






 本文详细介绍了Java中的Map和Set数据结构,包括它们的概念、场景、实例化类的区别,以及Map.Entry的工作原理。还探讨了哈希表的概念、冲突避免策略(如设计合理的哈希函数和负载因子调节)和冲突解决方法(开散列)。
本文详细介绍了Java中的Map和Set数据结构,包括它们的概念、场景、实例化类的区别,以及Map.Entry的工作原理。还探讨了哈希表的概念、冲突避免策略(如设计合理的哈希函数和负载因子调节)和冲突解决方法(开散列)。
🏀🏀🏀来都来了,不妨点个关注!
🎧🎧🎧博客主页:欢迎各位大佬!

文章目录
1. Map和Set的相关概念及说明
1.1概念及场景
Map和Set是一种专门用来进行搜索和去重操作的容器或数据结构,其搜索效率与其具体实例化的子类有关。 在以前的学习中,我们常见的搜索方式有:
- 直接遍历:时间复杂度:O(N),但当数据量巨大的时候,比如一百万个数据,且我们要搜索的效率在最后面的时候,搜索效率就会变的十分低。
- 二分查找:时间复杂度:O(logN),但它有个前提是,数据是可排序的并且数据已经是有序的。
上述排序比较适合静态的查找,即一般不会对数据进行插入删除操作了,而现实中的很多查找如下:
1.根据姓名查询成绩
2.根据身份证号查询信息
上述可能在查询的过程中会进行插入或删除操作,即动态查找,上述的方法就不适合了,而本文介绍Map和Set则是一种适合动态查找的容器。
1.2 模型
一般我们把要搜索的数据叫做关键字(Key),而关键字对应的称为值(Value),将之称为Key-Value的键值对,所以就有下如下两种模型:
1.纯Key模型:
例如英语词典,我们查找某个单词就只搜索这个关键字。一般纯Key模型也可以用来进行去重操作。
2.Key-Value模型:
例如我和女朋友经常使用学习软件里的自习室进行学习时长的记录,里面记录的值就是Key-Value模型,(我,5h),(女朋友,6.5h)。一般Key-Value模型可以用来统计某个数据出现的次数。
而Map中存储的就是key-value的键值对,Set中只存储了Key。
2. Map的相关说明
Map是一个接口类,该类没有继承自Collection,该类中存储的是<K,V>结构的键值对,并且K一定是唯一的,不能重复
2.1 Map相关方法的介绍
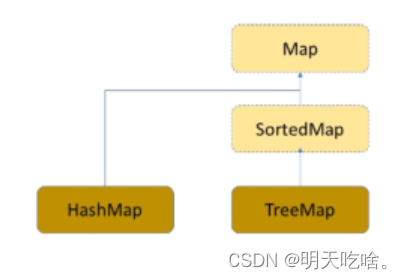
通过上面这张图我们可以看出,Map的两个实例化类分别是HashMap和TreeMap。
HashMap和TreeMap的区别:
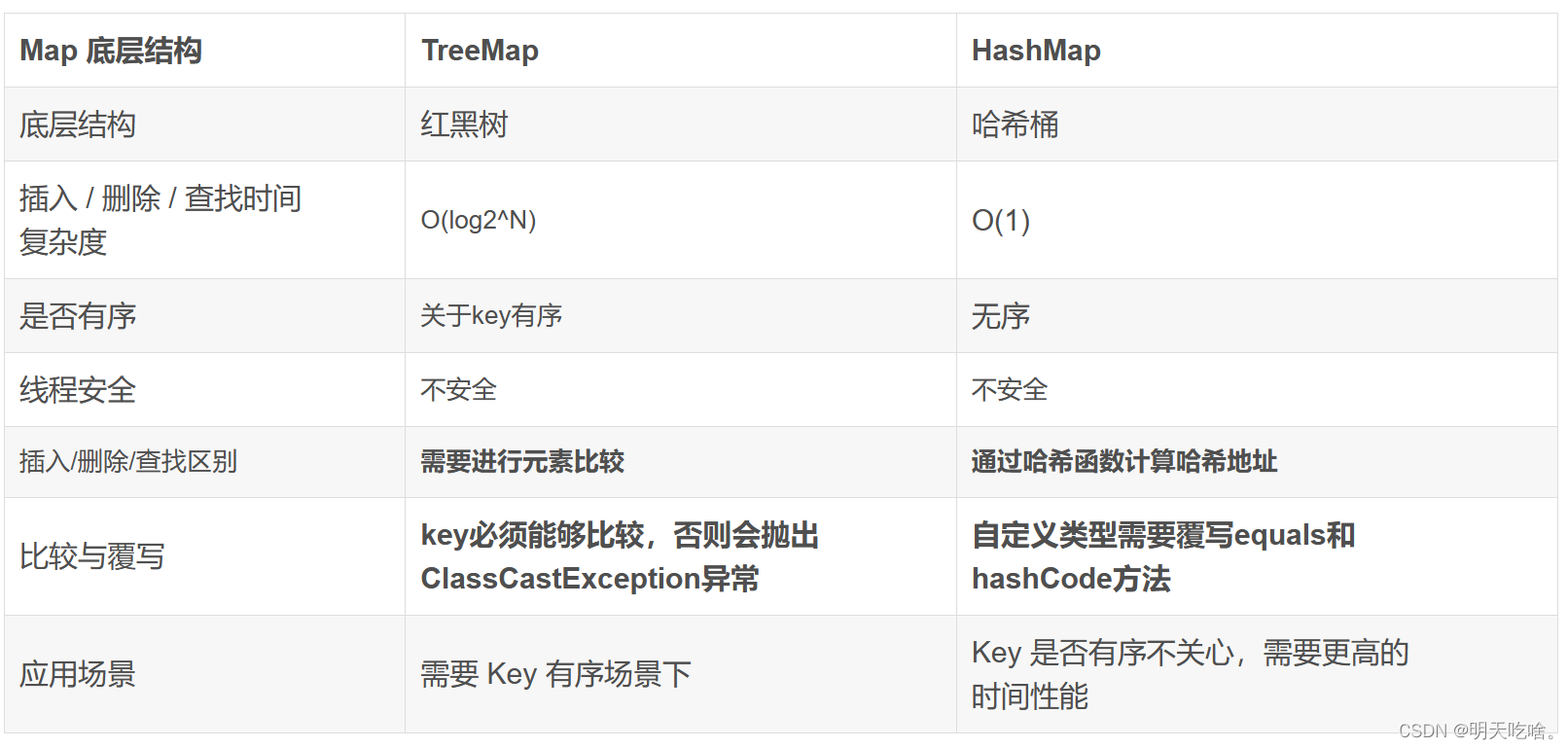
在Java中HashMap的底层是实现了一个哈希桶,本文的后面会详细介绍;而TreeMap的底层是红黑树,而红黑树是一棵近似平衡的二叉搜索树,即在二叉搜索树的基础之上 +颜色以及红黑树性质验证,关于红黑树的性质我们之后再做详解。这里我们对二叉搜索树有大致理解即可,可以翻看我之前的二叉搜索树章节进行理解。
下面我们对Map的一些常用方法进行举例:
代码实现:(这里只介绍几种)
import java.util.Map;
import java.util.Set;
import java.util.TreeMap;
public class Test {
public static void main(String[] args) {
Map<String,String> map = new TreeMap<>();
map.put("卡莎","虚空之女");
map.put("诺手","诺克萨斯之手");
map.put("剑魔","亚托克斯");
map.put("吸血鬼","弗拉基米尔");
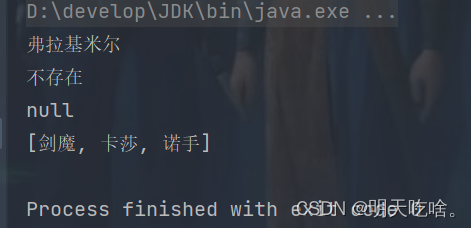
System.out.println(map.get("吸血鬼")); //获取关键字Key对应的Value
System.out.println(map.getOrDefault("格温", "不存在")); //查询某个关键字Key的Value找不到就返回我们设定的default值
map.remove("吸血鬼");//删除Key对应的映射关系
System.out.println(map.get("吸血鬼"));
Set<String> set= map.keySet(); 获取所有Key的集合
System.out.println(set);
}
}
打印结果:
2.2 Map.Entry<K,V>介绍(重点)
Map.Entry<K,V>是Map内部实现的用来存放<K,V>的映射关系的内部类。 该内部类中主要提供了<key, value>的获取,value的设置以及Key的比较方式。
我们可以通过用Set容器和map.entrySet()方法拿到这个映射关系,下面我们上图理解:
这里map.entrySet()方法将这个<K,V>这整个键值对打包放入到Set容器里。
代码理解:
import java.util.Map;
import java.util.Set;
import java.util.TreeMap;
public class Test {
public static void main(String[] args) {
Map<String,String> map = new TreeMap<>();
map.put("卡莎","虚空之女");
map.put("诺手","诺克萨斯之手");
map.put("剑魔","亚托克斯");
map.put("吸血鬼","弗拉基米尔");
Set<Map.Entry<String,String>> s = map.entrySet();
for (Map.Entry<String,String> entry: s) {
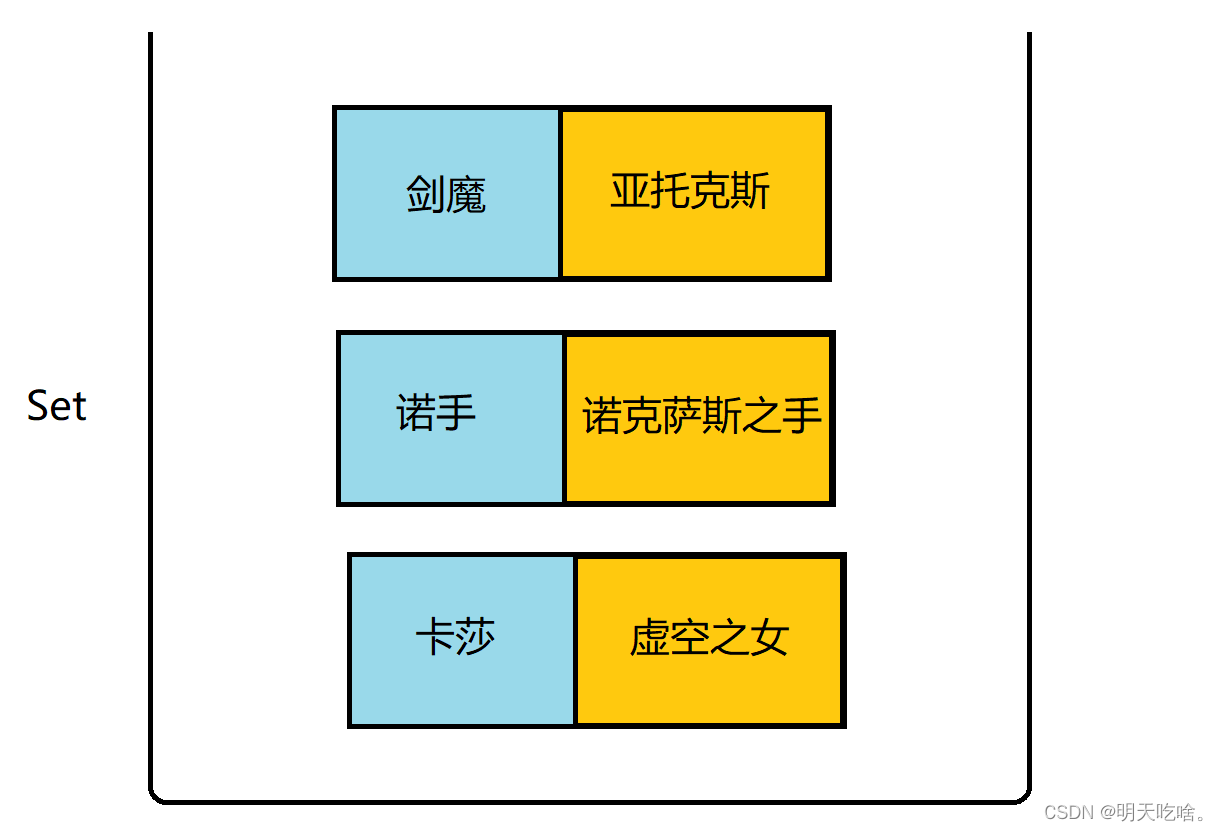
System.out.println("Key : " + entry.getKey() + " Value : " + entry.getValue());
}
}
上述提到的getKey()和getValue()则是Map.Entry<K,V>这个内部类里面实现的方法。
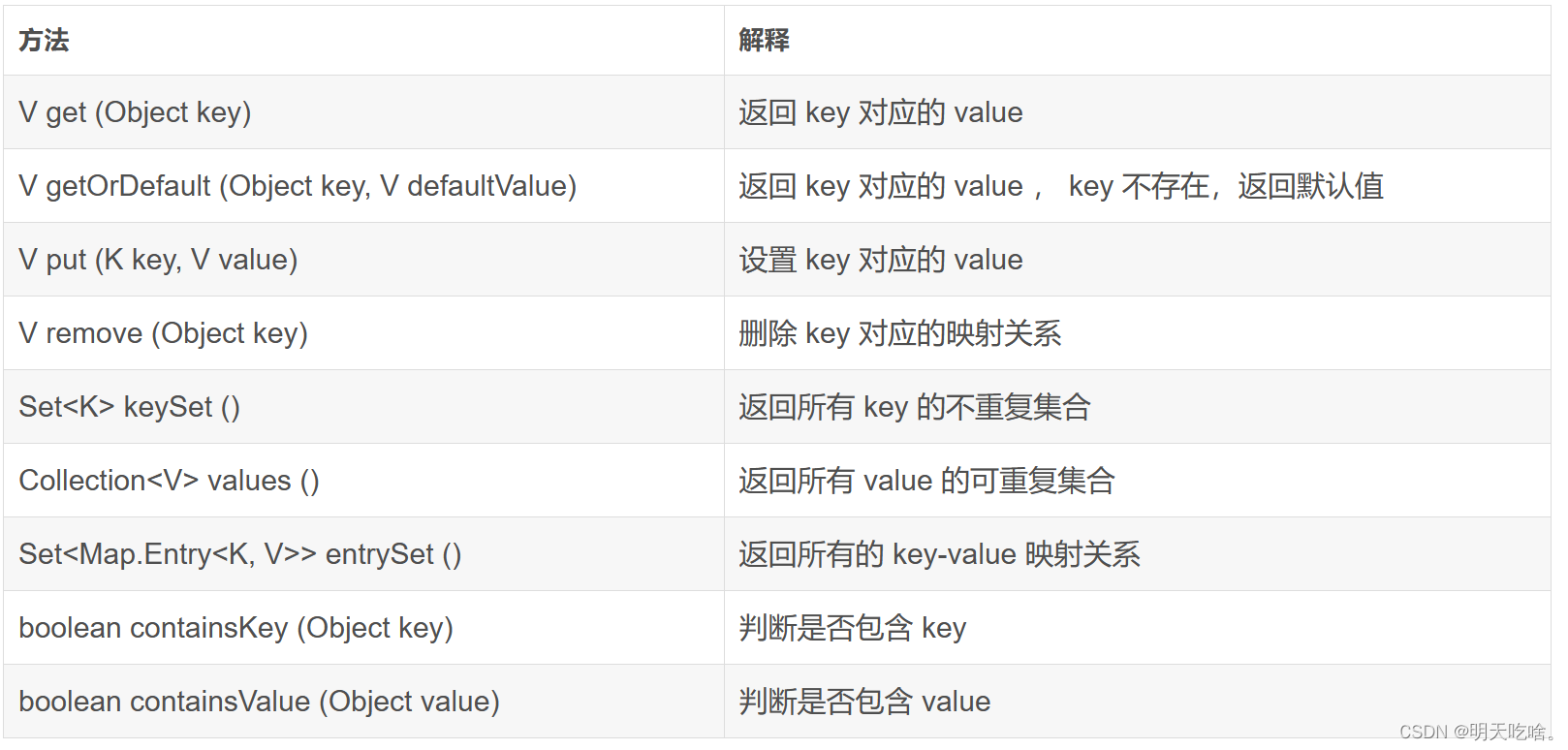
以下是该类提供的一些方法:

值得注意:Map.Entry<K,V>并没有提供设置Key的方法
2.3 总结
1.Map是一个接口,不能直接实例化对象,如果要实例化对象只能实例化其实现类TreeMap或者HashMap
2. Map中存放键值对的Key是唯一的,value是可以重复的
3. 在TreeMap中插入键值对时,key不能为空,否则就会抛NullPointerException异常,value可以为空。但是HashMap的key和value都可以为空。
4. Map中的Key可以全部分离出来,存储到Set中来进行访问(因为Key不能重复)。
5. Map中的value可以全部分离出来,存储在Collection的任何一个子集合中(value可能有重复)。
6. Map中键值对的Key不能直接修改,value可以修改,如果要修改key,只能先将该key删除掉,然后再来进行 重新插入。
3.Set的相关说明
Set与Map主要的不同有两点:Set是继承自Collection的接口类,Set中只存储了Key。
Set的主要应用场景是对元素进行去重操作。
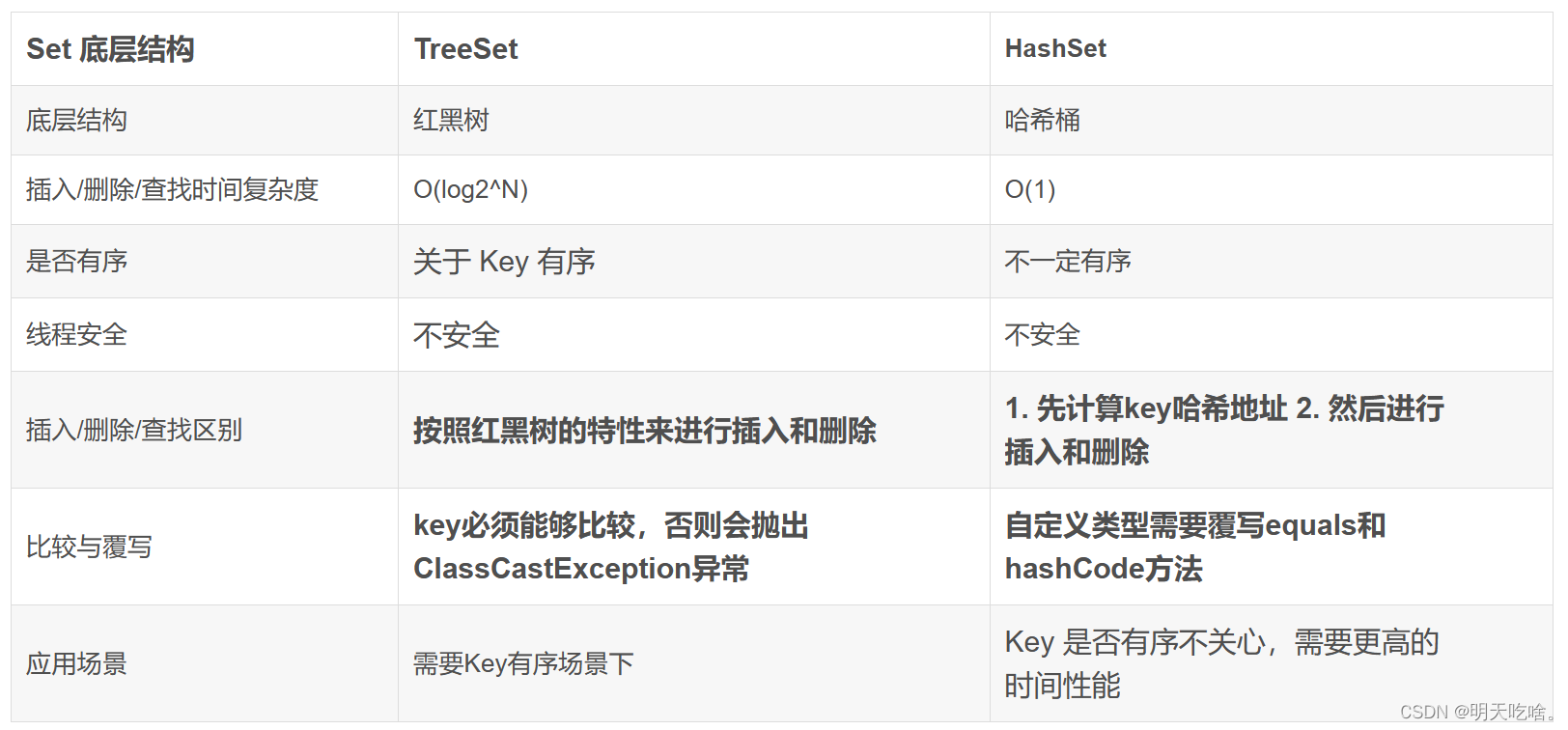
和上面的Map一样,我们先介绍下TreeSet和HashSet的区别:
3.1 Set相关方法的介绍
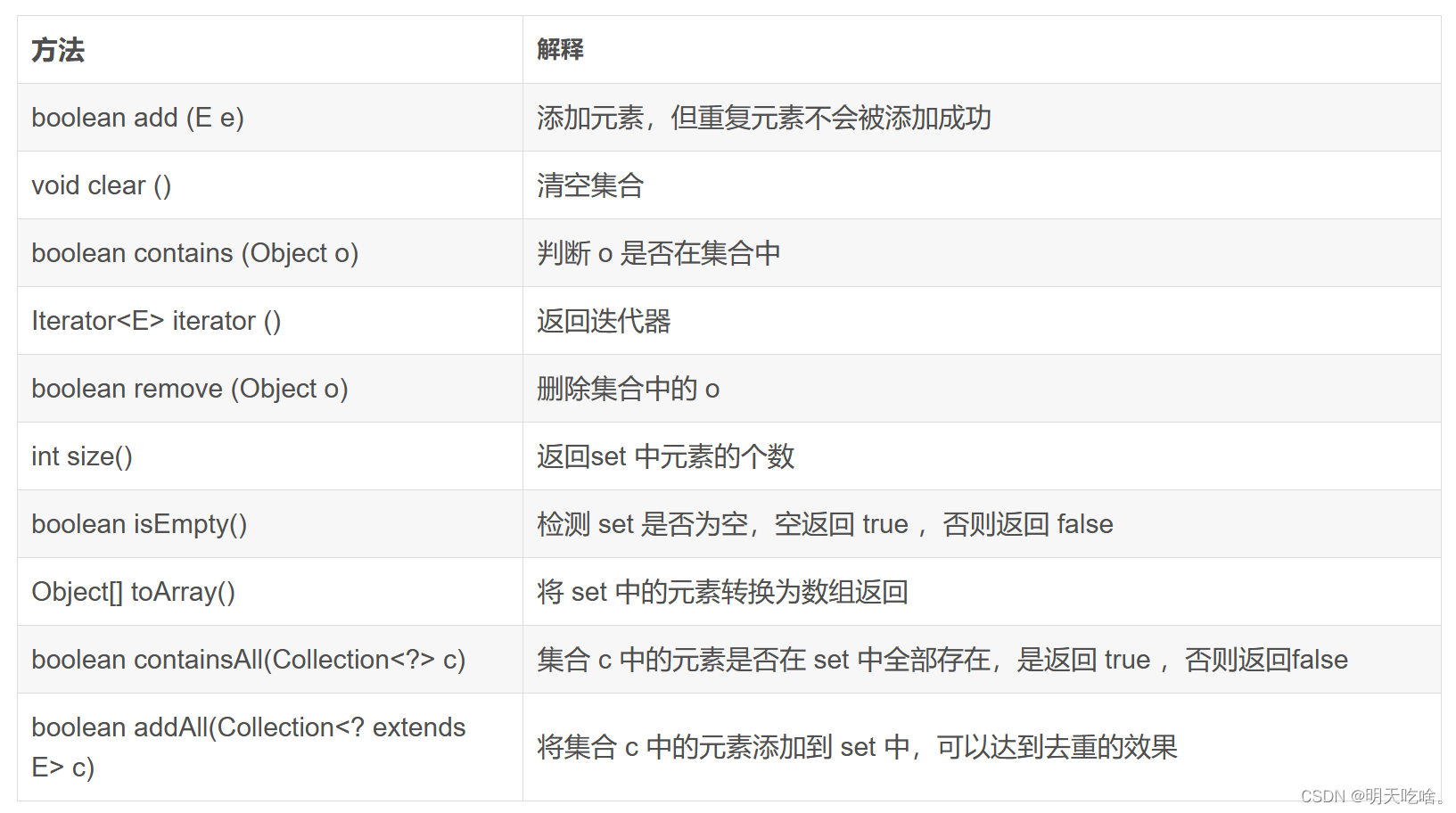
代码实现(感兴趣的下去可以自行实践没提到的方法):
import java.util.Map;
import java.util.Set;
import java.util.TreeMap;
public class Test {
public static void main(String[] args) {
Set<String> set = new TreeSet<>();
set.add("卡莎");
set.add("诺手");
set.add("剑魔");
set.add("吸血鬼");
System.out.println(set.contains("格温"));
set.remove("卡莎");
System.out.println(set);
}
4.哈希表
4.1 哈希表的概念
在之前的学习中,我们发现在插入或搜索元素的时候,都是需要经过比较的,那么有没有一种数据结构,不需要进行任何比较就可以找到我们要插入或搜索的元素呢?
如果有一种方法,它的每个元素与存储位置形成一一映射的关系,我们进行插入或搜索的时候,根据映射关系就可以直接找到要插入或搜索的位置了。
这种方法就叫哈希(散列)方法,其使用的转换函数就叫哈希(散列)函数,而其产生的数据结构就叫哈希表或散列表。
我们上面的HashMap和HashSet的底层哈希桶就是使用的这个结构。其插入和搜索的时间复杂度就是O(1)。
例如下面的数据集合{4,6,8,5,7}
哈希函数设置为 hash(key) = key % capacity, capacity为存储元素底层空间的大小
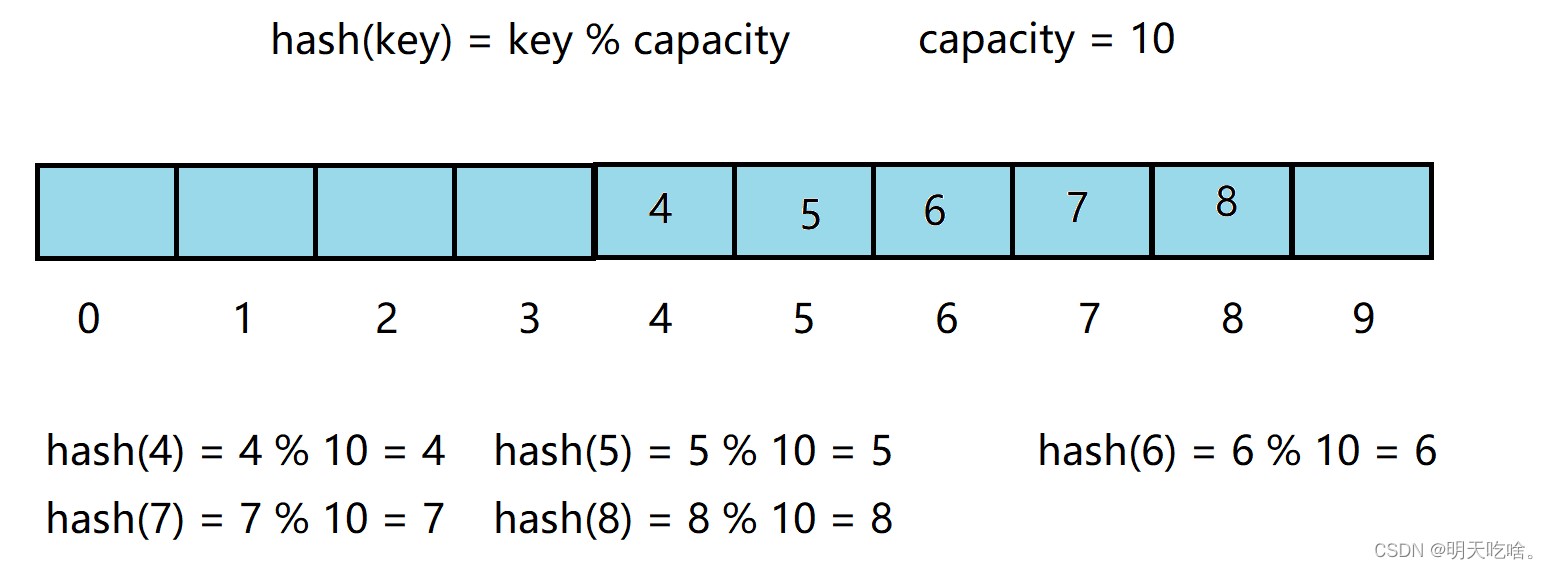
用该方法进行插入和搜索操作不用进行多次的比较,因此效率比较高.
4.2 哈希冲突
对于两个不同的元素K1和K2,他们的key值不同,但可能通过哈希函数求的值可能相同,比如上述例子中我们再添加一个14,hash(14) = 14% 10 = 4,按理也应该放到4下标的,但已经有元素4了,此时就发生冲突了,我们把这种不同的关键字通过hash函数求出相同的哈希地址的行为称为哈希冲突或哈希碰撞.
4.3 冲突避免——设计合理的哈希函数
引起哈希冲突的一个可能原因就是:哈希函数设置的不够合理。
常见的哈希函数:
1. 直接定址法:(常用)
取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B 优点:简单、均匀 缺点:需要事先知道关键字的分布情况 使用场景:适合查找比较小且连续的情况
2. 除留余数法:(常用)
设散列表的最大长度为m,取一个不大于m,最接近或者等于m的质数p作为除数,按照哈希函数:hash(Key) = Key % 9 ,计算关键字的哈希地址。
剩下几种不常见,这里就不介绍了,大家如果感兴趣可以去查找其他资料。
4.4 冲突避免——负载因子的调节(重点)
散列表的负载因子定义为:α = 表中元素个数 / 表的长度
通过上述式子可以看出,当散列表没有扩容的时候是定长的,此时,α的大小与表中元素个数成正相关,当表中元素个数越多,α越大,发生冲突的概率就越大,此时我们就应该调节负载因子的大小,降低冲突率。在Java系统库中,限制了负载因子的大小为0.75,当超过这个值,由于元素的个数我们是无法限制的,所以我们就该对散列表进行扩容来调节负载因子的大小了。
4.5 冲突解决——开散列/哈希桶
解决哈希冲突的两种常见方法有:开散列和闭散列。
这里我们只介绍开散列的方法。
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
下面我们画图解释:
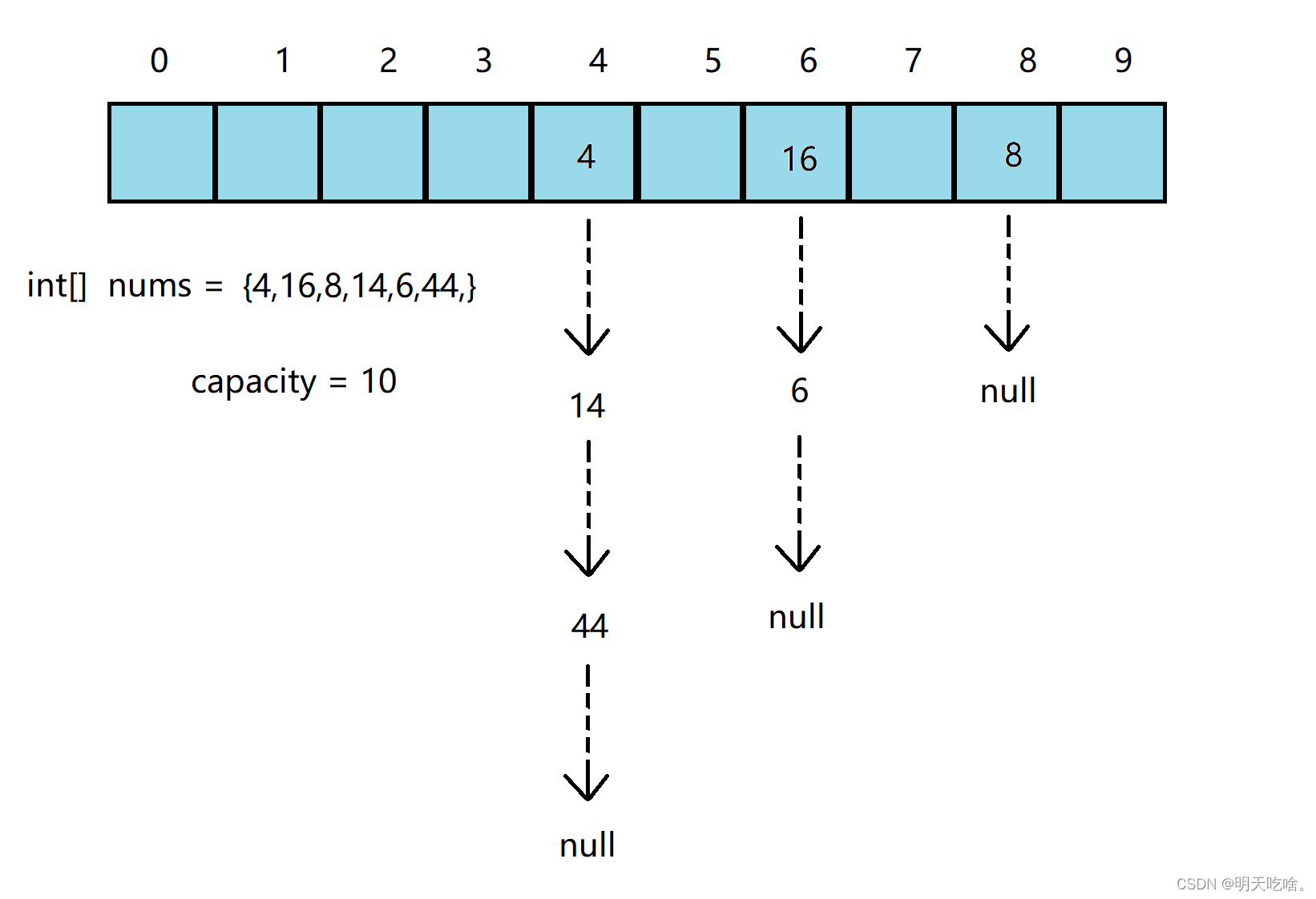
通俗理解就是,开散列的结构就是由数组加链表的结构,我们将链表的头节点放在哈希表中。我们将发生冲突的元素都插入在哈希地址处链表的后面。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









