









主要内容:
1. 不同存储介质下的存算一体技术:
SRAM: 计算精度高,但存储密度低,静态电流大。
eDRAM: 存储密度高,但计算吞吐量低。
Flash: 支持多bit存储,但工艺微缩困难,读取速度慢。
RRAM/PCM/MRAM: 与CMOS工艺兼容,适合端测和边缘计算,但大规模应用依赖于器件工艺提升。
2. 不同计算信号类型下的存算一体技术:
数字域: 计算精度高,但难以实现高算力。
电流域: 算力密度和存储密度高,但计算精度低。
电荷域: 计算精度相对较高,但存储密度受电容限制。
时域: 信号裕度大,但存储单元结构复杂,降低存储密度。
3. 存算一体技术的主要评价指标:
算力、能量效率、面积效率、算力密度、存储密度
发展趋势: 算力和能量效率近年来呈快速上升趋势。
综合评价指标: 能效和存储密度的乘积、能效和算力密度的乘积、考虑输入输出数据精度的指标。
4. 存算一体技术面临的主要挑战:
读扰乱问题
权重单元密度有限
计算电路开销大
多bit计算实现开销大
计算精度受工艺波动影响大
多核芯片高效流水实现困难
软件工具链需进一步优化
总结:
存算一体技术在边缘端和云端AI计算领域具有巨大潜力,但仍面临诸多挑战。未来需要跨层次协同研究,提升器件工艺、电路、架构和软件工具链,才能实现更强大高效的算力。
冯诺依曼计算机体系结构面临着“存储墙”的瓶颈,阻碍AI(Artificial Intelligence)计算性能提升。存算一体硬件结构打破了“存储墙”的限制,大大提升了AI计算的性能。本文对现有的存算一体方案的进行了对比分析,指出了每一种方案的主要优缺点,也指明了存算一体技术面临的挑战。
本文从存储介质及计算信号类型两个大的维度对比分析了几种存算一体方案,分析了存算一体方案目前的一些性能指标,并列举了存算一体技术面临的主要挑战,具体如下:
1:不同存储介质下的存算一体技术的典型实现方式和优缺点
1)SRAM存算一体技术具有高的计算精度,却具有低的存储密度以及大的静态电流。
2)eDRAM存算一体技术一般具有高的存储密度。然而,eDRAM存算一体计算具有低的计算吞吐。
3)Flash存算一体技术支持多bit存储,但工艺微缩面临困难,且读取速度慢。
4)RRAM、PCM、MRAM器件的存算一体方案与CMOS工艺兼容,在端测和边缘计算场景具有很大的潜力,然而大规模应用的实现还依赖于器件工艺水平进一步提升。
具体对比见下表:
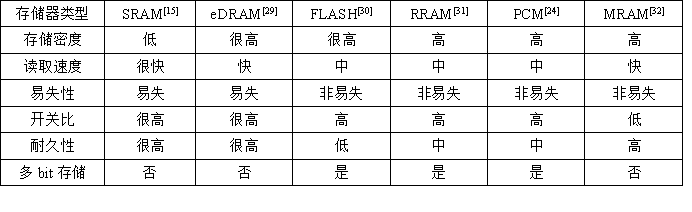
表1 存储器件特性对比
2:不同计算信号类型下的存算一体技术的计算原理和优缺点
1)数字域的存算一体方案可以取得高精度的计算结果,然而难以实现高的算力。
2)电流域的存算一体方案易于实现高的算力密度和存储密度,但计算精度偏低。
3)电荷域的存算一体方案的计算精度相对较高,然而对电容的依赖降低了存储密度。
4)时域的计算信号有更大的信号裕度,但是复杂的存储单元结构同样降低了存储密度。
具体对比见下表:
表2 不同信号域的各个指标对比(具体方案的指标可能根据优化方式的不同有所区别)

3:目前存算一体技术的主要评价指标
本文主要介绍了存算一体技术的主要评价指标,如算力、能量效率、面积效率、算力密度、存储密度。并重点分析了算力、能量效率近年来的发展趋势,如图1、2所示,可以看到算力和能量效率呈现快速上升的态势。
图 1 存算一体算力发展趋势
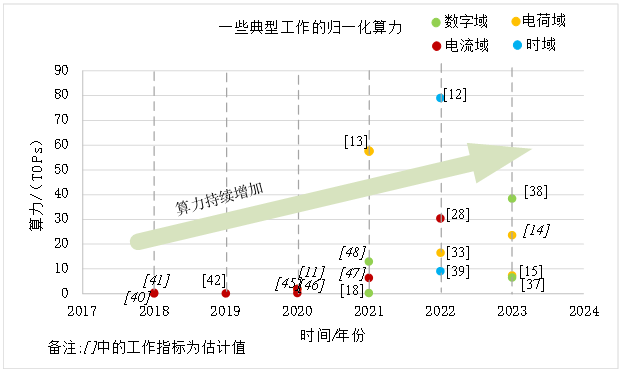
图2 存算一体能效发展趋势
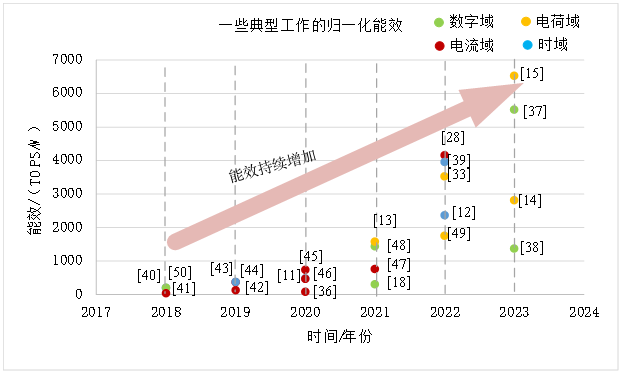
此外,本文还介绍了一些近年出现的综合评价指标,如北京大学黄如教授等提出可以用能效和存储密度的乘积来对芯片进行综合评价。同时,黄如等提出可以用能效和算力密度的乘积对芯片的综合性能进行评价。张孟凡等提出了一些将输入输出数据精度考虑在内的评价指标,以强调计算数据的精度在计算综合性能评估上的重要性。由于不同的应用场景对芯片有不同的性能需求,性能的优化方向也会有所不同,从而产生了不同的评价指标。
4:存算一体技术面临的主要挑战
本文分析了目前存算一体技术面临的7个挑战,包括读扰乱问题、权重单元密度有限、计算电路开销大、多bit计算实现的开销大、计算精度受工艺波动影响大、多核芯片高效流水实现困难、软件工具链还需进一步优化。
尽管如此,随着工艺集成、器件、电路、架构,软件工具链的跨层次协同研究发展,存算一体技术将在边缘端和云端,为AI计算提供更加强大和高效的算力。

















 1830
1830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









