







MIT 6.824 是麻省理工大学的一门研究生课程——Distributed Systems,学习这门课程对于了解分布式系统的构建原理、理解分布式程序的运行、优化分布式程序的运行环境会有很大的帮助。课程内容涵盖:分布式、容错、多副本、一致性等议题,附带了 4 个大的实验 Lab 并配套了相关的测试用例,需要基于 Go 语言完成。Lab 会将课程所讲的知识进行实践、贯通,有助于加深我们的理解和记忆。
做前准备
网上对于本课程 Lab 的实现很多,但是大部分都是上来就讲原理和代码,很少有提到如何从头开始,而第一步往往是最难的。下面是一些准备工作和注意事项:
- 首先,这门课程的 Lab 是完全用 Go 写的,Lecture 也会时不时的讲到 Go 代码,所以需要提前熟悉 Go 的一些基础知识。语言只是一个工具,不必望而却步,只要之前能熟练使用 Java、C++等任何一门编程语言的都可以很快上手 Go,对于完成这门课程足够用了。
- MIT 6.824 课程之所以很出名,原因之一就是其主讲人是 Robert Morris 教授,这是一个传奇大佬,课讲得很好。但似乎 2020 年以后他就不讲这门课了,所以我听的就是他的 2020 年课程,B 站资源:2020 MIT 6.824 分布式系统_哔哩哔哩_bilibili,目前网上免费资源大部分都是机翻字幕,有一些人工翻译的但并不完全。有个网站 https://www.simtoco.com/ 可以付费购买全部翻译课程,质量挺不错的。
- 关于 Lab 资源,我做的是 2022 年的版本,因为 2020 年项目的 Go 版本有些落后,不过其实都无所谓,每一年的 Lab 内容基本上是一样的。网址:6.824 Home Page: Spring 2022 (mit.edu)
- 可以先把项目 clone 下来(在 Lab 1 页面的开头有介绍),这门课程要求学习者不得把自己的仓库公开,以免出现作弊情况,所以如果要 push 到 GitHub 上的话记得把仓库设为私有。
- 接下来就可以开始先看 Lecture 了,总共有 20 个 Lec,每个 Lec 前一般都会分配一篇论文阅读(在 Schedule 页面),尽量先读过一遍。其实看完第一课就可以做 Lab 1 了,实现一个简易的分布式 MapReduce 只需要使用 RPC 和一定的容错(虽然并不容易),用不到多副本、一致性等内容。Lab 1 更像是一次牛刀小试,Lab 2~4 才会用到课程所授的大部分知识。
每个 Lab 提供了一些框架性的代码,需要自己编写关键代码,然后通过测试。具体需要在哪里动笔,课程网页都提供了详细的说明。比如 Lab 1,他已经写好了一个串行的 MapReduce 逻辑,提供了用于 word count 的 Map 和 Reduce 函数。我们先按照指南进行测试,看是否能输出正确结果,如果可以的话就开始着手写分布式 MapReduce 了(在 mr/ 目录下的三个文件中)。
MapReduce 原理
通过阅读论文,我们可以知道 MapReduce 的作者是如何设计这个模型的:
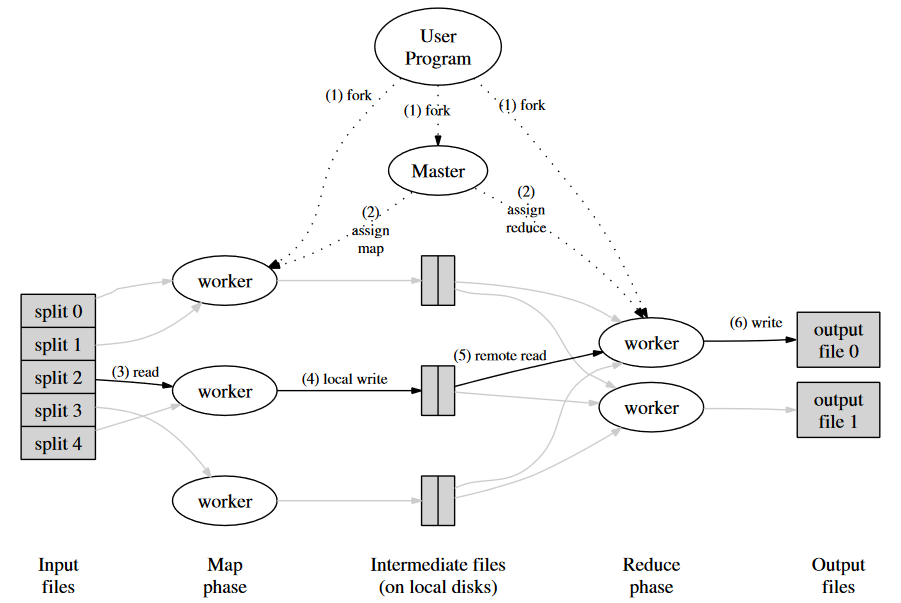
MapReduce 执行过程
- 用户程序中的 MapReduce 库(Client 端)首先将输入文件分割为 M 块,然后在集群上启动许多该程序的副本;
- 其中一个副本是 master,其余的是 worker。总共有 M 个 map 任务和 R 个 reduce 任务需要 master 挑选一个空闲的 worker 进行分配;
- 分配了 map 任务的 worker 读取相应输入 split 的内容。它从输入数据中解析键/值对,并将每对传递给用户定义的 map 函数。 map 函数生成的中间键/值对缓冲在内存中;
- 定期将键值对写入本地磁盘,并通过分区函数将其分为 R 个区域。这些键值在本地磁盘上的位置被传回 master,主节点负责将这些位置转发给 reduce 工作节点;
- 当一个 reduce worker 被通知位置后,通过 RPC 去读取 map workers 上的键值对,(并排序);
- reduce worker 遍历所有的已排序键值对,将唯一的键和值集合传递给用户的 reduce 函数,函数输出到最终文件(最多 R 个);
- 当所有的 reduce 完成任务后,master 唤醒(通知)用户程序。
整体流程还是比较清晰的,但是上述内容仅仅是一个逻辑模型,具体如何进行实现还是需要考虑很多问题的,并且与逻辑模型可能会有一些出入。
需要考虑的问题
要真正实现 MapReduce,搞清以下几个问题很重要:
1 . Master 和 Worker 是何时初始化的?在初始化时各自接收了哪些参数?
假设集群中每个机器运行一个 Master 或 Worker,这个概念并不是属于某个机器的,它只是这个机器上运行的一个进程。Master 和 Worker 是在用户向集群提交某次计算任务后才初始化的,用户提交的任务内容包括:输入文件路径、Map 函数、Reduce 函数。初始化的动作是由论文中提到的 user program 调用的 MapReduce 库 也就是整体框架进行的。
一般来说,MapReduce 系统的运行需要一个分布式文件系统的支持(如 HDFS),输入、输出文件均通过该系统的统一接口。
- Master 初始化时接收的参数是:输入文件路径、分区数 R
- Worker 初始化时接收的参数是:Map 函数,Reduce 函数
2. Master 和 Worker 之间如何通信,是后者主动联系前者还是相反?
大概有两种方式:
- 一种是 Worker 启动时向 Master 进行注册, Master 定时向 Worker 发送心跳确认其在线,并在有任务需要分配时主动通知 Worker。这也是论文的做法。
- 另一种是 Worker 不间断地向 Master 发送心跳,Master 接收到心跳时,将任务信息已回应的方式返回给 Worker。
我采用的是第二种做法,也是 Lab 倾向的做法。因为这样不论是 Master 和 Worker 实现起来要简洁一些,Worker 端不需要启动 RPC 服务器,性能也不输第一种。也是由于本 Lab 是运行在单机上的(为了测试方便),且采用了UNIX 域套接字进行进程间通信,所以在横向扩展 Worker 时第二种方式更加方便。
UNIX 域套接字用于在同一台计算机上运行的进程之间的通信。虽然因特网域套接字可用于同一目的,但 UNIX 域套接字的效率更高。UNIX 域套接字仅仅复制数据,它们并不执行协议处理,不需要添加或删除网络报头,无需计算校验和,不要产生顺序号,无需发送确认报文。
3. Master 如何区分不同的 Worker?
Master 区分不同的 Worker 是为了记录任务的分配和执行情况,以便在出现异常时及时处理。
因为本次 Lab 是在一台机器上运行,所以不考虑 Worker 的网络地址。Master 可以通过 ID 来区分 Worker。在首次请求 Task 的时候让 Master 去赋予 Worker 一个全局唯一的 ID,这个 ID 的有效期直到 Job 运行结束。
4. Map 和 Reduce 任务分别有多少个?
Map 任务的个数取决于输入文件的 split 个数,这个 split 的过程在论文中是由库函数进行的,但是一般来说在一个分布式文件系统中,它存储文件的方式本身就是 split 的形式,因此这一步视情况可以省略。在本 Lab 中,pg- 开头的每一个输入文件就是一个 split,它们的文件名被传给 Master 端。
Reduce 任务的个数小于等于分区数 R,是由用户指定的。Map 函数读取 split 文件生成大量的 KV 对,然后根据 hash(key) % R 的结果将中间键空间划分为 R 个片段,将每个片段的 KV 对输出到一个中间文件中去,每个中间文件都将被输入到一个 Reduce 函数。但是如果 KV 对的数量较少或者是数据较为倾斜,那么最终并不一定有 R 个文件,也就不一定有 R 个 Reduce 任务,所以 Reduce 任务的数量是不一定的,最大为 R。
但是在 Lab 代码中,官方将传递给 Master 的分区数 R 的变量命名为 nReduce,这其实是一种误导,所以我将它改成了 partition。
5. Master 如何在相应的阶段分配 Map 和 Reduce 任务?需要传递什么参数给 Worker?Worker 在完成一个任务以后需要返回什么结果给 Master?
关于这几个问题,概述如下:
1. worker 循环调用 master 的 rpc 方法去获取任务(心跳),直到收到“结束”指令。
2. worker 收到 map 任务,从一个 split 文件读取数据并执行 map ()函数,将缓冲对写入本地磁盘。
3. 当所有的 M 个 map 任务执行完毕后,master 开始分配 reduce 任务,仍然是 worker 主动获取。
4. worker 收到 reduce 任务,读取对应 worker 磁盘上的中间数据(这里就是本地的数据,因为在一台机器上运行),执行 reduce ()函数,将结果输出到一个最终 output 文件。
画了一张图:
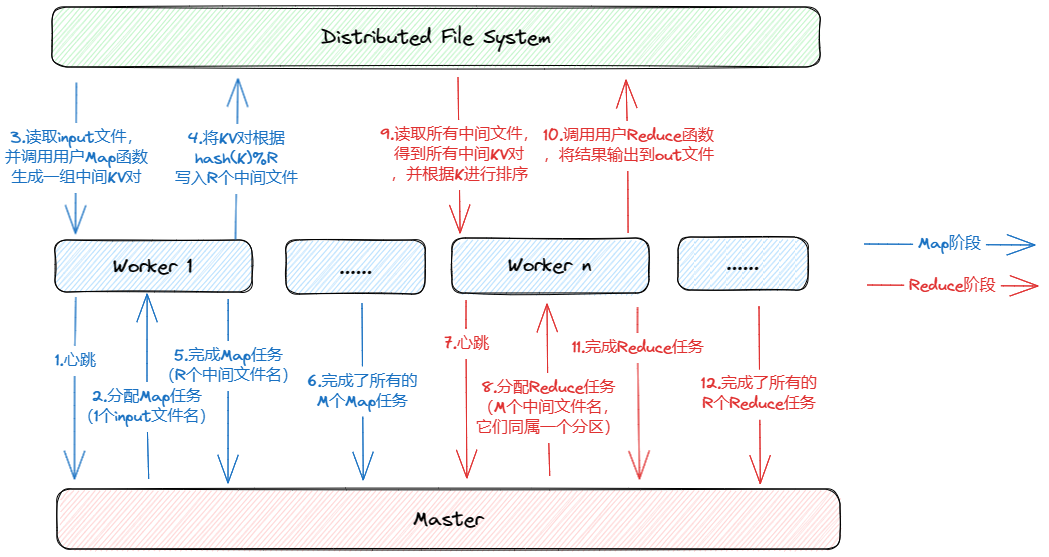
其中,箭头是数据/信息流动的方向,蓝色代表 Map 阶段,红色代表 Reduce 阶段。整体的运行流程按照序号顺序进行。注意,同一个 Worker 可能先后完成多个 Map 和 Reduce 任务,图中的 Worker 编号只是一个示意。Master 相当于服务端,Worker 不断发送请求。在本 Lab 中,DFS 就是本地文件系统。
6. 如果某一个 Worker 掉线了怎么办?
Master 端需要进行简单的容错,我采取的方式是:在 Master 分配给 Worker 一个任务后,异步计时等待(如 10 秒),等待结束后如果该 Worker 还没有返回计算结果,那么就认为该 Worker 掉线了,需要重新分配此任务。
MapReduce 具体实现
代码细节较多,只记录较重要的部分。
Worker 实现
每个 Worker 只管接受任务、执行计算、返回结果,不需要管别的,所以可以先从 Worker 写起。
每当 Worker 通过 RPC 向 Master 发送心跳请求的时候,会收到 4 种可能的回应:
HEATBEAT:Master 的回应心跳,代表现在 Master 没有任务可分配,Worker 暂时空闲;MAPTASK:Master 向自己分配了一个 Map 任务,附带的信息有任务编号 X、输入文件路径、分区数 R;REDUCETASK:Master 向自己分配了一个 Reduce 任务,附带的信息有任务编号 Y、所有的中间文件路径;QUIT:计算 Job 的 Map 和 Reduce 阶段已全部完成,可以退出程序。
初始化代码如下:
func Worker(mapf func(string, string) []KeyValue, reducef func(string, []string) string) {
for {
request := Request{}
reply := Reply{}
request.WorkerId = workerId // 初始值为0
// 通过RPC向Master发送心跳
ok := call("Coordinator.HeartbeatHandler", &request, &reply)
if !ok {
log.Printf("call Coordinator.HeartbeatHandler failed!\n")
return
}
if workerId == 0 {
workerId = reply.WorkerId // 首次获取到Master分配的ID
setLogFile()
}
switch reply.Command {
case QUIT: // 结束
deleteIntermediates() // 删除产生的所有中间文件
log.Println("Quit.")
return
case HEARTBEAT:
log.Println("Receive Heartbeat with master.")
case MAPTASK: // 分配了map任务
log.Println("Got map task:", reply)
doMapTask(reply.Task, mapf, reply.NReduce)
case REDUCETASK: // 分配了reduce任务
log.Println("Got reduce task:", reply)
doReduceTask(reply.Task, reducef)
}
// 心跳间隔
time.Sleep(time.Second * time.Duration(HEARTBEAT_INTERVAL))
}
}
Worker 在初始化后 ID 为 0,Master 在遇见 ID 为 0 的请求后,会从 1 开始累加,向 Worker 分配 ID,Worker 需要保存这个 ID 直到程序结束,在随后的每次请求都要附上自己的 ID。
在收到 Map 任务时:
- 读取输入文件的全部内容;
- 调取用户的 map 函数,得到 KV 数组:
kva := mapf(filename, string(content)); - 遍历 KV 数组的每一个 KV:
- 计算当前 KV 应属分区号 Y:
partition := ihash(kv.Key) % nReduce - 如果不存在,新建中间文件:
mr-X-Y - 将该 KV 以 JSON 格式输出到中间文件
- 计算当前 KV 应属分区号 Y:
- 发送任务完成信息给 Master,内容包含所有中间文件的路径。
在收到 Reduce 任务时:
- 以 JSON 格式读取所有中间文件的内容到一个 KV 数组;
- 对该数组以 Key 进行排序;
- 如果不存在,新建临时结果文件:
mr-out-Y-随机字符; - 对于每一个 Key 和它对应的 Value 集合,调用用户的 reduce 函数:
output := reducef(intermediate[i].Key, values) - output 按格式输出到结果文件。
- 遍历完毕后,更改临时文件名为:
mr-out-Y。 - 发送任务完成信息给 Master。
临时文件的目的是为了防止 reduce 执行到一半 worker 崩溃了,却留给用户任务已完成的假象。
Master 实现
本次采用的 Master 端的模式是完全被动的,也就是不会主动去找 Worker 分配任务,这就需要通过某些设计,使得 Worker 的心跳请求到来后,判断当前是 Map 阶段还是 Reduce 阶段还是已经完成 Job 了。
首先看一下 Task 和 Master 的数据结构:
type Task struct {
TaskType int // 任务类型,Map或Reduce
TaskNo int // 任务编号,用于标识和文件命名
Files []string // 文件路径信息,map就是1个输入文件,reduce就是多个中间文件
}
type Coordinator struct {
jobDone bool // Job是否完成
isReducing bool // 当前是否是Reduce阶段
nextWorkerId int // 下一个新Worker的ID
nMap int // map任务个数
nReduce int // reduce任务个数
partition int // 分区数
unassignedMaps chan Task // 还未分配的map任务
unassignedReduces chan Task // 还未分配的reduce任务
assignedMaps map[int]bool // 已分配的map任务,TaskNo->是否完成
assignedReduces map[int]bool // 已分配的reduce任务,TaskNo->是否完成
working map[int]*Task // 正在工作的worker记录,ID->Task
intermediates map[int][]string // 中间文件名集合,reduceNo->files
mu sync.Mutex // 互斥锁,保证并发安全
}
我采用的是 Go 的 Buffered Channel 进行任务分配。在 Master 初始化的时候,先将每一个输入 split 文件创建一个 MapTask,并压入未分配 Map 任务的队列:
// 初始化map任务
for index, file := range files {
c.unassignedMaps <- Task{MAPTASK, index, []string{file}}
}
然后就是应对 Worker 的 RPC 请求处理函数了,总共有三个:
HeartbeatHandler,处理心跳请求——分配任务MapFinishedHandler,处理 Map 任务完成信息ReduceFinishedHandler,处理 Reduce 任务完成信息
代码如下:
func (c *Coordinator) HeartbeatHandler(request *Request, reply *Reply) error {
log.Println("Receive heartbeat from worker:", request.WorkerId)
c.mu.Lock()
defer c.mu.Unlock()
workerId := request.WorkerId
if workerId == 0 {
workerId = c.nextWorkerId
c.nextWorkerId++
}
reply.WorkerId = workerId
workingTask, exist := c.working[workerId]
if exist { // master的记录中该worker还在工作
// 说明之前的任务可能失败了,需要将task重新入队
c.unassignTask(workingTask)
delete(c.working, workerId)
}
select {
case mapTask := <-c.unassignedMaps:
// 分配map
reply.Task = mapTask
reply.Command = MAPTASK
reply.NReduce = c.partition
c.assignedMaps[mapTask.TaskNo] = false
c.working[workerId] = &mapTask
go c.checkStalled(workerId, &mapTask)
default: // map全部分配了
if allTaskFinished(c.assignedMaps) { // map全部执行完了
select {
case reduceTask := <-c.unassignedReduces:
// 分配reduce
reply.Task = reduceTask
reply.Command = REDUCETASK
c.assignedReduces[reduceTask.TaskNo] = false
c.working[workerId] = &reduceTask
go c.checkStalled(workerId, &reduceTask)
default: // reduce分配完了 - 也有可能没完成初始化,所以需要isReducing判断
if c.isReducing && allTaskFinished(c.assignedReduces) { // reduce全部执行完了
reply.Command = QUIT // 结束任务
}
}
}
}
return nil
}
func (c *Coordinator) MapFinishedHandler(request *Request, reply *Reply) error {
c.mu.Lock()
defer c.mu.Unlock()
log.Println("Receive completion of map task from worker:", request.WorkerId)
mapTask, ok := c.working[request.WorkerId]
if ok {
c.assignedMaps[mapTask.TaskNo] = true
delete(c.working, request.WorkerId)
// 收集worker产生的中间文件名
for rNo, file := range request.Intermediates {
arr, ok := c.intermediates[rNo]
if !ok {
arr = []string{file}
} else {
arr = append(arr, file) // 累加
}
c.intermediates[rNo] = arr
}
if len(c.assignedMaps) == c.nMap && allTaskFinished(c.assignedMaps) { // map全部分配完,并且全部完成
// 初始化reduce任务
log.Println("start reduce")
c.nReduce = len(c.intermediates) // 这才是真正的reduce数量
for rNo, files := range c.intermediates {
// log.Println(rNo, files)
c.unassignedReduces <- Task{REDUCETASK, rNo, files}
}
c.isReducing = true
}
} else {
log.Println("Worker", request.WorkerId, "'s result of map task was discarded.")
}
return nil
}
func (c *Coordinator) ReduceFinishedHandler(request *Request, reply *Reply) error {
c.mu.Lock()
defer c.mu.Unlock()
log.Println("Receive completion of reduce task from worker:", request.WorkerId)
reduceTask, ok := c.working[request.WorkerId]
if ok {
c.assignedReduces[reduceTask.TaskNo] = true
delete(c.working, request.WorkerId)
if len(c.assignedReduces) == c.nReduce && allTaskFinished(c.assignedReduces) { // reduce全部分配完,并且全部完成
log.Println("=== Job done! ===")
c.jobDone = true
}
} else {
log.Println("Worker", request.WorkerId, "'s result of reduce task was discarded.")
}
return nil
}
在每次分配完任务后,都需要另起协程判断 Worker 是否阻塞(掉线)了:
func (c *Coordinator) checkStalled(workerId int, task *Task) {
time.Sleep(time.Second * time.Duration(WAIT_WORKER)) // 等待一段时间
c.mu.Lock()
defer c.mu.Unlock()
currTask, ok := c.working[workerId] // 如果还能从working中获取到对应ID的任务
if ok && currTask == task { // 说明worker仍在执行之前的任务,需要踢出
c.unassignTask(task) // 将task从已分配中删除,加入未分配队列
// 删除工作记录
delete(c.working, workerId)
log.Println("worker:", workerId, "was kicked out.")
}
}
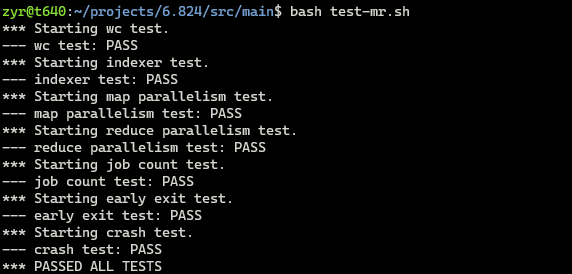
测试全部通过:

















 1042
1042

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









