







1 脑裂
许多容错系统使用一个单主节点来决定主副本。
- MapReduce:由单主节点控制计算复制。
- GFS:主备复制数据,并由单主节点确定主拷贝的位置。
- VMware FT:主虚机和备份虚机之间复制指令,需要单点的Test-and-Set服务确认主虚机。
这三个例子都是一个多副本系统,系统容错的关键点转移到这个主节点上。
使用单主节点,我们则需要避免脑裂(Split-Brain)问题。脑裂指的是在多副本系统中,因网络分裂导致多个副本都认为自己是主副本,从而出现数据不一致或功能冲突的问题。
这里有两种解决方案
- 构建高可靠网络:如果网络完全不出现故障,客户端无法访问的服务器即被认为是关机,这样可以排除脑裂的可能。但需要大量资金和控制物理环境。
- 人工解决问题:客户端默认等待两个服务器的响应。如果只收到一个响应,需人工检查两个服务器的状态。人工检查虽然能解决问题,但可能不够及时。
2 过半票决
在构建能自动恢复,同时又避免脑裂的多副本系统时,关键点在于过半票决(Majority Vote),这是Raft论文中提出的一个基本概念,即在一个多副本系统中,任何操作必须得到超过一半的服务器同意才能完成。为了有效使用过半票决,服务器数量应该是奇数。这样在出现网络分区时,一个分区无法拥有超过半数的服务器,从而避免脑裂。对于过半票决,可以用下面这个通用方程来描述:
如果系统有 2 × F + 1 2\times F+1 2×F+1个服务器,那么系统最多可以接受 F F F个服务器出现故障。
Raft协议依赖过半票决来进行Leader选举和日志提交。每个操作需要过半的服务器批准。任何两个操作的过半服务器至少有一个重叠。
- Leader选举:新选出的Leader必然获得过半服务器的选票,而这些服务器与旧Leader的服务器有重叠,因此知道旧Leader的任期号。
- 日志一致性:新Leader的过半服务器包含了旧Leader的操作,确保日志一致性。
3 Raft概述
Raft协议作为库(Library)存在于服务中,每个Raft副本包含应用程序代码和Raft库。应用程序代码处理RPC或其他客户端请求,Raft库负责同步多副本之间的操作。
操作流程如下:
-
客户端请求:客户端发送请求(如Put或Get)到Raft集群的Leader节点。
-
请求处理:
- Raft层:Leader节点将请求操作传递给Raft层,要求将操作写入日志。Raft节点之间的交互确保操作被过半节点复制。当Leader节点确认过半副本都有操作的拷贝后,通知应用程序层执行操作。
- 应用程序层:仅在收到Raft层的确认后才执行操作(更新数据库或读取值)。
-
操作提交:
- Raft层:通知应用程序层,操作已在过半副本中复制完成,可以执行。
- 应用程序层:执行操作并最终返回结果给客户端。
为何不需要拷贝到所有节点?
为了容错,系统只需过半的副本即可完成操作,这样即使部分服务器故障,系统仍能继续工作。
除了Leader节点,其他节点的应用程序层会有什么样的动作?
在操作在Leader节点提交后,其他副本的Raft层将操作传递给本地应用程序层,确保所有副本的操作序列一致,状态最终保持一致。
4 日志
如下图所示,展示了Raft协议在处理客户端请求时的消息交互流程,AE代表AppendEntries RPC。
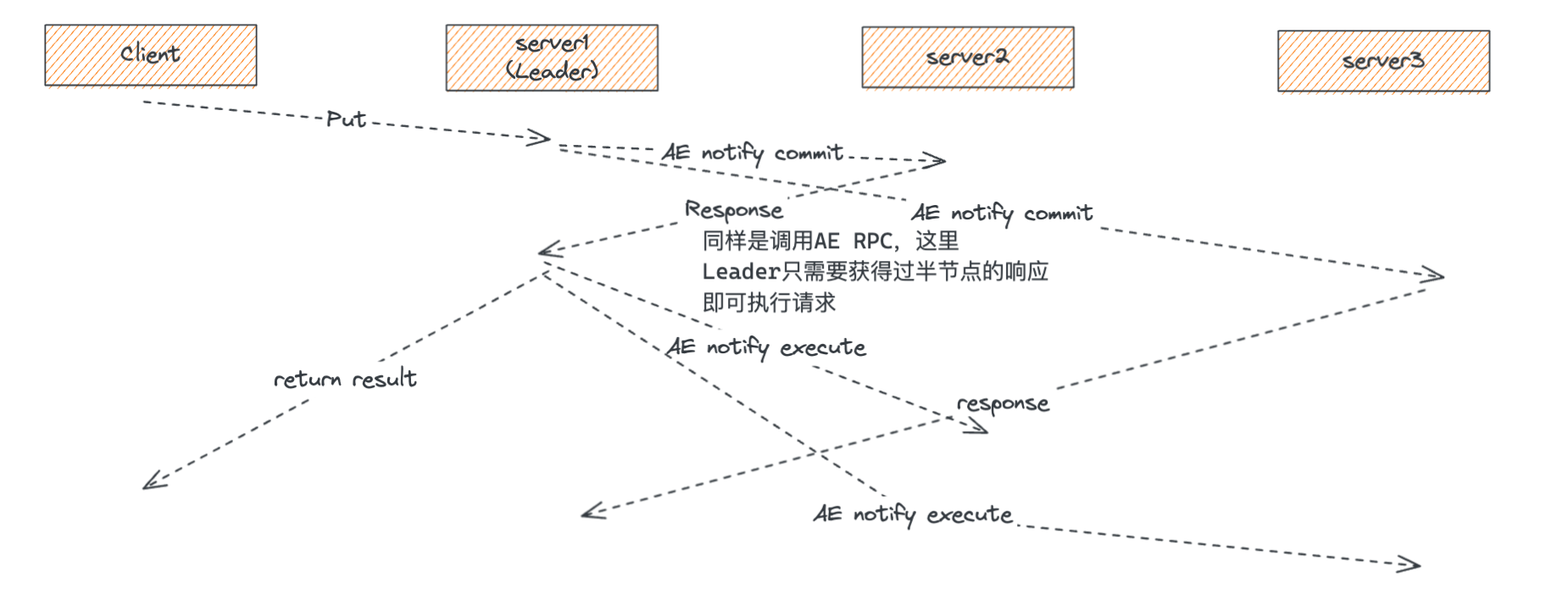
- 客户端请求:客户端发送一个Put请求到当前Raft集群的Leader节点(S1)。
- Leader节点处理:S1的Raft层发送AppendEntries RPC到其他两个副本节点(S2、S3)。S1等待至少一个Follower节点(S2或S3)的响应以达到过半节点的响应。
- Follower节点响应:S2、S3接收AppendEntries RPC并返回响应给Leader(S1)。S1只需等待一个Follower节点的正确响应即可。
- 操作提交:一旦S1收到过半节点的正确响应(包括自己),S1执行客户端请求并返回结果给客户端。
- 通知其他副本:S2、S3在收到AppendEntries后不确定请求是否被Leader提交。Leader需要在下一次AppendEntries或心跳消息中通知其他副本请求已被commit。其他副本收到此消息后,更新本地状态,执行已提交的请求。
Raft系统对Log的关注有几个关键原因:
- 操作排序:所有副本不仅要执行相同的操作,还要以相同的顺序执行这些操作。Log由编号的槽位(类似一个数组)组成,槽位的数字表示了Leader选择的顺序。
- 临时存储:Follower收到操作但还未执行时,需要将操作存放在某处,直到收到Leader发送的commit号。Log就是这个临时存储的地方。Follower在操作commit前不确定这些操作是否会被执行,有时这些操作可能会被丢弃。
- 重传机制:Leader记录操作在其Log中,因为这些操作可能需要重传给Follower。如果Follower短时间离线或丢失了一些消息,Leader需要能够向Follower重传丢失的Log消息。即使是已commit的请求,为了向丢失相应操作的副本重传,Leader也需要在Log中存储这些操作。
- 状态恢复:Log帮助重启的服务器恢复状态。故障重启后的服务器使用存储在磁盘中的Log,从头执行其中的操作,重建故障前的状态并继续运行。每个Raft节点都需要将Log写入磁盘,确保故障重启后Log能保留,帮助服务器恢复状态。
5 应用层接口
在Raft集群中,每一个副本上,应用层(如key-value数据库)和Raft层之间主要有两个接口。这两个接口分别用于转发客户端请求给Raft层,以及Raft层通知应用层请求已被commit。
第一个接口是key-value层用来转发客户端请求的接口—Start函数。当客户端发送请求给key-value层时,key-value层会将请求转发给Raft层,并告诉Raft层将请求存放在Log中。Start函数只接收一个参数,即客户端请求。Start函数的返回值包括:
- 请求在Log中的位置(index)
- 当前的任期号(term number)
- 其他信息
第二个接口是applyCh channel,以Go channel中的一条消息形式存在。Raft层会通过发送ApplyMsg消息给applyCh来通知key-value层哪些请求已经commit,key-value层读取这些消息。ApplyMsg包含:
- 请求(command)
- 对应的Log位置(index)
所有的副本都会收到ApplyMsg消息,知道应该执行请求并应用在本地状态中。Leader需要知道ApplyMsg中的请求对应哪个客户端请求,以便响应客户端请求。
6 Leader 选举
引入Leader的原因:
-
有Leader系统效率更高,因为请求只需一轮消息即可获得过半认可。
-
无Leader系统需要一轮消息确认临时Leader,再一轮确认请求,效率较低。
Raft使用任期号(term number)区分不同的Leader。每个任期最多有一个Leader。Followers只需知道当前的任期号。
Leader选举过程如下:
- 如果Follower在选举定时器时间内未收到Leader消息,会认为Leader下线,开始选举。
- 当前节点增加任期号,发起选举。
- 节点发送
RequestVoteRPC给其他节点,自己投票给自己。 - 节点需要获得过半服务器的认可投票才能成为Leader。
任期内每个节点只投一次票,就不可能有两个候选人同时获得过半的选票,确保每个任期最多一个Leader。成功当选后,Leader立即发送AppendEntries消息(心跳)通知其他节点自己当选。
如果Leader在网络分区中少数服务器内,无法获得过半认可,不能commit请求。旧Leader在小分区内运行,但不能执行客户端请求,只能发送心跳。
有没有可能出现极端的情况,导致单向的网络出现故障,进而使得Raft系统不能工作?
如果当前Leader的网络单边出现故障,Leader可以发出心跳,但是又不能收到任何客户端请求。它发出的心跳被送达了,因为它的出方向网络是正常的,那么它的心跳会抑制其他服务器开始一次新的选举。但是它的入方向网络是故障的,这会阻止它接收或者执行任何客户端请求。这个场景是Raft并没有考虑的众多极端的网络故障场景之一。
可以通过一个双向的心跳机制来解决。即Leader发送心跳,Follower要响应这个心跳,如果Leader没有收到响应,则会决定卸任。
所有Raft节点收到任何一条AppendEntries消息都会重置其选举定时器。只要Leader以合理的速率发送心跳或其他AppendEntries消息,Followers就会重置选举定时器,阻止其他节点成为候选人。在没有网络故障或丢包的情况下,连续的心跳消息会防止新的选举发生。
如果出现服务器故障或网络问题或者分割选票(多个候选人几乎同时竞选,选票分散),可能导致无法凑齐过半服务器,无法选出Leader,这次选举就失败了。
Raft不能完全避免分割选票问题,但可以大大降低发生概率。通过随机选择选举定时器的超时时间,减少同步超时的概率。
超时时间设置:
- 下限:至少大于Leader的心跳间隔,多次心跳间隔更好(例如3次心跳间隔)。
- 上限:远小于服务器两次故障之间的平均时间。
- 时间差:足够大以确保第一个超时节点能够完成一轮选举,至少需要大于发送一条RPC的往返时间。
lab tip 每一次一个节点重置自己的选举定时器时,都需要重新选择一个随机的超时时间。避免服务器会以极小的概率选择相同的随机超时时间,那么会永远处于分割选票的场景中
7 日志恢复
Leader正常运行时,Follower必须同意并接收Leader的日志。但Leader故障后,新Leader需要整理各副本可能不一致的日志。
新Leader会发送包含prevLogIndex和prevLogTerm的AppendEntries RPC。
Follower检查本地日志是否匹配:
- 不匹配:拒绝AppendEntries,Leader减少nextIndex并重试。
- 匹配:接受AppendEntries,更新本地日志。
为什么Raft系统可以安全的删除不一致的日志?
如果日志条目未存在于过半服务器中,旧Leader不可能commit该条目,也就不可能将它应用到应用程序的状态中,安全删除无影响。并且如果客户端未收到回复,将重发请求,确保请求最终被处理。
为什么总是删除Followers的Log的结尾部分?
Leader具有完整的Log记录,可以在任何需要的时候填充Followers的日志。如果系统刚启动,或发生反常情况,Leader能够从第一条记录开始恢复Followers的日志,因为它有所有必要的信息。
8 选举约束
为了保证系统的正确性,并非任意节点都可以成为Leader。不是说第一个选举定时器超时了并触发选举的节点,就一定是Leader。Raft对于谁可以成为Leader,存在一些限制。限制条件如下:
- 候选人最后一条Log条目的任期号大于本地最后一条Log条目的任期号;
- 或者,候选人最后一条Log条目的任期号等于本地最后一条Log条目的任期号,且候选人的Log记录长度大于等于本地Log记录长度。
所以Raft更倾向于选择拥有更高任期号记录的候选人,确保系统一致性。
9 快速恢复
基于上述介绍,Leader现行机制是每次回退一条Log条目来解决日志冲突。如果Follower长时间关机,错过大量AppendEntries消息。Leader重启后需逐条RPC回退Log条目,耗时较长。
Raft论文中提供了一个快速恢复方法。Follower返回足够信息给Leader,使Leader能按任期(Term)为单位回退,而非逐条回退。Follower拒绝AppendEntries消息时,返回以下3个信息:
- XTerm:Follower中与Leader冲突的Log条目的任期号。
- XIndex:Follower中,任期号为XTerm的第一条Log条目的槽位号。
- XLen:Follower中空白Log槽位数。
可以使用二分查找等更高效的方法进一步加速。
10 持久化
在Raft协议中,持久化存储(persistence)和非持久化存储(volatile)的区别在于服务器重启时的状态保持。持久化存储确保服务器重启后能够恢复到之前的状态,从而保证服务的连续性和数据的一致性。持久化存储通常使用磁盘或电池供电的RAM来保存数据。
根据Raft论文图2,以下三个数据需要持久化存储:
- Log:保存所有的日志条目,是唯一记录应用程序状态的地方。
- currentTerm:当前的任期号,用于确保每个任期只有一个Leader。
- votedFor:记录当前任期投票给了哪个服务器,用于确保每个任期内只有一个Leader被选举出来。
每当Log、currentTerm或votedFor发生变化时,服务器必须将这些数据写入磁盘以确保其持久化。这可以通过调用系统的write和fsync函数来实现,其中fsync确保数据在磁盘上安全存储。
为了提高性能,可以采用批量操作的方法。例如,当Leader接收到多个客户端请求时,可以累积这些请求,然后一次性持久化存储多个Log条目,减少持久化存储的次数。
11 日志快照
在Raft一致性算法中,日志条目(Log entries)会随着系统运行时间的延长而不断增加。这会带来两个问题:
- 存储空间:日志条目数量过多,会占用大量的内存和磁盘空间。
- 系统重启:如果服务器重启,需要重放所有日志条目来恢复状态,耗时较长。
为了应对上述问题,Raft引入了快照机制。快照是对应用程序状态的压缩表示。通过创建快照,可以丢弃部分已应用的日志条目,减少存储空间,并加快重启时的恢复过程。
Raft会将应用程序创建的快照存储在磁盘上,确保数据的持久性。服务器重启时,Raft会从磁盘读取最近的快照,并将其传递给应用程序,恢复到快照对应的状态。然后,从快照之后的日志条目开始继续恢复。
如果某个Follower的日志比Leader的短,且短于Leader快照的起始位置,那么Leader无法通过发送日志条目来同步Follower的日志。Raft引入了InstallSnapshot RPC。当Follower的日志长度不够时,Leader会发送快照给Follower,然后继续通过AppendEntries RPC发送后续的日志条目。
快照的生成和恢复需要应用程序与Raft组件之间的紧密协同。应用程序负责生成和吸纳快照,Raft负责管理快照和日志条目的持久化存储。Leader可能并发发送多个RPC消息,包括AppendEntries和InstallSnapshot,需要处理可能的乱序和冗余消息。
快照生成是否依赖应用程序
是的,快照生成函数是应用程序的一部分,应用程序负责生成和恢复快照。只有应用程序自己才知道自己的状态(进而能生成快照)。而通过快照反向生成应用程序状态的函数,同样也是依赖应用程序的。
12 课程QA
- Raft 通常用于什么?是否用于实际软件中?
Raft(以及 Paxos)主要用于构建容错的“配置服务”,跟踪在大型部署中的服务器职责分配。这种服务对复制部署尤为重要,可以避免脑裂问题。Raft 还被一些数据库(如 Spanner、CockroachDB)用于数据复制。
有多个实际应用使用 Raft,如 Docker、etcd 和 MongoDB。许多基于 Paxos 的系统(如 Chubby、ZooKeeper)也在实际生产环境中使用。
- Raft 如何与 VMware FT 比较?
Raft 更具容错性,没有单点故障,而 VMware FT 存在一个测试和设置服务器作为单点故障。Raft 用作库集成在应用软件中,而 VMware FT 可用于任何虚拟机。
- Raft 如何防止恶意攻击?
Raft 默认没有防御恶意攻击的机制。实际部署中需要通过防火墙保护,或使用加密验证 Raft 数据包。
- Raft 的“非拜占庭”条件是什么?
Raft 假设服务器要么按协议运行,要么停止运行。拜占庭故障指计算机执行错误操作,这可能导致 Raft 发送不正确的结果。
- Raft 可以在地理分布的数据中心中使用吗?
通常,Raft 部署在单一数据中心。跨数据中心的系统(如 Spanner)更适合无领导协议,以便客户可以与本地副本通信。
- Raft 的日志为何是从 1 开始编号的?
日志从零编号,但第一个条目(索引为 0)具有Term 0,使得初始 AppendEntries RPC 可以包含有效的 PrevLogIndex。
- Raft 的副本优化是什么?
副本优化通过在服务快照时使用 fork(),实现了“写时复制”。操作系统会延迟实际的内存复制,优化了性能。
- 为什么新领导在其任期开始时需要提交一个无操作(no-op)日志条目?
新领导提交无操作日志条目可以确保其日志中所有之前的条目都是已提交的。这是为了防止新领导在自己失败时,前一个领导的日志条目未被提交,从而保持系统一致性。
- 使用心跳机制提供租约(leases)进行只读操作是如何工作的?为什么需要时间同步?
领导者通过在心跳消息中暗示下一段时间内不能选举新领导,从而提供只读操作的租约。为了保证安全,服务器的时钟需要保持同步,确保租约时间的准确性。
- 在 Raft 的配置变更过程中,如何理解旧配置( C old C_\text{old} Cold)到新配置( C new C_\text{new} Cnew)的过渡?
在联合共识阶段( C old,new C_\text{old,new} Cold,new),领导者需要获得旧配置和新配置的多数支持。配置变更日志条目需要同时被旧配置和新配置的多数服务器确认。
- 快照(snapshot)的创建和恢复过程中的数据是否需要压缩?
快照通常会对数据进行压缩,以减少传输和存储成本。压缩方案应根据具体应用的数据类型来选择,如使用 JPEG 压缩图像数据,或使用通用压缩算法如 ZIP。
- 领导者如何决定什么时候向跟随者发送快照?
领导者会在跟随者的
matchIndex小于其日志开始索引时发送快照,以确保跟随者能够赶上最新的日志状态。
- 在 Raft 中,添加日志条目是否算作执行操作?
不算。仅当领导者将日志条目标记为已提交后,服务器才会执行日志条目中的操作。执行操作指的是将日志条目交给实际服务进行处理。
















 4058
4058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











