







摘要
我们引入了一个将强化学习(RL)抽象为序列建模问题的框架。这使我们能够利用Transformer架构的简单性和可扩展性,以及GPT-x和BERT等语言建模的相关进步。特别是,我们提出了Decision Transformer,一种将RL问题转换为条件序列建模的架构。与先前拟合价值函数或计算策略梯度的RL方法不同,Decision Transformer通过利用因果掩码的Transformer简单地输出最优动作。通过对期望回报(奖励)、过去状态和动作的自回归模型进行调节,我们的Decision Transformer模型可以生成实现期望回报的未来动作。尽管它很简单,但Decision Transformer在Atari、OpenAI Gym和Key-to-Door任务上的性能匹配或超过了最先进的model-free offline RL基准。
论文概述
- 提出了一种将强化学习(RL)抽象为序列建模问题的框架,称为Decision Transformer(DT)。
- 利用Transformer架构的简单性与可扩展性和语言建模(如GPT-x和BERT)的先进技术,将RL问题转化为条件序列建模问题。
- Decision Transformer仅通过在Transformer上使用因果掩码来输出最优动作。
- 通过将自回归模型的输入设置为期望回报、过去状态和动作,Decision Transformer模型可以生成实现期望回报的未来动作。 尽管Decision Transformer很简单,但在Atari、OpenAI Gym和Key-to-Door任务上,它的性能与最先进的基于模型的离线RL方法相匹配甚至超过。
一、 Introduction
研究是否生成轨迹建模——即对状态、动作和奖励序列的联合分布进行建模——可以替代传统的RL算法。
考虑几个范式的转变: ① 使用序列来建模目标,并根据收集到的经验来训练模型(offline的方式),避免了长时间的bootstrap过程; ② 避免对未来的回报打折扣,防止出现短视的情况; ③ 可以借助于当前在语言和视觉方面训练稳定的transformer模型; ④ transformer能够直接利用self-attention机制完成credit-assignment,应对稀疏奖励的场景,credit-assignment指的是每个动作各自产生的影响。比如说贝尔曼方程通过价值函数传播的方式缓慢更新,可以依靠credit-assignment通过分析动作对回报的贡献加快学习速度,从而提高样本利用率(稀疏奖励); ⑤ transformer能够建模一个很广的分布,适合泛化与迁移。
除了展示出对长序列进行建模的能力外,Transformer还有其他优势。
- Transformer可以通过自注意力直接执行信度分配,而Bellman备份则缓慢传播奖励并且容易产生“干扰”信号。这可以使Transformer在存在稀疏或分散注意力的奖励时仍然有效地工作。
- Transformer建模方法可以对广泛分布的行为进行建模,从而实现更好的泛化和迁移。
二、Method
Trajectory representation
选择轨迹表示(trajectory representation)的关键要求是:
(a) 它应该使 Transformer 能够学习有意义的模式;
(b) 我们应该能够在测试时有条件地生成动作。
不直接使用瞬时收益作为奖励,而是将奖励建模为 return-to-go(未来收益之和):

轨迹(适合于自回归训练和生成):
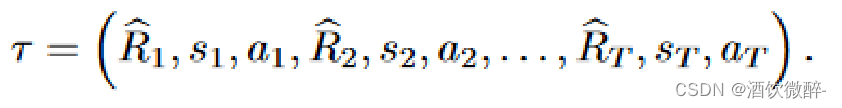 Illustrative example
Illustrative example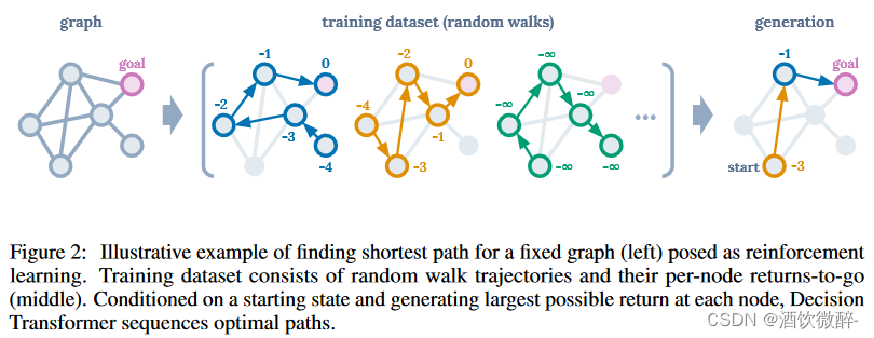
作为RL问题提出:在有向图上找到最短路径的任务。
当智能体在目标节点时奖励为0,否则为-1。
MDP 中每走一步会得到 -1 的 reward,智能体从随机位置出发按随机策略行动直到到达 goal 结束轨迹。每个圈边上的数字即是该轨迹中对应状态下的 return-to-go。在训练完成后的 generation 阶段,给定起点位置后,只须在每一步决策时以训练数据中此位置收到的最大 return-to-go 作为条件选择动作,就能实现 offline 数据集中次优轨迹的拼接。
DT模型结构
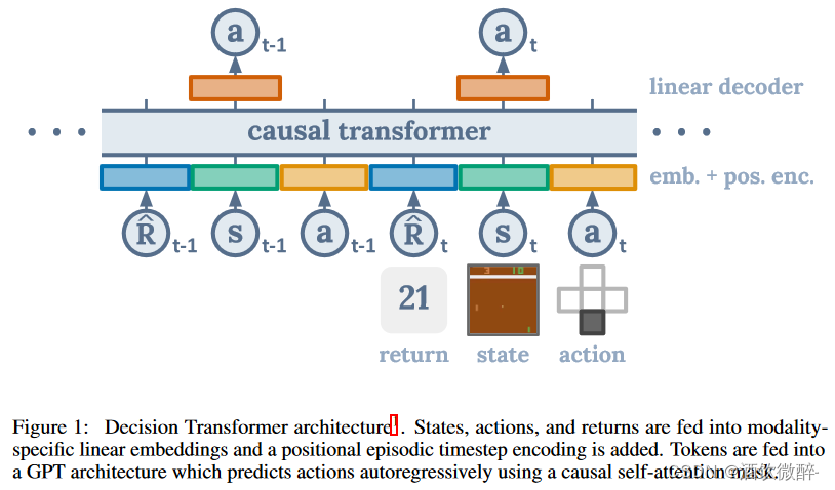
我们将最后的K个时间步骤输入到Decision Transformer中,总共有3K个token(每种模式一个:return-to-go、状态或动作)。为了获得token嵌入,我们为每种模态学习了一个线性层,它将原始输入投影到嵌入维度,然后进行层归一化。对于具有视觉输入的环境,状态被输入卷积编码器而不是线性层。此外,每个时间步骤的嵌入都会被学习并添加到每个token中——注意这与Transformer使用的标准位置嵌入不同,因为一个时间步骤对应于三个token。然后这些token由GPT模型处理,该模型通过自回归建模预测未来的动作token。
注意:
从上往下看:
1.处理后的轨迹按顺序输入,任意R,s,a 都是一个token;
2.蓝绿黄的小方块代表嵌入层,这里R,s,a 先分别使用三个嵌入层进行嵌入,然后再直接加上位置编码完成嵌入;
3. “causal transformer” 其实就是 GPT 这种带有mask self attention 结构的Transformer 结构,不过 DT 里这个 mask 是按时刻 t 一组一组地遮盖的;本文没有预测状态和奖励,仅仅预测了动作。
4.上面的橘黄色块是一个线性层,把 GPT 结构得到的动态 token 嵌入向量转变为实际的 action。具体来说,如果环境的动作空间是离散的,这里就用线性层调整下维度然后加 softmax 优化交叉熵损失;如果动作空间是连续的,这里就用线性层直接输出动作然后优化 L2 损失。
伪代码:最终算法:损失函数是均方误差函数,故这是个纯粹的监督学习(离散情况下是交叉熵)。

Training
我们得到了一个offline轨迹数据集。我们从数据集中抽取序列长度为K的小批量。对应于输入token st的预测头被训练以预测at——离散动作的交叉熵损失或连续动作的均方误差——并且每个时间步骤的损失被平均。尽管在我们的框架内很容易允许并且对于未来的工作来说这将是一项有趣的研究,但我们并没有发现预测状态或收益来提高性能。
比较方法
本文主要比较方法是最先进的无模型方法是CQL(Conservative Q-Learning)。
三、实验
TD学习:这些方法中的大多数使用动作空间约束或价值悲观主义,将是与Decision Transformer最忠实的比较,代表标准RL方法。一种最先进的model-free方法是Conservative Q-Learning (CQL) ,作为我们的主要比较。此外,我们还与其他先前的model-free RL算法(如BEAR 和BRAC )进行了比较。
模仿学习:该机制类似地使用监督损失进行训练,而不是Bellman备份。我们在这里使用行为克隆,并在第5.1节中包含更详细的讨论。
我们评估离散(Atari [10])和连续(OpenAI Gym [11])控制任务。前者涉及高维观察空间,需要长期的信度分配,而后者需要细粒度的连续控制,代表着多样化的任务集。我们的主要结果总结在图3中,其中我们显示了每个域的平均归一化性能。
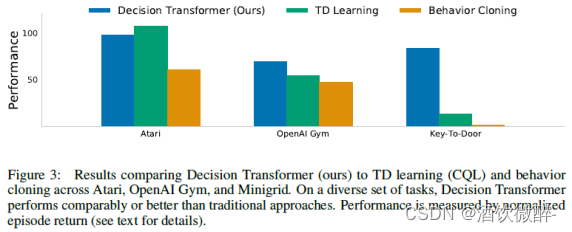
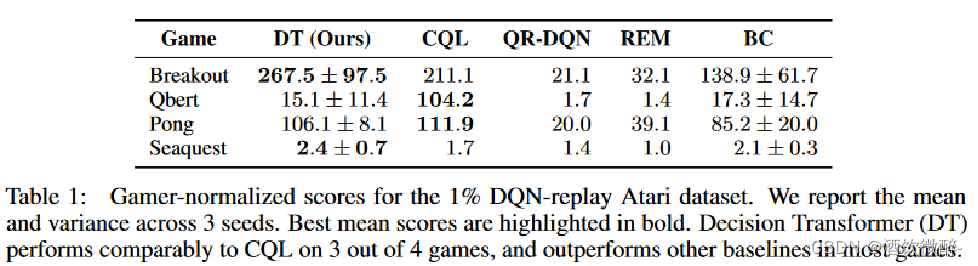
Atari
Atari基准测试具有挑战性,因为它的高维视觉输入以及由于动作和结果奖励之间的延迟而导致的信度分配困难。
作者在各个测试环境首先训练一个 DQN,再从其 回放缓冲区中随机采样 1% 的轨迹(约50万 transition)作为 offline 数据集来训练。 GPT 这类 Transformer 模型由于自注意力的计算量无法输入太长的序列,因此这里 DT 输入的长度依环境不同被限制为 50 或 30,四个环境下实验效果如下:
OpenAI Gym
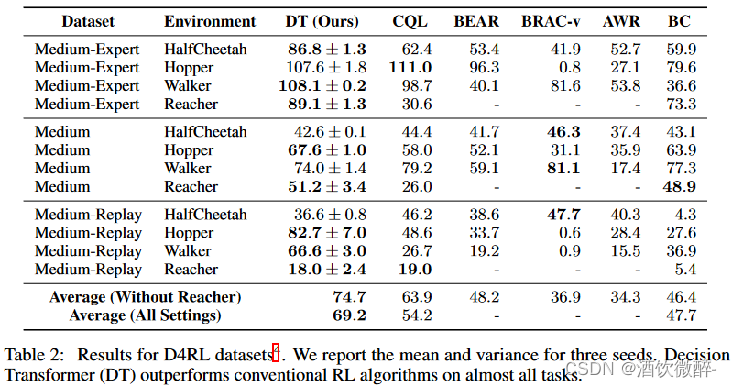
三种形式的数据集 :
① medium:大概能获得1/3专家策略分数的策略执行100w个时间步获得的数据;
② medium-replay:训练出medium策略过程中replay-buffer收集到的数据(本环境中大约为 25k-400k 时间步) ;
③ medium-expert:100w个时间步medium策略收集的数据拼接100w个时间步expert策略收集的数据。
除了 Hopper、walker 几个经典环境,还加了一个 goal-condition 的 reacher环境,使用 D4RL 数据。对比方法都是 TD learning based 方法,CQL 作为 SOTA。
结论
1.Decision Transformer在Atari、OpenAI Gym和Key-to-Door任务中的表现与现有的强大的数据集离线强化学习算法相比均呈平等或超越,证明了它在这些任务上的有效性。在长期信用分配任务中,Decision Transformer的表现优于强化学习算法。
2.Decision Transformer在扩展性和泛化方面具有优势。
四、Discussion
1.Does Decision Transformer perform behavior cloning on a subset of the data?
提出了一种新的方式,Percentile Behavior Cloning (%BC) —— 根据episode return排序,只在前X%的数据上进行模仿学习。
当数据量充足时,DT的方法在整个数据集上训练的效果可以与%BC最好的性能相提并论,这说明它在对整个数据集分布进行训练后,可以提炼出一个特定的子集。
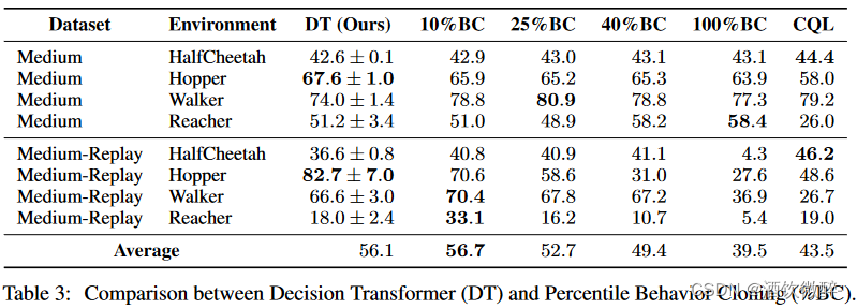
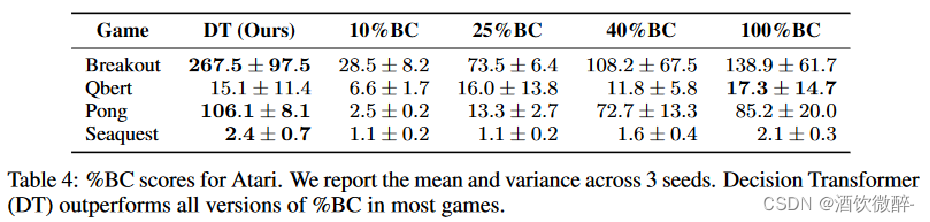
当数据量不足时,%BC很弱,在较低场景的数据集中DT能够利用全部的数据进行很好的泛化,预示了这个方法比单纯的在子数据集上进行模仿学习更优秀
2.How well does Decision Transformer model the distribution of returns?
对于不同的目标 return,agent 在评估过程中实现的平均抽样 return,每个任务上期望的目标 return 和真实观察到的 return 都是高度相关的。此外,在一些 Atria 任务上,可以用比数据集中存在的最大 return 更高的 return 条件作为初始输入传给DT,这表明 DT 有时能够外推的能力。
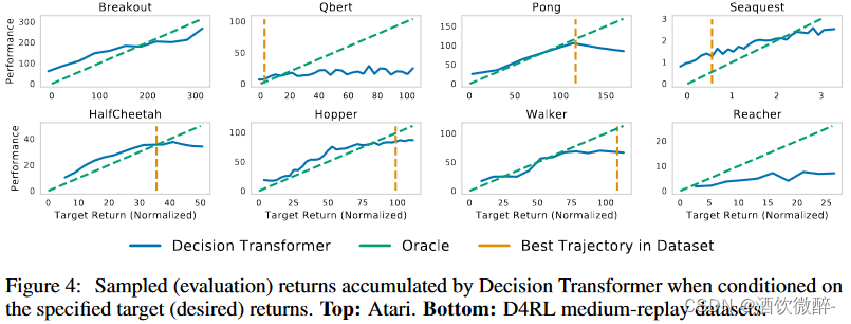
此图为在测试阶段变化期望目标return-to-go所对应的回报变化。
3.Does Decision Transformer perform effective long-term credit assignment?
通过Key-to-Door环境来评估模型处理长期credit assigment的能力,该环境由3个phase组成:
(1) 第一阶段:智能体被放在一个有钥匙的房间内; (2) 第二阶段:智能体被防止在一个空房间内; (3) 第三阶段:智能体被放置在一个有门的房间内。
要求 agent 在必须第一个房间拿到钥匙,并在带着钥匙走到第三个房间的门才能得到 binary reward,奖励非常稀疏。这个问题对于信用分配来说是困难的,因为信用必须从轨迹的开始传播到结束,跳过在中间采取的行动。作者使用随机策略生成轨迹组成 offline 数据集进行训练,并使用整个轨迹的长度作为上下文,而不是像在其他环境中那样有一个固定长度的上下文窗口。

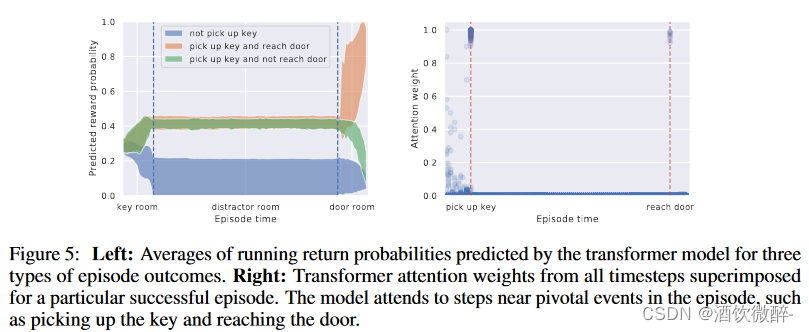
4.Can transformers be accurate critics in sparse reward settings?
这里作者还是用 Key-To-Door 这个环境来进行说明,这里 DT 经过修改,可以同时输出预测的 action 和 return-to-go。
左图所示: 蓝色线:代表未获取到钥匙,故预测产生奖励的概率极低;绿色线:代表获取到钥匙但未抵达门,在获取到钥匙后预测产生奖励的概率上升,因为最终未抵达门,故概率最后下降;红色线:代表最终抵达门,故概率预测明显上升。 右图所示,可视化了一条成功的轨迹中不同时刻attention的权重,发现在两个关键事件触发时权重较大,也再次证明了对credit assignment问题的处理能力。
5.Does Decision Transformer perform well in sparse reward settings?
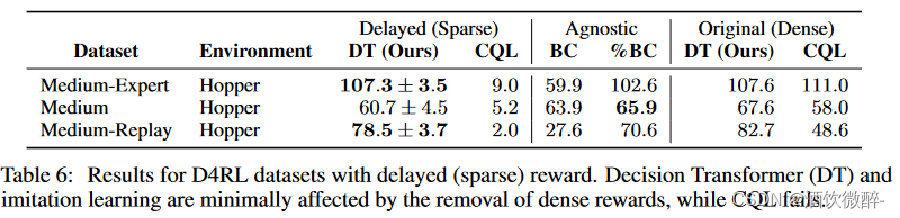
由于 DT 对 reward 密度做出了最小假设,不像 TD 类方法那样必须要稠密奖励才能良好工作。使用 D4RL 的 delay-reward 版本来验证这一点,这时轨迹中的所有 reward 都仅在轨迹结束时给出。
对具有延迟(稀疏)奖励的D4RL数据集的结果。DT 和模仿学习受去除密集奖励的影响最小,而CQL则失效。
%BC
百分位行为克隆(Percentile Behavior Cloning):根据episode return排序,只在前x%的数据上进行模仿学习。















 2212
2212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









