







对于数据库,为什么要建索引?走索引查询为什么比较快?
索引将数据查询由随机IO 变成顺序IO
什么是回表操作?
表结构及已有索引如下图:
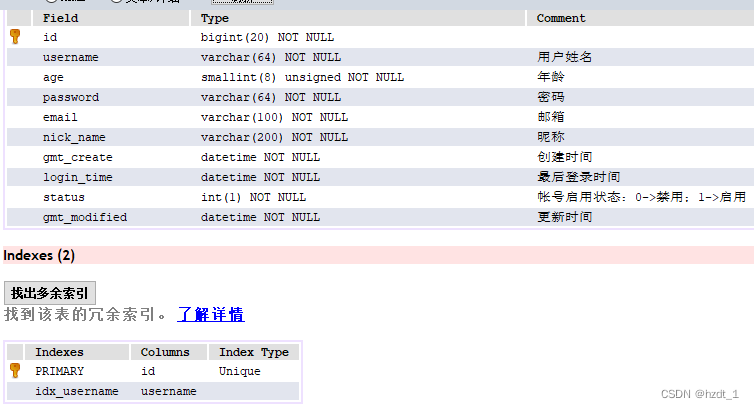
根据现有的索引执行以下sql语句,会出现回表操作吗?
SELECT username, age FROM ums_member WHERE username="lisi";
目前该表已有2个索引:
主键索引: id
普通索引:username
主键索引和普通索引都是B+树索引
主键索引叶子节点存储主键id对应的每行记录数据;即:主键索引 = 主键 + 行记录数据
普通索引叶子节点存储的是主键id的值;即:普通索引 = 索引列 + 主键值;
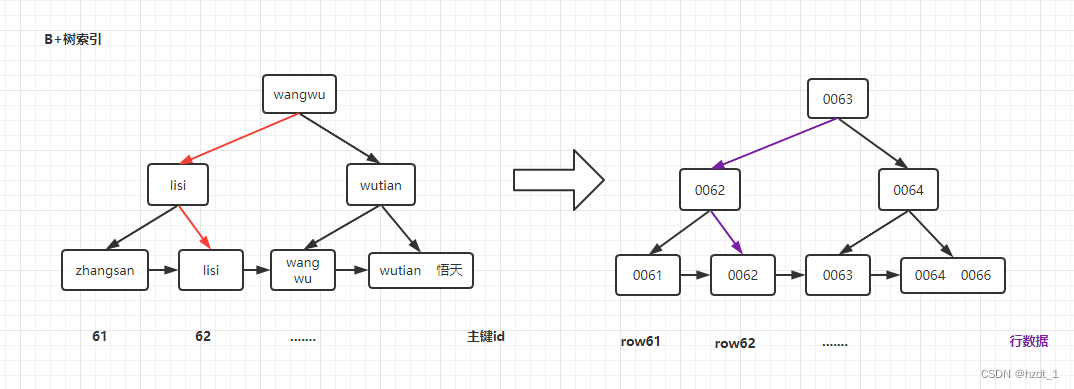
sql语句查询username 和age 两个字段;走普通索引username; 由于普通索引中只有username:主键id信息;所以要拿到age字段的值;必须再根据主键id走主键索引获取行记录信息,从而拿到age字段值;这就是回表操作;走两次B+树遍历;
回表: 走普通索引时;普通索引包含信息无法满足查询字段信息,此时就会走回表操作;
流程如下图:
sql性能优化:尽量不走回表操作;所以对开始的sql语句的优化是创建(username, age)组合索引;
Alter table ums_member add index idx_username_age (username, age);
此时查询username和age字段信息;可以走一个组合索引拿到2个字段信息;即索引字段中包含了全部查询字段;不用走回表操作;这也是我们通常所说的覆盖索引。
覆盖索引:
- 对于普通索引:只查询主键、索引字段时,遍历普通索引后直接返回主键和索引字段信息,无需在进行遍历主键索引。覆盖索引也是普通索引的优化
select id, username from ums_member where username="wufan";
-- username 普通索引列
- 对于组合索引:索引字段中包含了全部查询字段;也回走覆盖索引方式;
SELECT username, age FROM ums_member WHERE username="lisi";
-- 组合索引: (username,age) 包含了查询列;
从执行计划角度:
1、走索引覆盖的查询时,extra列可以看到using index的信息,表示使用了覆盖索引
mysql> explain select id, username from ums_member where username="wufan" \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: ums_member
partitions: NULL
type: ref
possible_keys: idx_username
key: idx_username
key_len: 194
ref: const
rows: 1
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.00 sec)
总结:
站在mysql优化性能考虑,sql查询每一次回表操作会增加一次遍历(主键)B+树操作;对于复杂查询走普通索引+ 多次回表操作性能没有全表扫描性能好时;mysql优化器将会直接走全表扫描;这也是索引失效的一个重要因素;索引覆盖可以避免回表操作;对于sql查询优化是一个很好的切入点;实际查询中应该尽量避免select * 等多余字段查询!















 718
718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









