







1 实验要求
在本实验中,要求实现Raft,这是一种复制状态机协议,用于构建一个容错的键/值存储系统。实验的具体要求如下:
- 实现Raft:
- 将Raft实现为一个Go语言的对象类型,包含相关的方法,以便作为更大服务的一个模块使用。
- Raft实例之间通过RPC通信,以维持复制的日志一致性。
- 支持无限数量的编号命令(日志条目),并能处理这些条目的提交。当一个特定索引的日志条目被提交后,Raft实现应将该条目发送给更大的服务执行。
- 遵循论文设计:
- 遵循Raft论文的设计,重点参考图2。
- 实现论文中描述的大部分功能,包括持久状态的保存和恢复,即使在节点故障和重启后也能保证数据的完整性。
- 不需要实现集群成员变更的部分(论文第六节)。
论文图2:

Raft交互图:
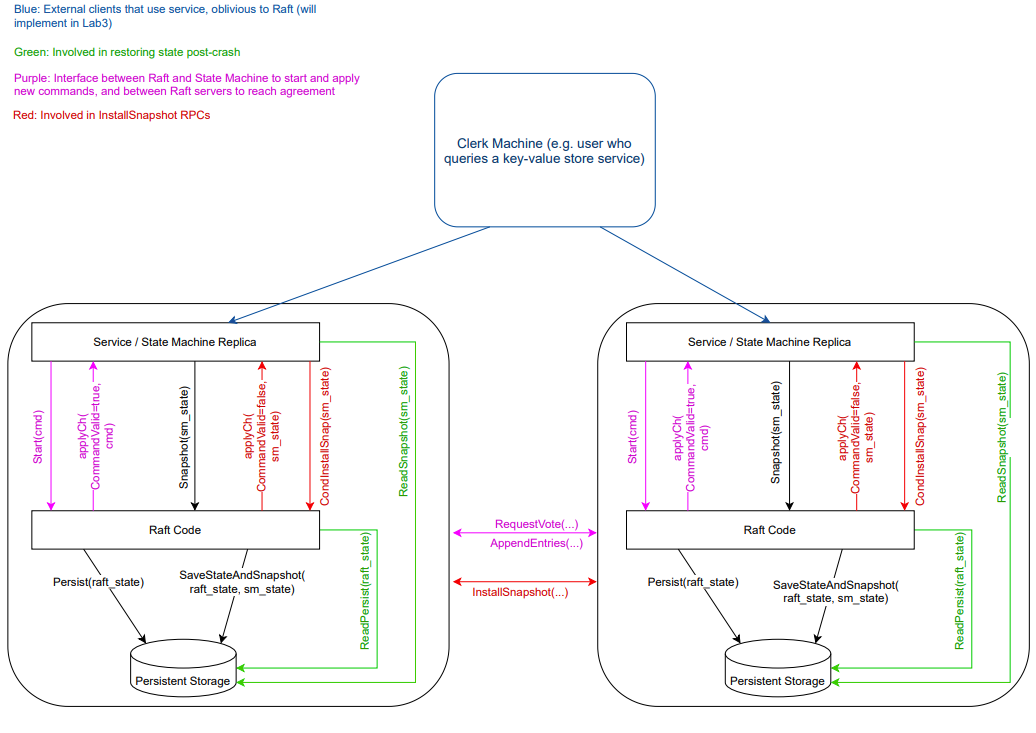
我的实验代码仓库:https://github.com/HeZephyr/MIT6.5840/tree/main/src/raft,已通过压力测试,代码严格遵守上述按要求实现。
注意:下述所贴代码为了简洁以及分块,进行了一定程度的删减,如果需要复现,可以前往仓库。
2 实验设计
2.1 整体结构
此Raft结构体基于论文图2,基本上都是其中介绍的字段以及lab自带的字段,其中其他属性论文中也间接简述和支持,以确保Raft节点能够高效、稳定地运作。如选举定时器和心跳定时器,被明确地纳入了Raft结构体中。这些定时器对于触发关键的系统行为至关重要——选举定时器确保在必要时发起选举过程,而心跳定时器则维持着领导者与跟随者之间的连接,防止不必要的选举。
条件变量(sync.Cond)的引入则是为了精妙地控制两个核心后台goroutine的操作节奏:日志应用goroutine(applier,只需要一个,专门用于监控日志条目的提交状态,一旦日志条目被确认提交,它将负责将这些条目应用到状态机中。)和日志复制goroutine(replicator,负责进行日志条目的同步。考虑到集群中每个peer都需要与除了自身以外的其它peer进行日志同步,这意味着我们需要len(peers) - 1个replicator goroutines来分别处理与每个peer的交互)。
此外,还有一个goroutine ticker负责定期检查选举和心跳的超时,确保在适当的时间间隔内触发选举过程或发送心跳信号。
type Raft struct {
mu sync.RWMutex // Lock to protect shared access to this peer's state, to use RWLock for better performance
peers []*labrpc.ClientEnd // RPC end points of all peers
persister *Persister // Object to hold this peer's persisted state
me int // this peer's index into peers[]
dead int32 // set by Kill()
// Persistent state on all servers(Updated on stable storage before responding to RPCs)
currentTerm int // latest term server has seen(initialized to 0 on first boot, increases monotonically)
votedFor int // candidateId that received vote in current term(or null if none)
logs []LogEntry // log entries; each entry contains command for state machine, and term when entry was received by leader(first index is 1)
// Volatile state on all servers
commitIndex int // index of highest log entry known to be committed(initialized to 0, increases monotonically)
lastApplied int // index of highest log entry applied to state machine(initialized to 0, increases monotonically)
// Volatile state on leaders(Reinitialized after election)
nextIndex []int // for each server, index of the next log entry to send to that server(initialized to leader last log index + 1)
matchIndex []int // for each server, index of highest log entry known to be replicated on server(initialized to 0, increases monotonically)
// other properties
state NodeState // current state of the server
electionTimer *time.Timer // timer for election timeout
heartbeatTimer *time.Timer // timer for heartbeat
applyCh chan ApplyMsg // channel to send apply message to service
applyCond *sync.Cond // condition variable for apply goroutine
replicatorCond []*sync.Cond // condition variable for replicator goroutine
}
func Make(peers []*labrpc.ClientEnd, me int,
persister *Persister, applyCh chan ApplyMsg) *Raft {
rf := &Raft{
mu: sync.RWMutex{},
peers: peers,
persister: persister,
me: me,
dead: 0,
currentTerm: 0,
votedFor: -1,
logs: make([]LogEntry, 1), // dummy entry at index 0
commitIndex: 0,
lastApplied: 0,
nextIndex: make([]int, len(peers)),
matchIndex: make([]int, len(peers)),
state: Follower,
electionTimer: time.NewTimer(RandomElectionTimeout()),
heartbeatTimer: time.NewTimer(StableHeartbeatTimeout()),
applyCh: applyCh,
replicatorCond: make([]*sync.Cond, len(peers)),
}
// initialize from state persisted before a crash
rf.readPersist(persister.ReadRaftState())
// should use mu to protect applyCond, avoid other goroutine to change the critical section
rf.applyCond = sync.NewCond(&rf.mu)
// initialize nextIndex and matchIndex, and start replicator goroutine
for peer := range peers {
rf.matchIndex[peer], rf.nextIndex[peer] = 0, rf.getLastLog().Index+1
if peer != rf.me {
rf.replicatorCond[peer] = sync.NewCond(&sync.Mutex{})
// start replicator goroutine to send log entries to peer
go rf.replicator(peer)
}
}
// start ticker goroutine to start elections
go rf.ticker()
// start apply goroutine to apply log entries to state machine
go rf.applier()
return rf
}
2.2 lab3A:领导者选举
此任务需要实现Raft领导人选举和心跳(通过不附加日志条目的RPC)。对于这个要求,论文中其实给出了状态转移图,指导我们怎么去做。这个选举流程逻辑如下:
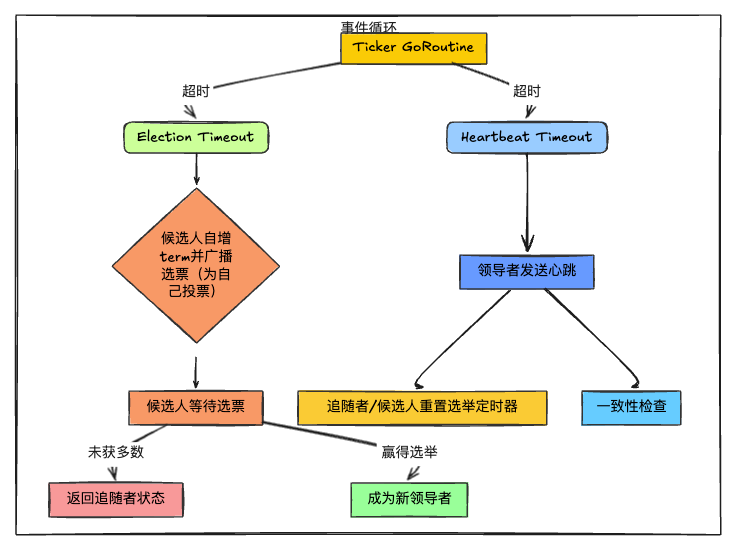
在lab3A实现过程中,需要注意如下几点:
- 当发起投票时,务必使用goroutine并行发起RPC调用,以避免阻塞
ticker协程。这样,即使在等待投票响应期间,候选者(Candidate)仍能响应新的选举超时,从而有机会自增任期并启动新一轮的选举。- 有两种常见的实现投票统计的方式:一种是在函数作用域内定义一个局部变量,并利用闭包来维护投票计数;另一种是在
Raft结构体中维护一个全局的voteCnt变量。为了保持Raft结构体的简洁,推荐采用局部变量和闭包的方案。- 对于过期的RPC请求回复,应直接忽略,不作任何处理。这是因为Raft协议假设网络环境不可靠,可能发生的延迟或重播不应影响当前的决策流程。
- 如果在RPC通信中,节点A发现其任期小于节点B的任期,不论节点A当前的角色如何,都应立即转换为跟随者(Follower)。这是为了维护任期的权威性,确保集群的一致性。
- 为防止多个节点几乎同时启动选举,导致资源浪费和潜在的领导权争夺,应为选举超时设置一个随机的误差范围(如150~300ms),以拉长不同节点选举的时间间隔,这里采用时间戳作为随机种子。且每一次一个节点重置自己的选举定时器时,都需要重新选择一个随机的超时时间。避免服务器会以极小的概率选择相同的随机超时时间,那么会永远处于分割选票的场景中。
- Go RPC 仅发送名称以大写字母开头的结构体字段。子结构还必须具有大写的字段名称(例如数组中日志记录的字段)。这
labgob软件包会警告您这一点;不要忽视警告。- 在同一个任期内,Follower只能投出一票,这是为了防止出现多个Leader的情况。票数的刷新应在任期转换时进行,以确保投票的有效性和一致性。
- 为了提高并发性能,应尽量缩短临界区的长度。合理的锁使用策略是只在真正需要保护共享资源的最小时间内使用锁。
核心的Ticker实现:
func (rf *Raft) ticker() {
for rf.killed() == false {
select {
case <-rf.electionTimer.C:
rf.mu.Lock()
rf.ChangeState(Candidate)
rf.currentTerm += 1
// start election
rf.StartElection()
rf.electionTimer.Reset(RandomElectionTimeout()) // reset election timer in case of split vote
rf.mu.Unlock()
case <-rf.heartbeatTimer.C:
rf.mu.Lock()
if rf.state == Leader {
// should send heartbeat
rf.BroadcastHeartbeat(true)
rf.heartbeatTimer.Reset(StableHeartbeatTimeout())
}
rf.mu.Unlock()
}
}
}
StartElection函数实现:
func (rf *Raft) StartElection() {
rf.votedFor = rf.me
args := rf.genRequestVoteArgs()
grantedVotes := 1
for peer := range rf.peers {
if peer == rf.me {
continue
}
go func(peer int) {
reply := new(RequestVoteReply)
if rf.sendRequestVote(peer, args, reply) {
rf.mu.Lock()
defer rf.mu.Unlock()
if args.Term == rf.currentTerm && rf.state == Candidate {
if reply.VoteGranted {
grantedVotes += 1
// check over half of the votes
if grantedVotes > len(rf.peers)/2 {
rf.ChangeState(Leader)
rf.BroadcastHeartbeat(true)
}
} else if reply.Term > rf.currentTerm {
rf.ChangeState(Follower)
rf.currentTerm, rf.votedFor = reply.Term, -1
}
}
}
}(peer)
}
}
RequestVoteRPC严格按照图2描述实现:
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
defer DPrintf("{Node %v}'s state is {state %v, term %v}} after processing RequestVote, RequestVoteArgs %v and RequestVoteReply %v ", rf.me, rf.state, rf.currentTerm, args, reply)
// Reply false if term < currentTerm(§5.1)
// if the term is same as currentTerm, and the votedFor is not null and not the candidateId, then reject the vote(§5.2)
if args.Term < rf.currentTerm || (args.Term == rf.currentTerm && rf.votedFor != -1 && rf.votedFor != args.CandidateId) {
reply.Term, reply.VoteGranted = rf.currentTerm, false
return
}
if args.Term > rf.currentTerm {
rf.ChangeState(Follower)
rf.currentTerm, rf.votedFor = args.Term, -1
}
// if candidate's log is not up-to-date, reject the vote(§5.4)
if !rf.isLogUpToDate(args.LastLogIndex, args.LastLogTerm) {
reply.Term, reply.VoteGranted = rf.currentTerm, false
return
}
rf.votedFor = args.CandidateId
rf.electionTimer.Reset(RandomElectionTimeout())
reply.Term, reply.VoteGranted = rf.currentTerm, true
}
2.3 lab3B:日志
在Lab3B阶段,我们的目标转向实现Raft协议中至关重要的日志复制机制。其中入口是Start函数(应用程序与Raft的接口)。具体的日志复制流程:
- 一旦Leader接收到新的日志条目,它首先会在自己的日志中追加这个条目。
- 随后,Leader通过
BroadcastHeartbeat函数将这个日志条目广播至集群中的所有Peer,确保所有节点都能同步最新的状态。此过程涉及对日志条目的校验与冲突解决,确保每个Peer的日志保持一致且最新。 - 在日志条目被发送给Peers后,Leader会等待来自Peer的确认回复。只有当Leader收到大多数Peer(即超过半数)的确认,表明这些Peer已经成功复制了日志条目,Leader才能认为该日志条目已经被安全地复制。这是Raft协议中“多数原则”的体现,确保了即使在部分节点失败的情况下,系统仍然能够达成一致。当然,也需要根据回复确认自己Leader的地位,如果不再是Leader,需要更改为Follower。
- 一旦日志条目被确认复制到了大多数节点,Leader就会标记这个条目为已提交(committed)。随后,Leader会通过
AppendEntriesRPC将最新的LeaderCommit信息广播给所有Peer,指示它们哪些日志条目现在可以被提交并应用到各自的状态机中。每个Peer根据接收到的LeaderCommit值来决定其日志中哪些条目可以被提交,从而确保所有活跃Peer的状态机保持一致。
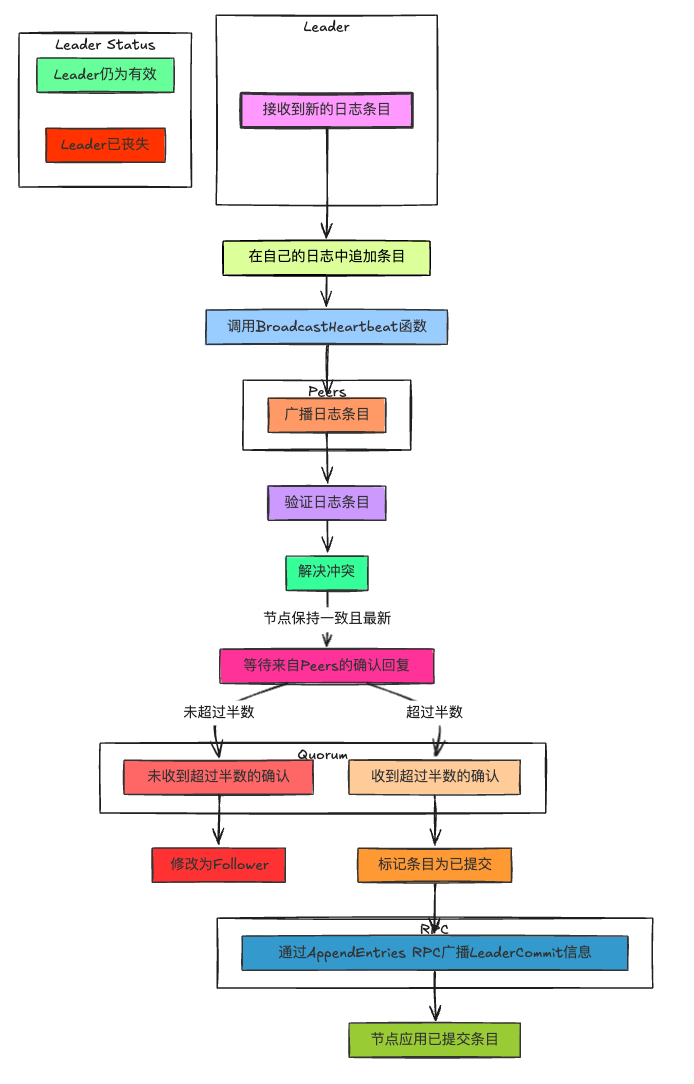
在lab3B实现过程中,需要注意如下几点:
- 在发送RPC、接收RPC、推送和接收channel时,绝对不要持有锁,否则极易引发死锁。这在locking博客中有详细介绍,应时刻牢记。使用读写锁时,对于只读操作,只需持有读锁,避免不必要的写锁持有,以提高并发性能。
- 对于过期的RPC请求回复,应直接忽略,避免执行任何业务逻辑
- 根据图2的规定,Raft Leader只能提交属于当前任期的日志条目,不得提交前任期的日志。在根据
matchIndex[]判断是否可以提交日志时,必须检查该日志的任期是否与当前Leader的任期相匹配。- Follower对Leader的
leaderCommit应无条件服从,无需额外判断。- Leader需维护好
matchIndex[](跟踪Follower的提交状态)和nextIndex[](追踪Follower的日志复制进度),并在Leader崩溃后正确地初始化这两个数组。- 当Follower接收到日志时,需检查RPC中Leader认定的当前Follower的
prevLogIndex和prevLogTerm,判断日志是否存在冲突,若存在冲突,需由Leader从冲突点开始强制覆盖Follower的日志。- 新的Leader的日志需确保包含了所有已提交的日志条目。Follower可能在Leader提交日志期间进入不可用状态,从而导致被选为新Leader的Follower可能覆盖已提交的日志条目。为避免这种情况,选举时需加入Leader限制机制,即Follower只给任期和日志更新的Candidate投票,具体规则如下:
- 如果任期号不同,任期号较大的Candidate更新;
- 如果任期号相同,日志索引值较大(即日志更长)的Candidate更新。
核心的AppendEntries RPC实现:
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
// Your code here (3A, 3B).
rf.mu.Lock()
defer rf.mu.Unlock()
defer DPrintf("{Node %v}'s state is {state %v, term %v}} after processing AppendEntries, AppendEntriesArgs %v and AppendEntriesReply %v ", rf.me, rf.state, rf.currentTerm, args, reply)
// Reply false if term < currentTerm(§5.1)
if args.Term < rf.currentTerm {
reply.Term, reply.Success = rf.currentTerm, false
return
}
// indicate the peer is the leader
if args.Term > rf.currentTerm {
rf.currentTerm, rf.votedFor = args.Term, -1
}
rf.ChangeState(Follower)
rf.electionTimer.Reset(RandomElectionTimeout())
// Reply false if log doesn’t contain an entry at prevLogIndex whose term matches prevLogTerm(§5.3)
if args.PrevLogIndex < rf.getFirstLog().Index {
reply.Term, reply.Success = rf.currentTerm, false
return
}
// check the log is matched, if not, return the conflict index and term
// if an existing entry conflicts with a new one (same index but different terms), delete the existing entry and all that follow it(§5.3)
if !rf.isLogMatched(args.PrevLogIndex, args.PrevLogTerm) {
reply.Term, reply.Success = rf.currentTerm, false
lastLogIndex := rf.getLastLog().Index
// find the first index of the conflicting term
if lastLogIndex < args.PrevLogIndex {
// the last log index is smaller than the prevLogIndex, then the conflict index is the last log index
reply.ConflictIndex, reply.ConflictTerm = lastLogIndex+1, -1
} else {
firstLogIndex := rf.getFirstLog().Index
// find the first index of the conflicting term
index := args.PrevLogIndex
for index >= firstLogIndex && rf.logs[index-firstLogIndex].Term == args.PrevLogTerm {
index--
}
reply.ConflictIndex, reply.ConflictTerm = index+1, args.PrevLogTerm
}
return
}
// append any new entries not already in the log
firstLogIndex := rf.getFirstLog().Index
for index, entry := range args.Entries {
// find the junction of the existing log and the appended log.
if entry.Index-firstLogIndex >= len(rf.logs) || rf.logs[entry.Index-firstLogIndex].Term != entry.Term {
rf.logs = append(rf.logs[:entry.Index-firstLogIndex], args.Entries[index:]...)
break
}
}
// If leaderCommit > commitIndex, set commitIndex = min(leaderCommit, index of last new entry) (paper)
newCommitIndex := Min(args.LeaderCommit, rf.getLastLog().Index)
if newCommitIndex > rf.commitIndex {
rf.commitIndex = newCommitIndex
rf.applyCond.Signal()
}
reply.Term, reply.Success = rf.currentTerm, true
}
replicateOnceRound用来调用AppendEntriesRPC,并根据reply继续相应处理:
func (rf *Raft) replicateOnceRound(peer int) {
rf.mu.RLock()
if rf.state != Leader {
rf.mu.RUnlock()
return
}
prevLogIndex := rf.nextIndex[peer] - 1
args := rf.genAppendEntriesArgs(prevLogIndex)
rf.mu.RUnlock()
reply := new(AppendEntriesReply)
if rf.sendAppendEntries(peer, args, reply) {
rf.mu.Lock()
if args.Term == rf.currentTerm && rf.state == Leader {
if !reply.Success {
if reply.Term > rf.currentTerm {
// indicate current server is not the leader
rf.ChangeState(Follower)
rf.currentTerm, rf.votedFor = reply.Term, -1
} else if reply.Term == rf.currentTerm {
// decrease nextIndex and retry
rf.nextIndex[peer] = reply.ConflictIndex
if reply.ConflictTerm != -1 {
firstLogIndex := rf.getFirstLog().Index
for index := args.PrevLogIndex - 1; index >= firstLogIndex; index-- {
if rf.logs[index-firstLogIndex].Term == reply.ConflictTerm {
rf.nextIndex[peer] = index
break
}
}
}
}
} else {
rf.matchIndex[peer] = args.PrevLogIndex + len(args.Entries)
rf.nextIndex[peer] = rf.matchIndex[peer] + 1
// advance commitIndex if possible
rf.advanceCommitIndexForLeader()
}
}
rf.mu.Unlock()
}
}
Leader应用已提交log的advanceCommitIndexForLeader函数实现:
func (rf *Raft) advanceCommitIndexForLeader() {
n := len(rf.matchIndex)
sortMatchIndex := make([]int, n)
copy(sortMatchIndex, rf.matchIndex)
sort.Ints(sortMatchIndex)
// get the index of the log entry with the highest index that is known to be replicated on a majority of servers
newCommitIndex := sortMatchIndex[n-(n/2+1)]
if newCommitIndex > rf.commitIndex {
if rf.isLogMatched(newCommitIndex, rf.currentTerm) {
rf.commitIndex = newCommitIndex
rf.applyCond.Signal()
}
}
}
每个peer应用已提交的goroutine applier实现:
func (rf *Raft) applier() {
for rf.killed() == false {
rf.mu.Lock()
// check the commitIndex is advanced
for rf.commitIndex <= rf.lastApplied {
// need to wait for the commitIndex to be advanced
rf.applyCond.Wait()
}
// apply log entries to state machine
firstLogIndex, commitIndex, lastApplied := rf.getFirstLog().Index, rf.commitIndex, rf.lastApplied
entries := make([]LogEntry, commitIndex-lastApplied)
copy(entries, rf.logs[lastApplied-firstLogIndex+1:commitIndex-firstLogIndex+1])
rf.mu.Unlock()
// send the apply message to applyCh for service/State Machine Replica
for _, entry := range entries {
rf.applyCh <- ApplyMsg{
CommandValid: true,
Command: entry.Command,
CommandIndex: entry.Index,
}
}
rf.mu.Lock()
// use commitIndex rather than rf.commitIndex because rf.commitIndex may change during the Unlock() and Lock()
rf.lastApplied = commitIndex
rf.mu.Unlock()
}
}
2.4 lab3C:持久化
如果基于 Raft 的服务器重新启动,它应该从中断处恢复服务。这要求 Raft 保持在重启后仍然存在的持久状态。论文的图 2 提到了哪种状态应该是持久的,即logs、currentTerm和votedFor。在Lab3C中,我们的任务便是实现persist()和readPersist()这两个核心函数,前者负责保存Raft的状态,后者则是在Raft启动时恢复之前保存的数据。
readPersist函数实现:
func (rf *Raft) readPersist(data []byte) {
if data == nil || len(data) < 1 { // bootstrap without any state?
return
}
r := bytes.NewBuffer(data)
d := labgob.NewDecoder(r)
var currentTerm, votedFor int
var logs []LogEntry
if d.Decode(¤tTerm) != nil || d.Decode(&votedFor) != nil || d.Decode(&logs) != nil {
DPrintf("{Node %v} fails to decode persisted state", rf.me)
}
rf.currentTerm, rf.votedFor, rf.logs = currentTerm, votedFor, logs
rf.lastApplied, rf.commitIndex = rf.getFirstLog().Index, rf.getFirstLog().Index
}
persist函数实现:
func (rf *Raft) encodeState() []byte {
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
e.Encode(rf.currentTerm)
e.Encode(rf.votedFor)
e.Encode(rf.logs)
return w.Bytes()
}
func (rf *Raft) persist() {
rf.persister.SaveStateAndSnapshot(rf.encodeState(), nil)
}
实现好后,我们只需要在入口处Make调用readPersist即可,关键需要在什么时候保存状态呢?其实很简单,只需要对我们需要持久化的三个字段修改的时候就进行persist操作。即persist()操作应当在以下几种情况下被触发:
- 日志条目更新:当有新的日志条目被添加到
logs中,或是已有条目被删除或替换时。 - 任期变更:当
currentTerm发生变化,比如在选举期间或接收到更高任期的领导者信息时。 - 投票行为:当
votedFor字段被更新,意味着节点投出了新的一票或取消了之前的投票。
2.5 lab3D:日志压缩
按照目前的情况,重新启动的服务器会重放完整的 Raft 日志以恢复其状态。然而,对于一个长期运行的服务来说,永远记录完整的 Raft 日志是不切实际的。需要使用快照服务配合,此时Raft会丢弃快照之前的日志条目。lab3D就是需要我们实现日志压缩,具体来说是核心是Snapshot(快照保存函数)以及InstallSnapshotRPC,快照压缩的流程:
- 每个peer都会通过
Snapshot捕获当前系统状态的一个快照。这通常包括但不限于状态机的当前状态、任何必要的元数据、以及快照生成时的任期信息。 - 当Leader认为有必要向Follower发送快照时,它将发起
InstallSnapshotRPC调用。这通常发生在Follower的日志状态与Leader严重脱节时,例如日志冲突无法通过常规的AppendEntriesRPC解决。 - Follower接收到快照后,会验证其完整性和一致性,然后应用快照以替换其当前状态和日志。这包括清除快照点之前的所有日志条目,并将状态机恢复到快照所表示的状态。
- Follower在成功应用快照后,应通过RPC回复向Leader确认,表明快照已被正确安装。Leader据此更新其
matchIndex和nextIndex数组,以反映Follower的最新状态。
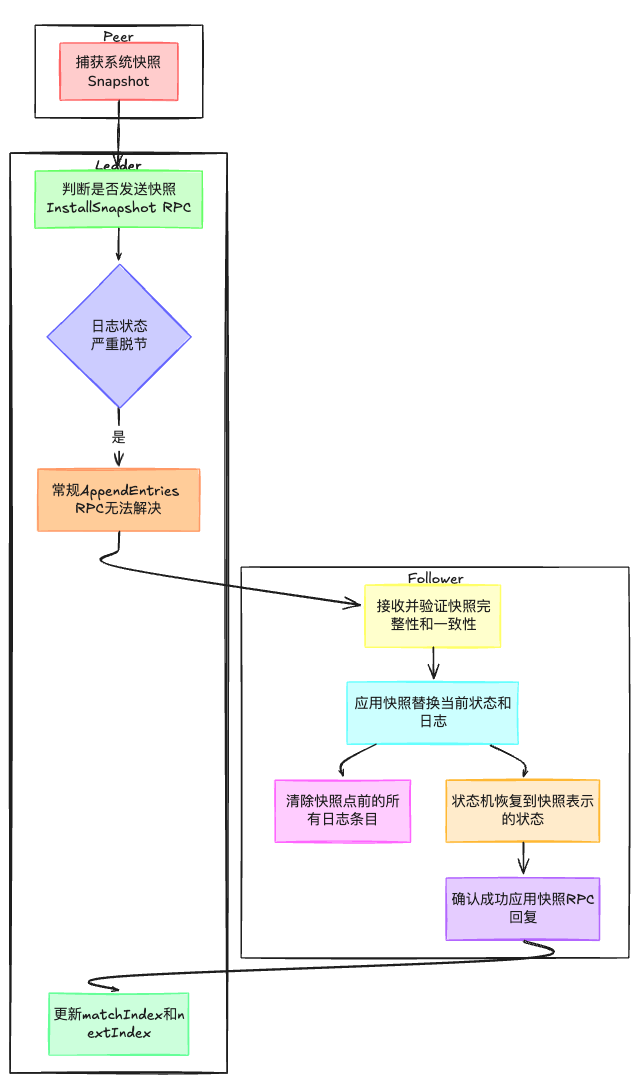
在lab3D实现过程中,需要注意以下几点:
- 在更新
lastApplied时,必须采用前一时刻的commitIndex值,而非实时的rf.commitIndex。这是因为,在执行push applyCh过程中,rf.commitIndex可能因其他操作而动态变化,使用其历史值可以保证lastApplied更新的准确性。- 需要注意使用
CondInstallSnapshot来验证快照的有效性。- 在修剪log的时候注意留一个dummy log
- 使用
Max(rf.lastApplied, commitIndex)而不是直接使用commitIndex来避免并发 InstallSnapshot RPC 导致lastApplied回滚
InstallSnapshot RPC实现如下:
func (rf *Raft) InstallSnapshot(args *InstallSnapshotArgs, reply *InstallSnapshotReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
reply.Term = rf.currentTerm
// reply immediately if term < currentTerm
if args.Term < rf.currentTerm {
return
}
if args.Term > rf.currentTerm {
rf.currentTerm, rf.votedFor = args.Term, -1
rf.persist()
}
rf.ChangeState(Follower)
rf.electionTimer.Reset(RandomElectionTimeout())
// check the snapshot is more up-to-date than the current log
if args.LastIncludedIndex <= rf.commitIndex {
return
}
go func() {
rf.applyCh <- ApplyMsg{
SnapshotValid: true,
Snapshot: args.Data,
SnapshotTerm: args.LastIncludedTerm,
SnapshotIndex: args.LastIncludedIndex,
}
}()
}
Snapshot函数实现如下,它接收客户端创建的快照。
func (rf *Raft) Snapshot(index int, snapshot []byte) {
rf.mu.Lock()
defer rf.mu.Unlock()
snapshotIndex := rf.getFirstLog().Index
if index <= snapshotIndex || index > rf.getLastLog().Index {
DPrintf("{Node %v} rejects replacing log with snapshotIndex %v as current snapshotIndex %v is larger in term %v", rf.me, index, snapshotIndex, rf.currentTerm)
return
}
// remove log entries up to index
rf.logs = rf.logs[index-snapshotIndex:]
rf.logs[0].Command = nil
rf.persister.SaveStateAndSnapshot(rf.encodeState(), snapshot)
}
还有一个CondInstallSnapshot,用来peer判断leader发过来的快照是否满足条件,如果满足,则安装快照。这个需要修改到config.go文件中。
func (rf *Raft) CondInstallSnapshot(lastIncludedTerm int, lastIncludedIndex int, snapshot []byte) bool {
rf.mu.Lock()
defer rf.mu.Unlock()
// outdated snapshot
if lastIncludedIndex <= rf.commitIndex {
return false
}
// need dummy entry at index 0
if lastIncludedIndex > rf.getLastLog().Index {
rf.logs = make([]LogEntry, 1)
} else {
rf.logs = rf.logs[lastIncludedIndex-rf.getFirstLog().Index:]
rf.logs[0].Command = nil
}
rf.logs[0].Term, rf.logs[0].Index = lastIncludedTerm, lastIncludedIndex
rf.commitIndex, rf.lastApplied = lastIncludedIndex, lastIncludedIndex
rf.persister.SaveStateAndSnapshot(rf.encodeState(), snapshot)
}
3 压测脚本
我自己实现了一个压测脚本:
#!/bin/bash
# check the number of arguments
if [ "$#" -ne 2 ]; then
echo "Usage: $0 <test_type> <iterations>"
echo "test_type must be one of 3A, 3B, 3C, 3D"
exit 1
fi
test_type=$1
iterations=$2
# check the test_type
if [[ "$test_type" != "3A" && "$test_type" != "3B" && "$test_type" != "3C" && "$test_type" != "3D" ]]; then
echo "Invalid test_type: $test_type"
echo "test_type must be one of 3A, 3B, 3C, 3D"
exit 1
fi
# check the iterations is a positive integer
if ! [[ "$iterations" =~ ^[0-9]+$ ]]; then
echo "Invalid iterations: $iterations"
echo "iterations must be a positive integer"
exit 1
fi
echo "go test -run $test_type"
for ((i=1; i<=iterations; i++))
do
echo "Running test iteration $i"
output=$(go test -run $test_type 2>&1) # 2>&1 redirects stderr to stdout
if [[ $? -ne 0 ]]; then
echo "Error in iteration $i:"
echo "$output"
fi
done
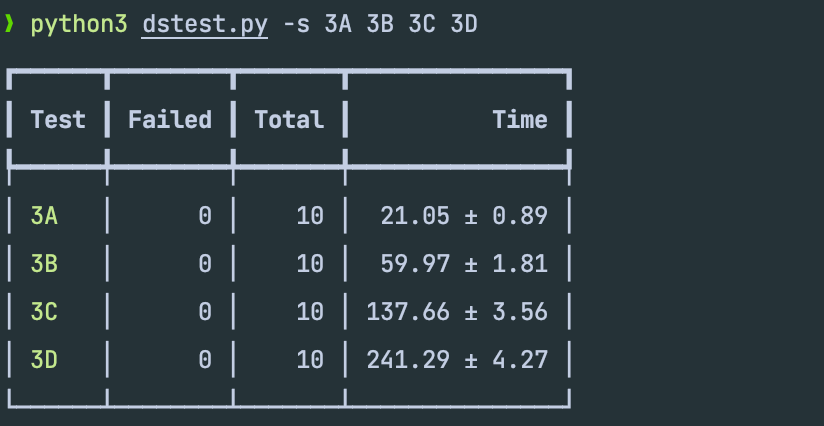
网上也提供了一个测试脚本,功能更为强大。压测结果如下所示:
4 优化
-
如果我们使用的空间少于数组的一半,我们就替换该数组。这个数字是相当任意的,选择它是为了平衡内存使用与分配数量,这个数字可能还可以改进。
func shrinkEntries(entries []LogEntry) []LogEntry { const lenMultiple = 2 if cap(entries) > len(entries)*lenMultiple { newEntries := make([]LogEntry, len(entries)) copy(newEntries, entries) return newEntries } return entries } -
因为日志的索引是单调递增的,而term则是非递减的。所以这里应该可以使用二分优化。
















 891
891

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











