









大数据配置(hadoop的三种集群方式)
Hadoop的运行模式分为3种:本地运行模式,伪分布运行模式,集群运行模式,前2种都是在同一台机器上进行的操作,相应概念如下:
(楼主 建立了一个集群 主机 node3 从机分别是node1 node2)
1、独立模式即本地运行模式(standalone或local mode)无需运行任何守护进程(daemon),所有程序都在单个JVM上执行。由于在本机模式下测试和调试MapReduce程序较为方便,因此,这种模式适宜用在开发阶段。
单机模式是Hadoop的默认模式。当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选择了最小配置。在这种默认模式下所有3个XML文件均为空。当配置文件为空时,Hadoop会完全运行在本地。因为不需要与其他节点交互,单机模式就不使用HDFS,也不加载任何Hadoop的守护进程。该模式主要用于开发调试MapReduce程序的应用逻辑。
2、伪分布运行模式
伪分布:如果Hadoop对应的Java进程都运行在一个物理机器上,称为伪分布运行模式。这台机器的master是它,salver也是它,namenode是它,datenode也是它,jobtraker是它,tasktraker也是他。总之就是一台机器起到了多功能的作用。
配置:
(1)hadoop-env.sh
更改java_home 变量(上一篇博客中已经提到,尽量把-env.sh的文件中的java_home路径改为绝对路径)

(2)core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop0:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/hadoop_${user.name}</value>
</property>
</configuration>
(3)hdfs-site.xml
<configuration>
2 <property>
3 <name>dfs.replication</name>
4 <value>1</value> //实验环境,备份设置为1
5 </property>
6 <property>
7 <name>dfs.permissions</name>
8 <value>false</value> //实验环境,不设置权限
9 </property>
10 </configuration>
(4)vim mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop0:9001</value>
</property>
</configuration>
配置结束以后,格式化文件系统
hadoop namenode -format
在启动hadoop
start-all.sh
使用jps命令,查看是否已经启动成功
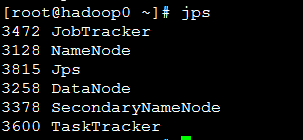
或者在浏览器中验证,打开浏览器
http://loclahost:50030(mapreduce的web页面)
http://localhost:50070(hdfs的web页面)
3、集群模式
如果Hadoop对应的Java进程运行在多台物理机器上,称为集群模式.
Hadoop的配置文件:
conf/hadoop-env.sh 配置JAVA_HOME
core-site.xml 配置HDFS节点名称和地址
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://node3:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>./hadoop_data</value>
</property>
</configuration>
hdfs-site.xml 配置HDFS存储目录,复制数量
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
mapred-site.xml 配置mapreduce的jobtracker地址
指定主机和jobtracker
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>node3:(根据自己的hadoop的名字):9001</value>
</property>
</configuration>
配置slaves
node1
node2
主机配置完成以后,把刚才的配置在从机中在配置一遍(你也可以直接把hadoop配置好的包,复制直接传输过去)namenode -format
在satrt-all.sh
启动以后,在windows中的浏览器上直接输上主机名:端口 楼主的192.168.46.7:8088

总结对比:在三种集群搭建成功以后,楼主进行了对比
主要在伪分布和完全分布的比较:
在配置文件方面hdfs-site.xml中这一句的区别
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
伪分布式主机即当master又当slaver ,所以设置为1
完全分布式集群搭建根据从机的多少来确定 有几台从机就设置为几 (楼主使用的2台,故设置为2,系统默认的是3,这点需要注意)
文件的配置根据需求,参见《hadoop实战》陈嘉恒,讲的挺详细的,或者参见官网














 576
576











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









