










 本文深入探讨了动态规划中一种特定的优化技巧,通过分析如何使用单调栈和决策单调性来减少状态转移的复杂度,将算法的时间复杂度降低至O(n²logn)。文章详细介绍了如何构建和维护单调栈,以及如何进行高效的决策比较。
本文深入探讨了动态规划中一种特定的优化技巧,通过分析如何使用单调栈和决策单调性来减少状态转移的复杂度,将算法的时间复杂度降低至O(n²logn)。文章详细介绍了如何构建和维护单调栈,以及如何进行高效的决策比较。
Description


Solution
首先发现性质
可以看出,如果上一次叠的甲还没有掉完,那么此时是不会叠甲的
因为这时候叠甲,不如把这些甲移到上次一起叠,那么肯定是更优的。
那么现在就相当于用若干个下降且不交的三角形来覆盖这个序列。
考虑DP
设
F
[
i
]
[
j
]
F[i][j]
F[i][j]表示1到i-1我们已经处理完了,已经花了j层甲,现在是一层也没有的最大总挡掉的伤害值。
要么直接从i-1不叠甲转移过来,要么从前面某一个k的位置叠i-k层甲,到i处影响刚好结束。
那么预处理c[i][j]表示在i处叠j甲总共能挡掉多少伤害,特殊处理不叠的情况,转移就是
f
[
i
]
[
j
]
=
m
a
x
(
f
[
k
]
[
j
−
i
+
k
]
+
c
[
k
]
[
i
−
k
]
)
,
k
∈
[
1
,
i
−
1
]
f[i][j]=max(f[k][j-i+k]+c[k][i-k]),k\in[1,i-1]
f[i][j]=max(f[k][j−i+k]+c[k][i−k]),k∈[1,i−1]
如果我们令
p
=
i
−
k
p=i-k
p=i−k,则
f
[
i
]
[
j
]
=
m
a
x
(
f
[
i
−
p
]
[
j
−
p
]
+
c
[
i
−
p
]
[
p
]
)
f[i][j]=max(f[i-p][j-p]+c[i-p][p])
f[i][j]=max(f[i−p][j−p]+c[i−p][p])
我们发现,在这个过程中能转移的状态
i
−
j
i-j
i−j是恒定的
那么把所有状态按i-j分组,令
d
=
i
−
j
d=i-j
d=i−j
那么状态就变成
f
[
i
]
[
i
−
d
]
f[i][i-d]
f[i][i−d]
对于一个
f
[
i
]
[
i
−
d
]
f[i][i-d]
f[i][i−d],考虑能转移到它的两个位置
x
,
y
x,y
x,y,我们假设x<y,x要更优于y
那么
f
[
x
]
[
x
−
d
]
+
c
[
x
]
[
i
−
x
]
>
f
[
y
]
[
y
−
d
]
+
c
[
y
]
[
i
−
y
]
f[x][x-d]+c[x][i-x]>f[y][y-d]+c[y][i-y]
f[x][x−d]+c[x][i−x]>f[y][y−d]+c[y][i−y]
考虑
c
[
x
]
[
i
−
x
]
−
c
[
y
]
[
i
−
y
]
c[x][i-x]-c[y][i-y]
c[x][i−x]−c[y][i−y],它是从x开始的三角形减去从y开始的三角形的部分
大概如下图
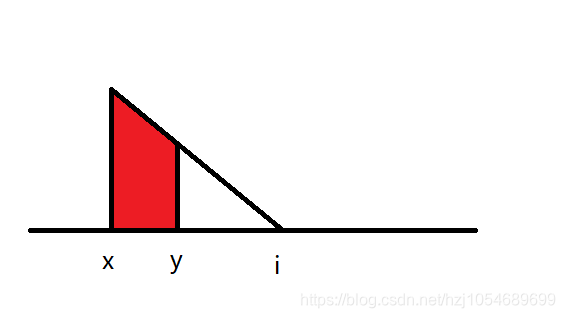
红色部分挡掉的伤害就是
c
[
x
]
[
i
−
x
]
−
c
[
y
]
[
i
−
y
]
c[x][i-x]-c[y][i-y]
c[x][i−x]−c[y][i−y],可以发现它随着i的增大是单调递增的,而
f
[
x
]
[
x
−
d
]
,
f
[
y
]
[
y
−
d
]
f[x][x-d],f[y][y-d]
f[x][x−d],f[y][y−d]与i无关
因此我们可以得出,这个决策是单调的,位置更前的决策x,在i越后的时候就会越优,直到在某个位置超过y
这就是典型的1D1D动态规划用决策单调性的优化了
那么对于每一组,我们可以用一个单调栈来存储决策,每个元素记录它被它下面的元素超过的时间,i右移、新加入元素的时候相应的弹栈即可。
此时我们还需要查询两个位置超过的时间,这可以用二分来做。
因此总的复杂度是 O ( n 2 log n ) 的 O(n^2\log n)的 O(n2logn)的
Code
#include <cstdio>
#include <iostream>
#include <algorithm>
#include <cstdlib>
#include <cstring>
#include <cmath>
#define fo(i,a,b) for(int i=a;i<=b;++i)
#define fod(i,a,b) for(int i=a;i>=b;--i)
#define N 4005
#define LL long long
using namespace std;
LL f[N][N],c[N][2*N],ans[N];
int n,a[N],d[N][N],t[N][N],le[N];
int fd(int q,int y,int x)
{
int l=y+1,r=2*n+1;
while(l+1<r)
{
int mid=(l+r)>>1;
if(f[y][y-q]+c[y][mid-y]<f[x][x-q]+c[x][mid-x]) r=mid;
else l=mid;
}
if(f[y][y-q]+c[y][l-y]<f[x][x-q]+c[x][l-x]) return l;
else return r;
}
void push(int q,int k)
{
while(le[q]>0&&t[q][le[q]]<=fd(q,k,d[q][le[q]])) d[q][le[q]]=t[q][le[q]]=0,le[q]--;
d[q][++le[q]]=k;
if(le[q]==1) t[q][le[q]]=2*n+1;
else t[q][le[q]]=fd(q,k,d[q][le[q]-1]);
}
LL get(int q,int k)
{
if(le[q]==0) return 0;
while(le[q]>0&&t[q][le[q]]<=k) d[q][le[q]]=t[q][le[q]]=0,le[q]--;
return f[d[q][le[q]]][d[q][le[q]]-q]+c[d[q][le[q]]][k-d[q][le[q]]];
}
int main()
{
cin>>n;
LL s=0;
fo(i,1,n) scanf("%d",&a[i]),s+=a[i];
fod(i,n,1)
{
fo(j,1,2*n)
{
c[i][j]=min(j,a[i])+c[i+1][j-1];
c[i][j]=max(c[i][j],c[i][j-1]);
}
}
push(1,1);
push(0,1);
fo(i,2,2*n)
{
fo(j,0,i)
{
if(j>n) break;
if(i==n+1) ans[j]=max(ans[j],f[i-1][j]);
else if(i<=n) f[i][j]=max(f[i][j],f[i-1][j]);
if(i>n) ans[j]=max(ans[j],get(i-j,i));
else
{
f[i][j]=max(f[i][j],get(i-j,i));
push(i-j,i);
}
}
}
fo(i,1,n) printf("%lld\n",s-ans[i]);
}

















 1086
1086

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









