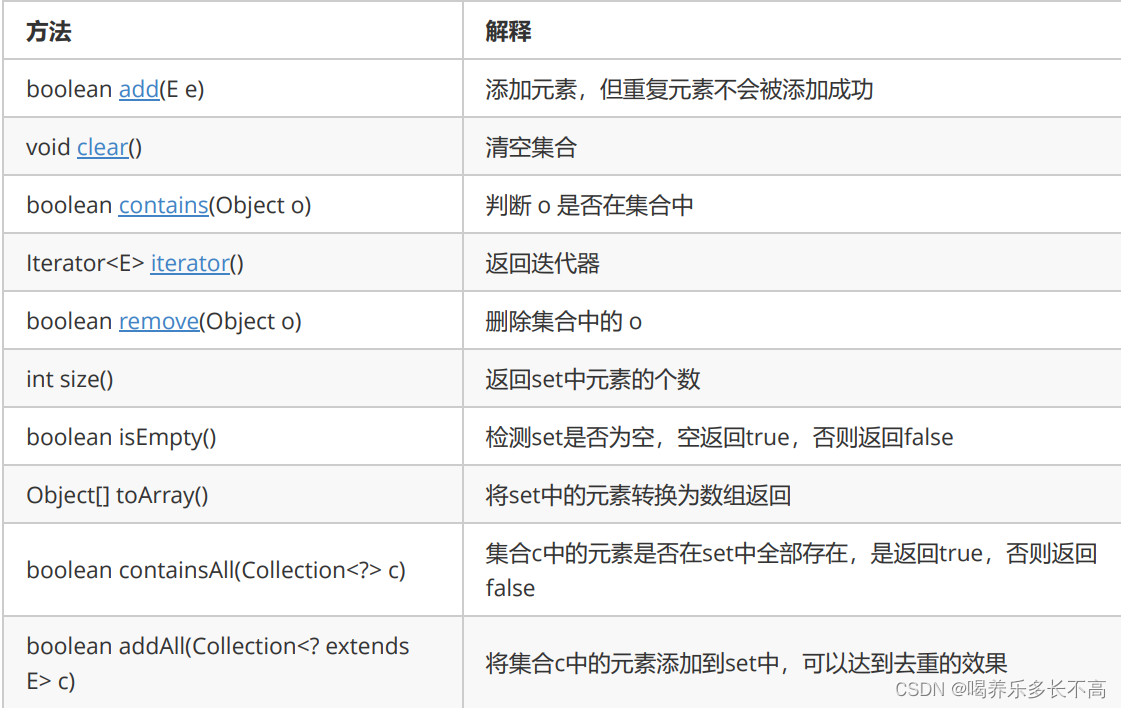
注意:
- Set是继承自Collection的一个接口类
- Set中只存储了key,并且要求key一定要唯一
- Set的底层是使用Map来实现的,其使用key与Object的一个默认对象作为键值对插入到Map中的
- Set最大的功能就是对集合中的元素进行去重
- 实现Set接口的常用类有TreeSet和HashSet,还有一个LinkedHashSet,LinkedHashSet是在HashSet的基础 上维护了一个双向链表来记录元素的插入次序。
- Set中的Key不能修改,如果要修改,先将原来的删除掉,然后再重新插入
- Set中不能插入null的key
- 因为Set中的元素是不可重复的,所以Set一般用作去重
TreeSet
TreeSet里的元素是不可重复的,如下例子

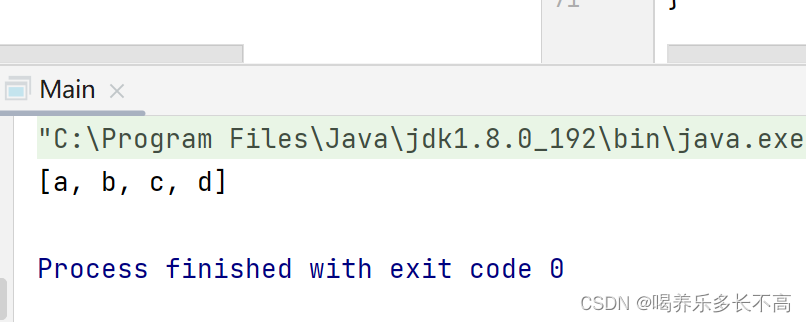
那么为什么TreeSet里的元素不可被重复呢?其时TreeSet的底层是一个TreeMap,它的key值是你add的对象的类型,value值是一个默认的Object对象,而TreeMap的key值是不可被重复的
我们再来看看这个例子:
class Student implements Comparable<Student>{
public String name;
public Integer age;
public Integer high;
public Student(String name, Integer age, Integer high) {
this.name = name;
this.age = age;
this.high = high;
}
@Override
public int compareTo(Student o){
return -1;
}
public String toString(){
return "name: " + this.name + " age: " + this.age + " high: " + this.high;
}
} Set<Student> set = new TreeSet<>();
set.add(new Student("zhangsan",12,150));
set.add(new Student("zhangsan",12,150));
set.add(new Student("lisi",22,180));
set.add(new Student("wangwu",32,178));
for(Student student:set){
System.out.println(student);
}
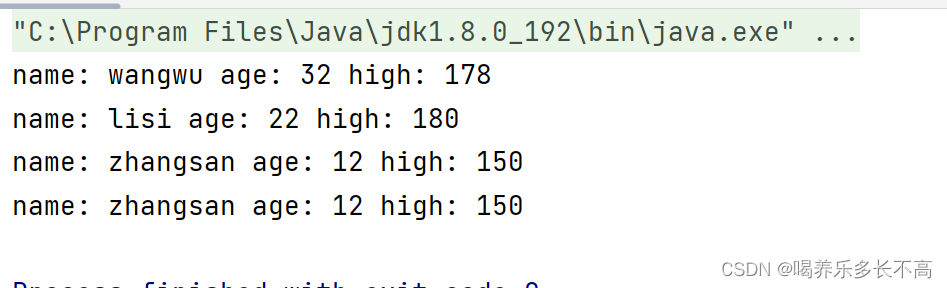
怎么回事?不是说不能有重复元素吗,这里怎么输出了两个重复元素,其这只是我们认为的相同元素,编译器可不这样认为,我们并没有完全重写compareTo方法,编译器是通过比较他们存储的内存地址来比较他们是否不同,所以在编译器看来它们都是不同的元素。所以如果我们要想不让我们输出的数据重复,需要重写compareTo方法
接下来我们按照年龄比较:


可以看到并没有重复年龄的学生
到这里我们就聊完了,Map和Set有关的知识不止这些还有很多,博主会在之后的博客中在聊到,如果你有说明不懂或者一些其他的见解欢迎评论或者私信博主,也希望可以支持一下博主啦!!!
我们下一篇再见了















 1800
1800











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









