







 需要的工具
需要的工具
- fiddler
-
python 3.8
第一步——抓包
由于之前我在大学的时候就有用python写脚本抢图书馆座位的经验,所以大概了解这种公共预约平台,其实就一个get或者post请求就能搞定拉。
所以用fiddler抓一下预约的api就好。
你问我为啥不用F12?见下图

所以接下来在微信PC端先手动预约成功一下,然后到fiddler中就可以找到api了。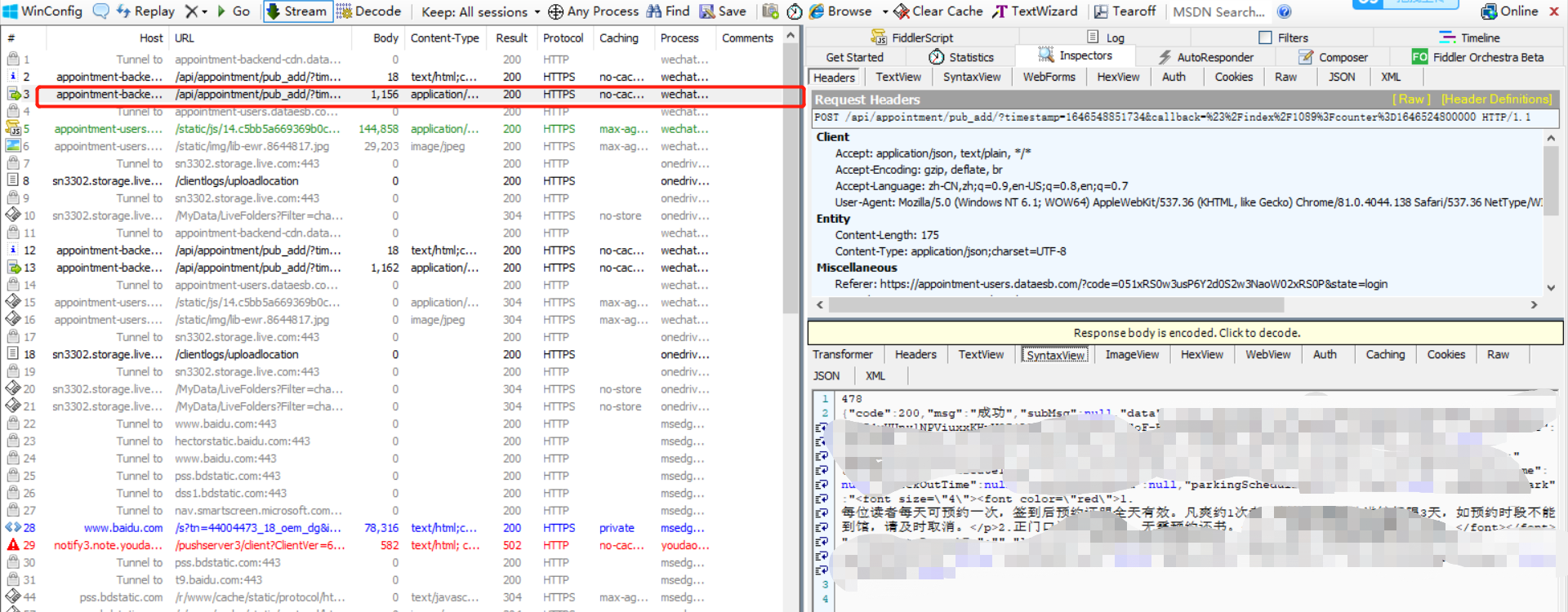
这其中我碰到的坑
报错:只能用微信客户端打开
这个还是比较容易解决的,只要将header中的 "User-Agent" 改成fiddler 中的样子就OK了。
服务器持续返回405
一开始百度,说是将post方式改成get方式。我试了一下不行,而且fiddler提交方式也是post。
后面再百度,说可能是这个链接就不支持post方式。
我一想是不是api搞错了,去fiddler一看,果然我复制粘贴少了,赶紧改了,果然服务器返回200,访问成功。
服务器返回未知错误
这个可就哭死我了,看到200本来乐了一下,结果对方服务器居然不认。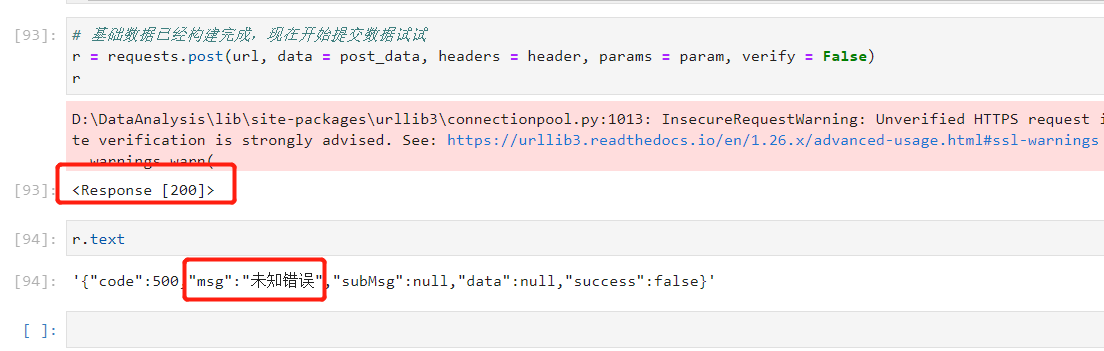
解体思路: 这种情况一般都是服务器看了你提交的信息,然后说:”滚,我看不懂。“这时候看看是不是数据漏了什么,或者格式是不是有问题。
按照这个思路检查代码,果然提交的时候格式不匹配。
我用python提交的是dict类型,但是服务器只认json。
将dict转成json后,果然预约成功了!
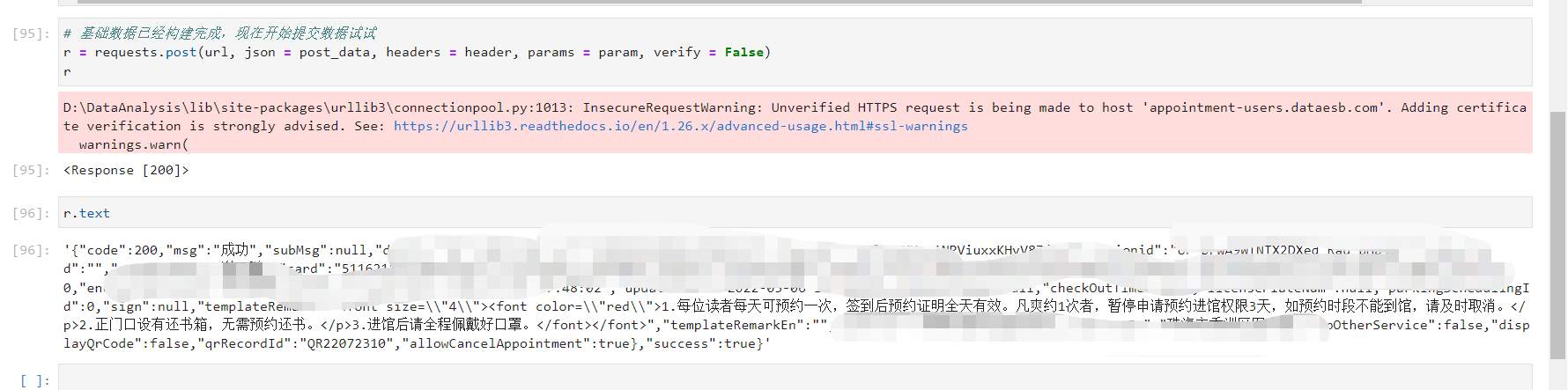
附上代码
import requests
import time
import json
# 先创建url 和 headers,然后直接request看行不行。
url = 'https://appointment-users.dataesb.com/api/appointment/pub_add/'
header = {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36 NetType/WIFI MicroMessenger/7.0.20.1781(0x6700143B) WindowsWechat(0x6305002e)",
"Referer": "https://appointment-users.dataesb.com/",
"unionid": "oF-BrwA9WTNTX2DXed_Rad_pHp4g",
"Content-Length" : "175",
"Content-Type": "application/json;charset=UTF-8",
"Origin": "https://appointment-users.dataesb.com" ,
"Sec-Fetch-Dest" : "empty" ,
"Sec-Fetch-Mode" : "cors" ,
"Sec-Fetch-Site" : "same-site" ,
"Connection": "keep-alive" ,
"Host": "appointment-backend-cdn.dataesb.com"
}
post_data = {"subLibId":"1089",
"scheduleId":1268766,
"children":0,
"card":"",
"cardType":"IDCARD",
"name":"",
"phone":"",
"childrenConfig":False,
"code":""}
time_str_13 = int(float(time.time()) * 1000) #创建时间戳
param = {
"timestamp" : time_str_13,
"callback" : "#/index/1089?counter=1646524800000"
}
# 然后这样执行就好啦
r = requests.post(url, json = post_data, headers = header, params = param, verify = False)


















 2511
2511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









