








一.数据加载规则介绍(Load rules)
在 apache druid 中,Coordinator 进程使用规则来确定应该将哪些数据加载到集群或从集群中删除。 规则用于数据保留和查询执行,并在协调器控制台( http://coordinator_ip:port 控制台)上设置。
有三种类型的规则,即加载规则、删除规则和广播规则。
加载规则指出应该如何将段分配给不同的历史进程层,以及每个层中应该有多少段的副本。 删除规则指示何时应该完全从集群中删除段。 最后,广播规则指出不同数据源的片段在历史过程中应该如何共存。
加载规则指示一个段的副本在一个服务器层中应该存在多少个。 请注意: 如果 Load 规则仅用于保留某个时间间隔或时间段的数据,则必须附带一个删除规则。 如果不包含删除规则,则默认规则(loadForever)将保留不在指定间隔或周期内的数据。
-----------------以上是摘自 druid.apache.org官网上,对于数据加载规则的简单介绍的翻译。
二.首先需明确的是一下内容:
1.druid中常用的几种时间跨度表示方法:
- second:秒粒度 PT1S
- minute:分钟粒度PT1M
- hour:小时粒度PT1H
- day:天粒度P1D
- week:周粒度P1W
- month:月粒度P1M
- quarter: 一个季度粒度 P3M
- year:年粒度 P1Y
以上是个数量为1的各粒度的表示方法;如1天,在druid中可以表示“P1D”;
三.直接演示
1.登录http://ip:8888/管理界面;(注意:本人的版本是Apache Druid 0.17.0)
2.打开DataSource;
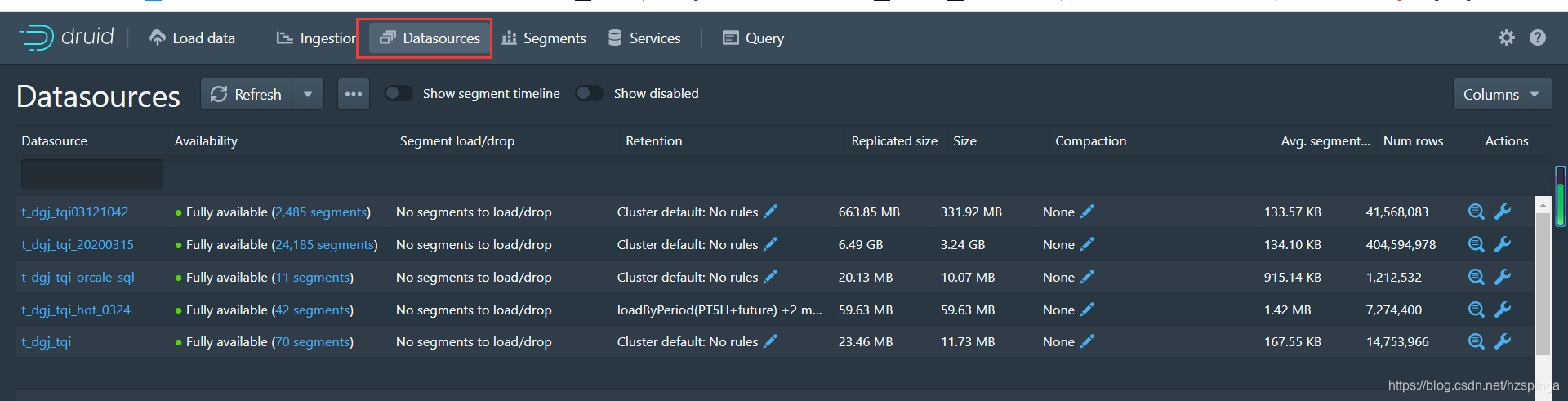
3.双击DataSource对应的Retentionde列(后者点击![]() )编辑规则(Edit retention rules),我的规则如下:
)编辑规则(Edit retention rules),我的规则如下:
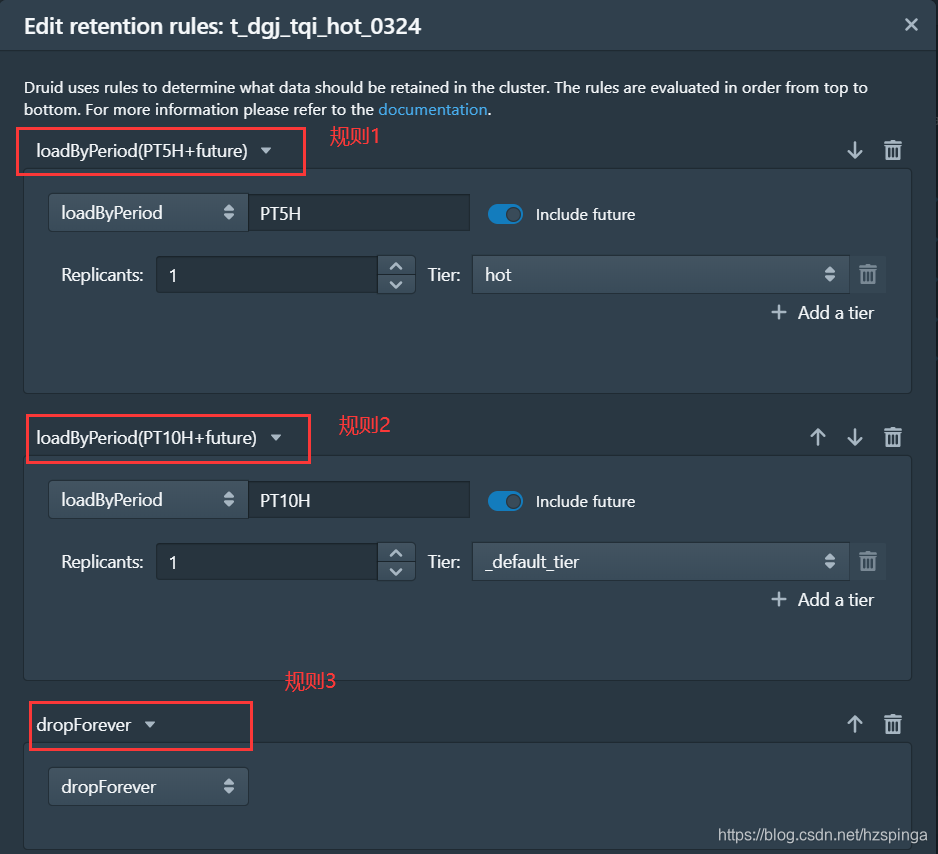
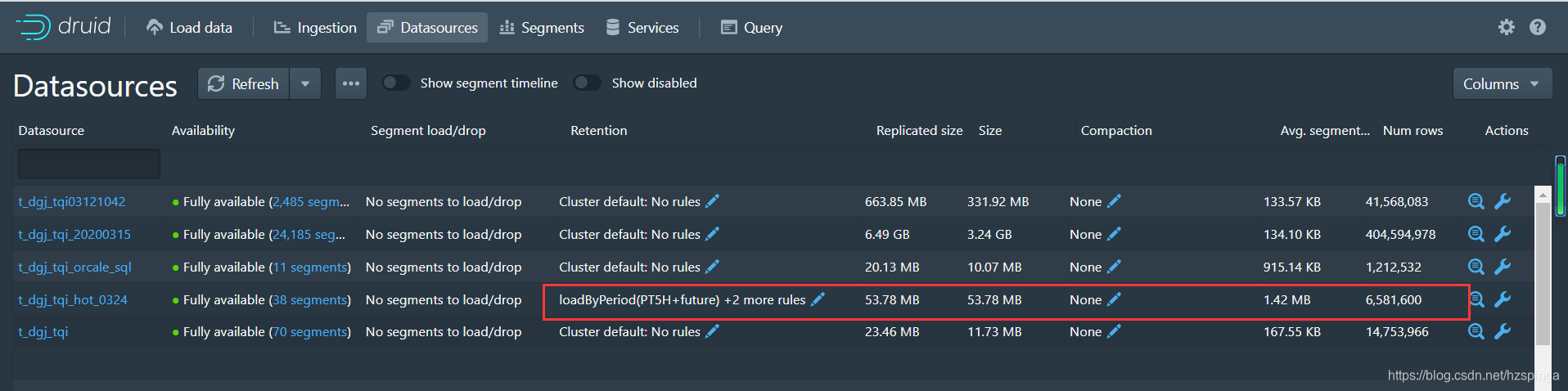
解释:规则1:只保留最近五个小时的数据,Replicants为1,说明这个数据我只保存一份,Tier我设置为“hot”,我是作为我的“热”数据,这里面的“hot”是我自己添加设置的;
规则2:保留最近10个小时的数据,但上面“规则1”把前5个小时的数据放在得了“hot”中,这里最近10个小时已近去除了这个5个小时,换言之,就是规则2指的就是后5个小时;这里Replicants为1,也是这样的数据我只保存一份,Tier我设置为“_default_tier”就是“冷”数据了;
规则3:除了规则1和格则2的数据,删除其余的数据;意思是我的Historical中只保留10个小时的数据,当然上面是我做测试配置的规则,实际根据自己的需求调整;需要注意的是,这里的删除,只是删掉了druid中本地缓存的数据,只是逻辑删除,Deep Storage中的数据并没有删掉,所以当你删除规则3的时候,数据又会加载回来,当然,上面的规则也需要做相应的调整;
注意:1.以上的顺序,规则是从上往下依次执行的,要是把规则3放在第一个,那会删掉druid中的所有的数据;
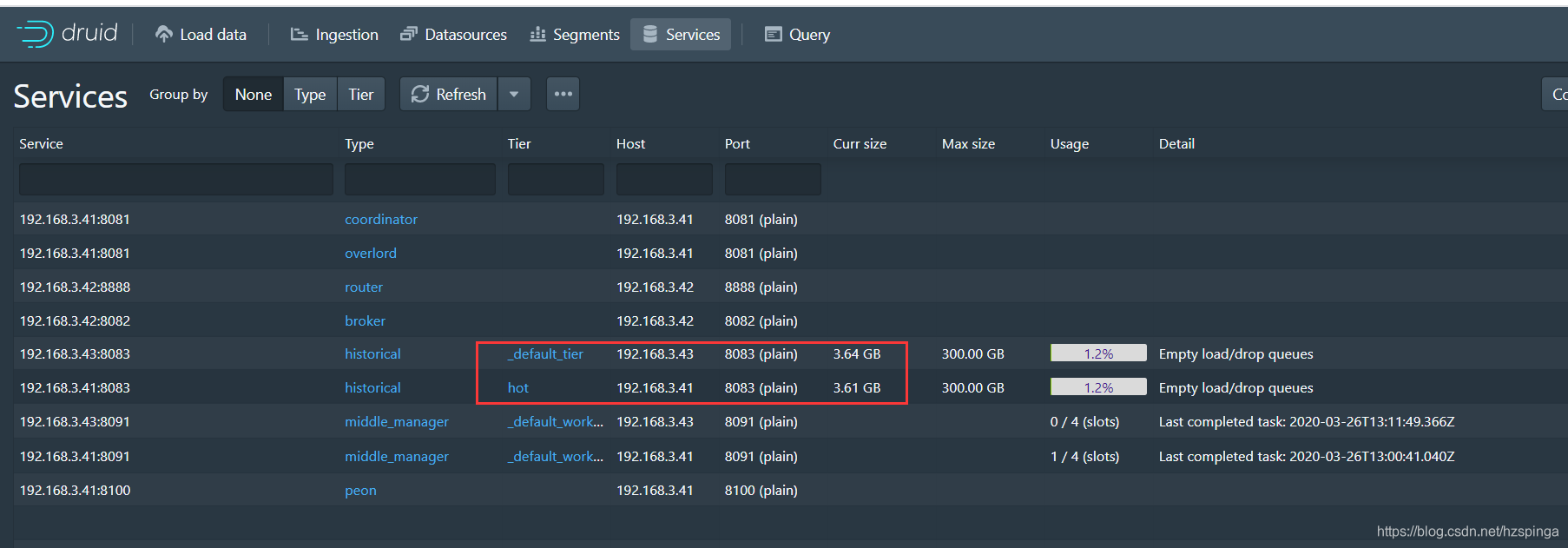
2.我本地的配置是![]() ,2个historicals,一个我设置为“hot”,一个没改配置,是默认的;“hot”的配置是(下图),不过一般的小集群,historicals节点太少的话,没必要这样设置;
,2个historicals,一个我设置为“hot”,一个没改配置,是默认的;“hot”的配置是(下图),不过一般的小集群,historicals节点太少的话,没必要这样设置;
vim /druid/conf/druid/cluster/data/historical/runtime.properties
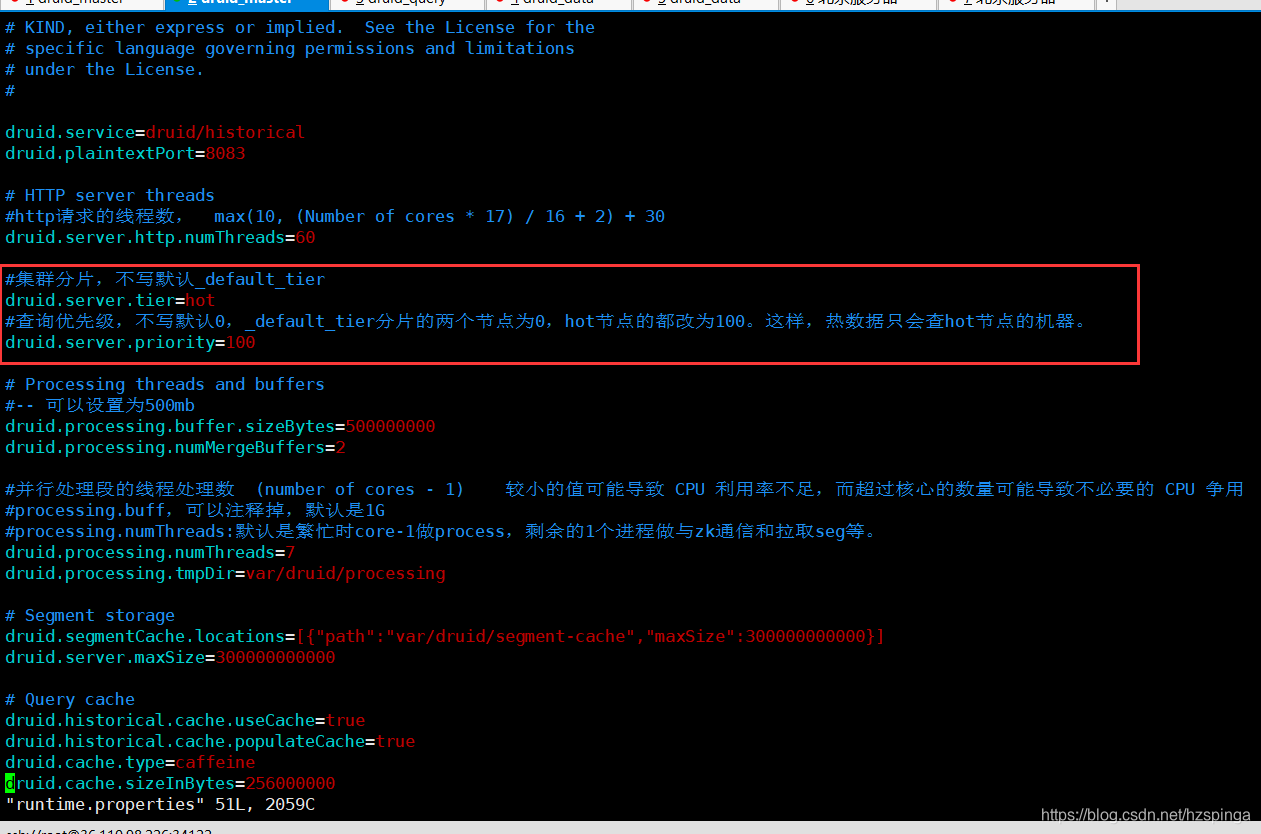
3.关于"includeFuture":记得要选,意思是包含未来,就是一直加载的当前时间的最近X个小时;
4.怎么看上面的配置生效了那?
(1)看size,配置后这个数据会有很明显的变化,而且我因为是配置的一份副本,所以Replicated和size是一样的;配置前后的“Num rows”也会有变现的变化的;
(2)整个“curr size”也会有明显的变化;
5.如果不配置上面规则的话,默认副本的数量是和集群中historicals的数量是一致的;

以上内容是本人结合官网内容,自己研究的,如有错误之处请包涵,欢迎一起来讨论学习。
参考网址:https://druid.apache.org/docs/0.17.0/tutorials/tutorial-retention.html#load-the-example-data

















 836
836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









