






特征过程
特征提取
将数据中的特征向量提取出来
特征预处理
数据集的特征有很多,因目的不同,有的特征对模型的影响重要,而有的就微乎其微了
特征降维
对数据进行精炼,去除一些不重要的信息,从而减少数据的复杂度,更加清晰的看到数据之间的特征,可以更加有效的进行建模
特征选择
数据中的特征有很多,而我们建模是有目的性的,只需要找出我们所需要的数据的特征进行筛选,对模型训练相关的只是这众多特征的一部小部分特征
特征组合
将上述找到的特征通过加法或者乘法组合起来形成一个特征
拟合
过拟合-----数据在训练集上很好,测试集上很差
欠拟合-----数据在训练集和测试集上都差
KNN算法
KNN算法(K Nearest Neighbor)也叫近邻算法,即越近越相似
常用来解决分类问题,回归问题
K值的选择
不宜过大也不宜过小,过大则会过拟合,过小则会欠拟合,需要反复调整寻找一个中间量
KNN的算法实现(python版)
KNN分类算法
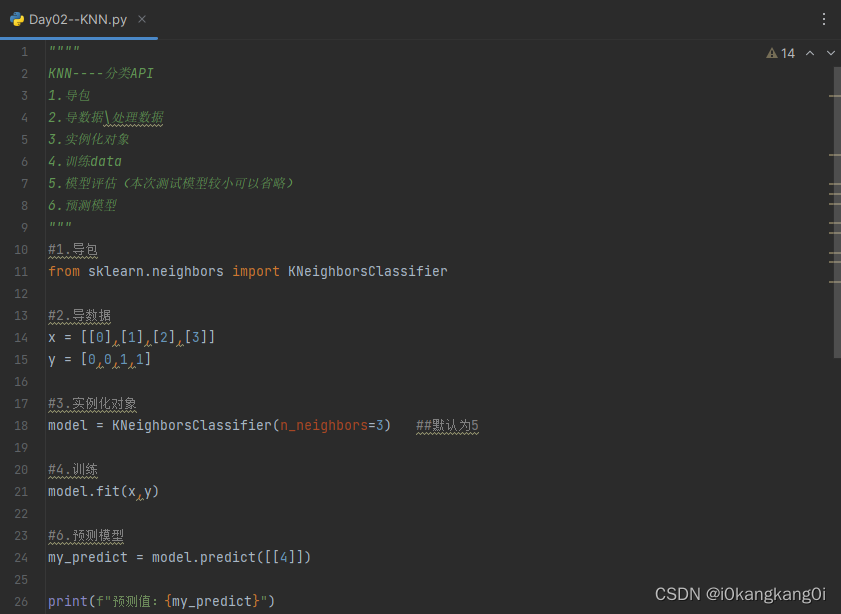
对[[4]]数据通过KNN分类算法进行预测得到结果为:预测值为[1]
 算法实例讲解
算法实例讲解
对于预测数据[[4]],模型找到最接近的3个邻居样本是[2]、[3]和[1],对应的类别分别是1、1和0。在这种情况下,模型采用多数投票的方式,选择邻居样本中出现最多的类别作为预测结果。类别为1的样本出现的次数最多,所以预测结果为1。
KNN回归算法
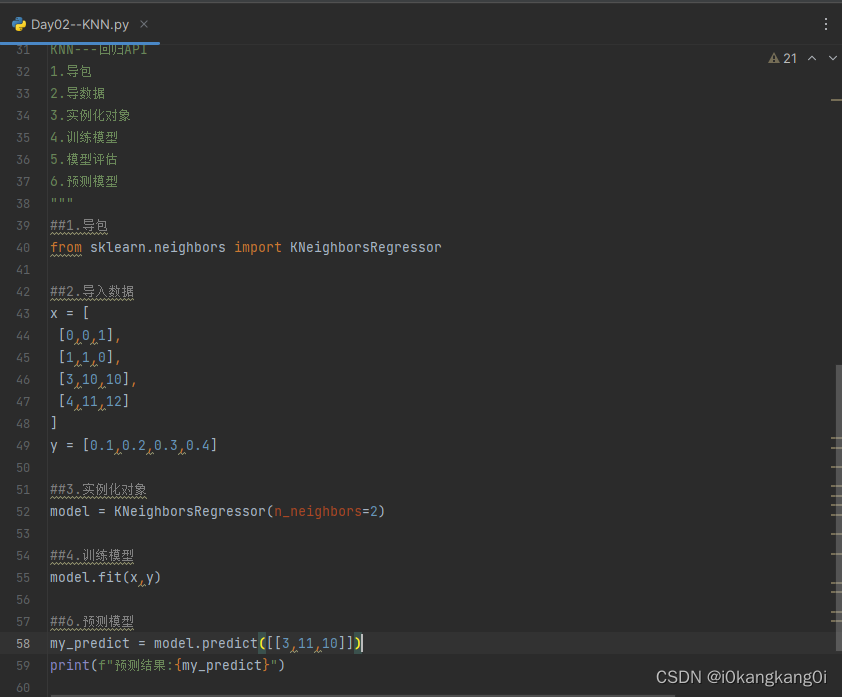
对数据[[3,11,10]]通过KNN回归算法进行预测结果为[0.35]

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









