










大数据技术AI
Flink/Spark/Hadoop/数仓,数据分析、面试,源码解读等干货学习资料
129篇原创内容
公众号
版本分布
-
centos:centos8
-
hudi:0.10.1
-
spark:3.1.3
-
scala:2.12
1、Maven安装
1.1 手动安装
(1)下载maven
https://maven.apache.org/download.cgi

(2)上传解压maven
tar -zxvf apache-maven-3.6.1-bin.tar.gz -C /bigdata/
(3)添加环境变量到/etc/profile中
#MAVEN_HOME
export MAVEN_HOME=/bigdata/apache-maven-3.6.1
export PATH=$PATH:$MAVEN_HOME/bin
source /etc/profile
(4)测试安装结果
duo@bigdata100:~$ mvn -v
Apache Maven 3.6.3
Maven home: /bigdata/apache-maven-3.6.1
Java version: 1.8.0_321, vendor: Oracle Corporation, runtime: /bigdata/module/jdk1.8.0_321/jre
Default locale: en_US, platform encoding: UTF-8
OS name: "linux", version: "5.13.0-44-generic", arch: "aarch64", family: "unix"
(5)修改setting.xml,指定为阿里云
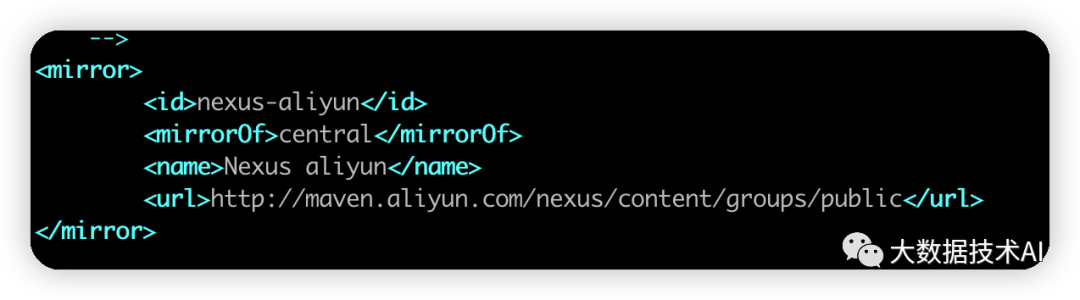
### 1.2 apt或yum安装
apt install maven
2、安装git
-------
yum install gitduo@bigdata100:~$ git --versiongit version 2.25.1
3、构建hudi
--------
### 3.1 通过国内镜像拉取源码
git clone --branch release-0.10.1 https://gitee.com/apache/Hudi.git
3.2 修改pom.xml
root@bigdata100:~# vim Hudi/pom.xml
nexus-aliyun
nexus-aliyun
http://maven.aliyun.com/nexus/content/groups/public/
true
false
### 3.3 构建
不同spark版本的编译
| Maven build options | Expected Spark bundle jar name | Notes |
| :-- | :-- | :-- |
| (empty) | hudi-spark-bundle\_2.11 (legacy bundle name) | For Spark 2.4.4 and Scala 2.11 (default options) |
| `-Dspark2.4` | hudi-spark2.4-bundle\_2.11 | For Spark 2.4.4 and Scala 2.11 (same as default) |
| `-Dspark2.4 -Dscala-2.12` | hudi-spark2.4-bundle\_2.12 | For Spark 2.4.4 and Scala 2.12 |
| `-Dspark3.1 -Dscala-2.12` | hudi-spark3.1-bundle\_2.12 | For Spark 3.1.x and Scala 2.12 |
| `-Dspark3.2 -Dscala-2.12` | hudi-spark3.2-bundle\_2.12 | For Spark 3.2.x and Scala 2.12 |
| `-Dspark3` | hudi-spark3-bundle\_2.12 (legacy bundle name) | For Spark 3.2.x and Scala 2.12 |
| `-Dscala-2.12` | hudi-spark-bundle\_2.12 (legacy bundle name) | For Spark 2.4.4 and Scala 2.12 |
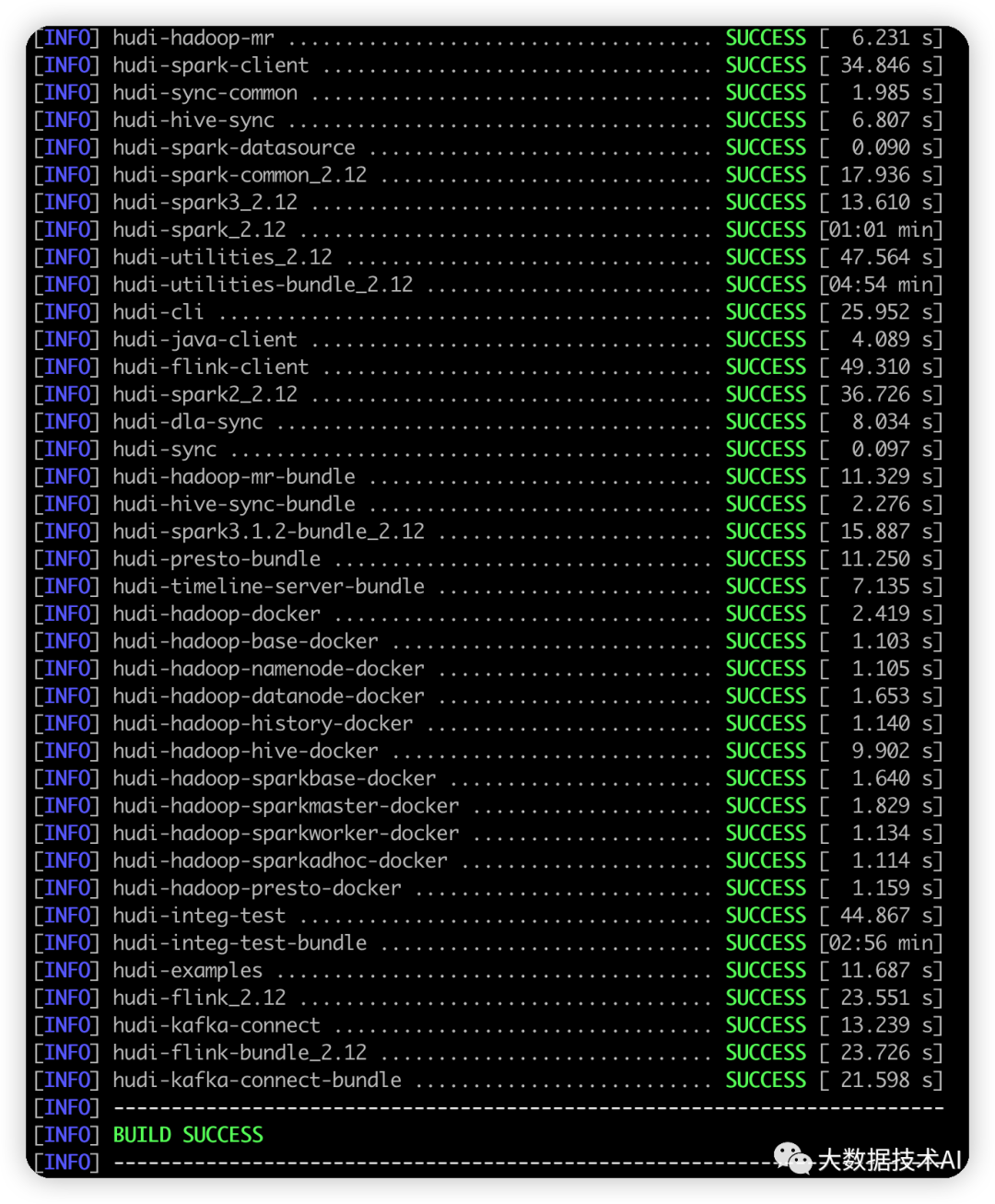
mvn clean package -DskipTests -Dspark3 -Dscala-2.12
耗时周末一天,终于编译成功
### 4、问题总结
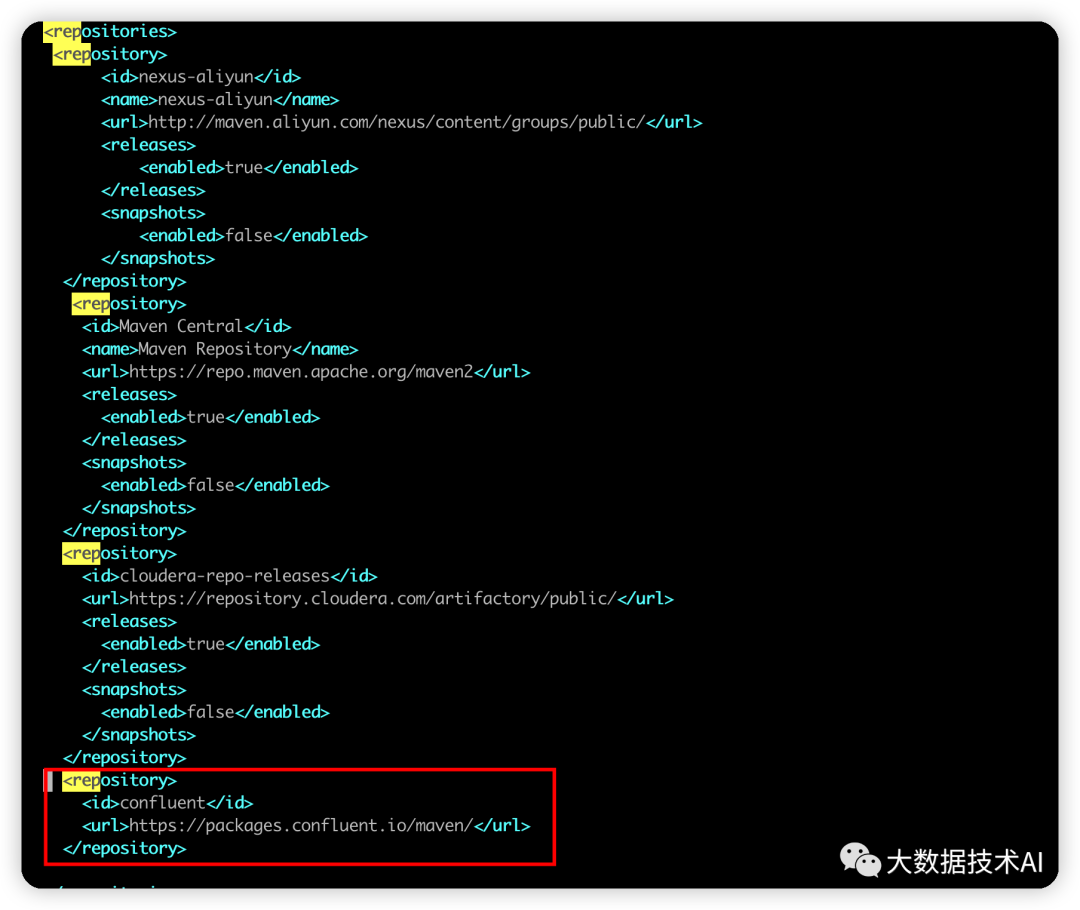
#### **Q1:dependencies at io.confluent:kafka-avro-serializer:jar**
ERROR] Failed to execute goal on project hudi-utilities_2.12: Could not resolve dependencies for project org.apache.hudi:hudi-utilities_2.12:jar:0.10.1: Failed to collect dependencies at io.confluent:kafka-avro-serializer:jar:5.3.4: Failed to read artifact descriptor for io.confluent:kafka-avro-serializer:jar:5.3.4: Could not transfer artifact io.confluent:kafka-avro-serializer:pom:5.3.4 from/to maven-default-http-blocker (http://0.0.0.0/): Blocked mirror for repositories: [nexus-aliyun (http://maven.aliyun.com/nexus/content/groups/public/, default, releases)] -> [Help 1]
解决:将原来的mirror也打开,阿里仓库没有
Starting from versions 0.11, Hudi no longer requires spark-avro to be specified using --packages
#### **Q2:The goal you specified requires a project to execute but there is no POM in this directory (/root). Please verify you invoked Maven from the correct directory**
解决:切换到有pom的文件夹下才能执行















 1109
1109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









