







 本文详细介绍了如何解决MySQL中使用LIKE '%str%'导致索引失效的问题,提供了包括选择主键查询、应用覆盖索引、使用全文索引以及利用全文检索引擎工具在内的四种解决方案,对于大数据量表的高效模糊查询具有指导意义。
本文详细介绍了如何解决MySQL中使用LIKE '%str%'导致索引失效的问题,提供了包括选择主键查询、应用覆盖索引、使用全文索引以及利用全文检索引擎工具在内的四种解决方案,对于大数据量表的高效模糊查询具有指导意义。
三、 索引
7. 解决like’%str’不使用模糊查询的4种方法
上一讲最后说了,只要模糊查询的模糊值在字符串前面,则不会使用索引,‘%aaa’和‘_aaa’都不会!
如下
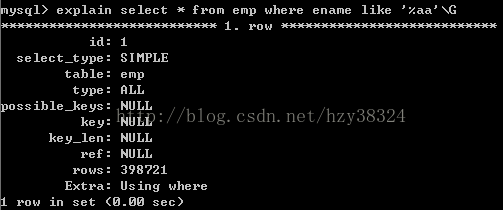
应该说这是Mysql给程序员们开的一个玩笑。要是我的表数据量很大,而且又需要使用like’%%’这样的模糊查询来检索时,该怎么办??
接下来,笔者将会给大家分享解决这个问题的四种方法!
1) Select主键
只要Select的字段刚好是主键,那么就会使用到索引(只对innodb数据库有效)
比如下面的
7. 解决like’%str’不使用模糊查询的4种方法
上一讲最后说了,只要模糊查询的模糊值在字符串前面,则不会使用索引,‘%aaa’和‘_aaa’都不会!
如下
应该说这是Mysql给程序员们开的一个玩笑。要是我的表数据量很大,而且又需要使用like’%%’这样的模糊查询来检索时,该怎么办??
接下来,笔者将会给大家分享解决这个问题的四种方法!
1) Select主键
只要Select的字段刚好是主键,那么就会使用到索引(只对innodb数据库有效)
比如下面的

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 777
777





