







今天为大家推荐一篇2021年被NeurIPS收录的一篇论文。
《Decision Transformer: reinforcement learning via sequence modeling》
推荐读者将本博客结合原论文食用。如有谬误偏颇烦请指出!
论文链接:
https://openreview.net/forum?id=a7APmM4B9d
1. 论文概览

先谈谈我的看法:在我看来,Decision Transformer与传统的RL算法最大的区别在于它训练的目标不再是为了最大化累计折扣奖励,而是学习从
,
到
的映射。为什么在训练的时候给medium级别的示例序列,而推断的时候我们调大
Decision Transformer(DT)[1]是纯监督学习,用来解决Offline Reinforcement Learning的问题。它不再将强化学习建模为马尔科夫决策过程(MDP),具体表现在网络在训练时拿到了非常long-term的信息,完全不符合马尔科夫性了。
具体而言,DT将RL当作一个自回归的序列建模问题,建模回报序列(return-to-go)、状态序列(state)与动作序列(action)之间的关系。与一般认为的行为克隆(behavior cloning)只建模状态和动作关系相比,额外考虑了回报以及过去的三元组(,
,
)序列。最后的效果非常好,击败了一众当时顶尖的离线强化学习方法。
2. 具体做法
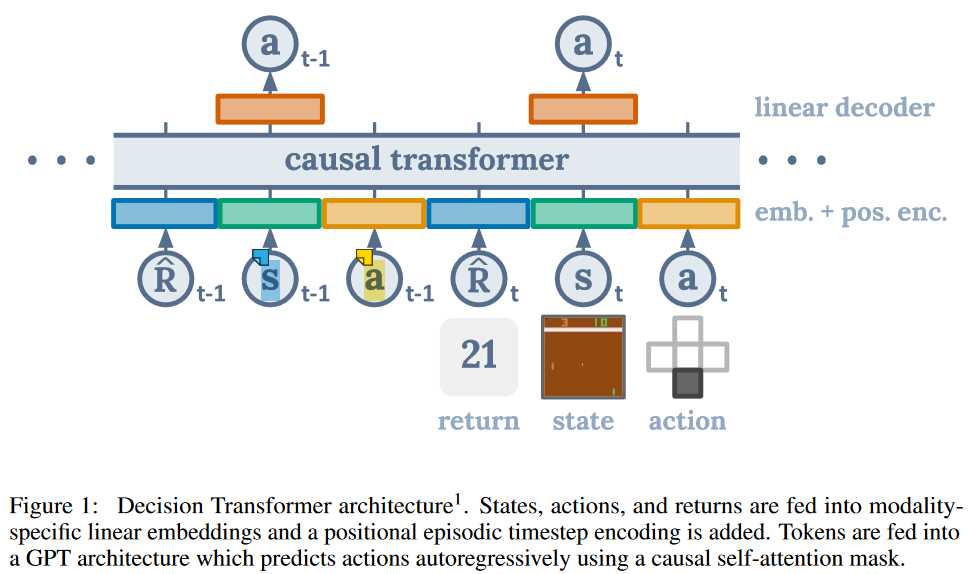
如Figure 1所示,
网络输入是
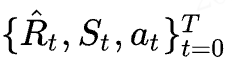
输出是

,是以自回归(autoregression)的方式生成动作。网络结构可以认为是Transformer[2] 的 Decoder 部分的修改(GPT),主要是masked multi-head self-attention。
2.1 网络输入
先从训练的时候讲起,如大家所知,基于时序差分算法的强化学习方法输入通常是四元组:来完成一次更新。
而DT是以一条序列(trajectory)作为输入的:
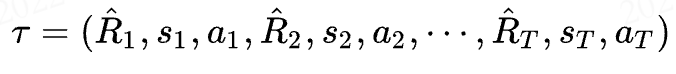
代表游戏从开始到结束的一整条序列,但是在实际训练过程中,我们往往只会截取K个时间步作为输入,这一点之后再说。
其中需要额外注意的是,和以往r代表奖励(reward)不同,这里作者采用的是 returns-to-go:
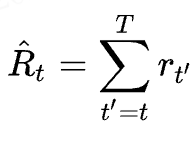
即从当前时刻开始,到这条序列结束的所有奖励 reward 的和,且没有折扣(折扣系数)。
为啥这样做呢?
这是因为,DT的目标是基于未来希望得到的回报来生成当前的动作,所以用 reward当然过于短视了,因为rewa
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 151
151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









